Diff: jak číst výstup z porovnání souborů
Občas se potkávám s tím, že někdo narazí na výstup příkazu diff a neví si s ním rady. Pokud je to váš případ, nabízím malého průvodce.
Diff je velmi starý unixový příkaz, který dokáže porovnat dva soubory a vypsat rozdíly mezi nimi. Obvykle se používá k porovnání dvou verzí jednoho souboru a vytvoření patche – tedy malého souboru popisujícího rozdíly řádek po řádku.
Takto vytvořený patch je pak možné třeba zaslat autorovi původní verze souboru, který může změny prohlédnout a případně patch aplikovat. Tím získá verzi souboru včetně všech úprav. Všichni programátoři a/nebo uživatele Gitu (či jiného verzovacího nástroje) tenhle postup dobře znají.
Ovšem to není zdaleka jediný způsob, jak Diff použít. Můžete s ním třeba sledovat měny nějakého stavu. Řekněme, že každou hodinu sledujete nějaké parametry, které se obvykle nemění. Třeba stáhnete z internetu seznam balíčků v nějakém repozitáři a chcete být informováni o změně. Stačí si uložit na disk poslední stav a při dalším stahování pak oba seznamy porovnat pomocí diff. Pokud se objeví změna, výstup diffu bude nenulový a třeba Cron vám jej pak automaticky zašle mailem.
Stává se, že se takový výstup dostane do rukou neznalému uživateli, který na to kouká a na první pohled z toho není moc moudrý. I když je poučen o tom, že se kouká na popis změn, bez zevrubného vysvětlení mu obvykle není vůbec jasné, jak má obsah interpretovat.
Čtyři varianty výstupu
Aby to nebylo jednoduché, existují čtyři různé způsoby zápisu diffu. Podle stáří to jsou:
- normal (výchozí)
- edit (ed) (parametr
-e) - context (parametr
-c) - unified (parametr
-u)
Nejčastěji se dnes používá poslední zmíněný, řada projektů i aplikací jej dokonce vyžaduje. Většina implementací příkazu diff (včetně toho v GNU) ale obsahuje podporu všech čtyř. Setkat se s nimi můžete i v reálném světě, proto si je popíšeme všechny.
Jejich princip je ovšem podobný. Diff vždycky najde co největší množinu shodných řádků a pak si zapíše, které řádky bylo třeba přidat, smazat nebo změnit, aby vznikl nový soubor.
Soubory s příklady
Pro ukázku si vytvoříme dva soubory: prvni.txt a druhy.txt. Budou velmi jednoduché:
První:
Kočka leze dírou, pes oknem, nebudeli pršet, nezmoknem.
Druhý:
Básnička o kočce Kočka leze dírou, pes oknem, nebude-li pršet, nezmoknem. A když bude pršet, zmokneme, na sluníčku zase uschneme.
Vidíte, že jsme v souboru udělali tři změny: připsali jsme na začátek řádek, opravili jsme chybu (nebude-li) a připsali sloku na konec. Diff získáme prostým zápisem, který můžeme doplnit o parametry:
$ diff prvni.txt druhy.txt
Výchozí formát
Bez dalších parametrů nám diff vysype tento klasický formát. Výstup z našeho příkladu bude vypadat následovně:
0a1,2 > Básnička o kočce > 3c5 nebude-li pršet, 4a7,9 > A když bude pršet, > zmokneme, > na sluníčku zase uschneme.
Písmenko v řídící sekvenci znamená přidat (add), smazat (delete) nebo změnit (change). Číslo nebo čísla před písmenem znamená pořadí řádku(ů) v původním souboru, čísla za písmenem pak značí pořadí v druhém souboru. Většítko a menšítko na začátku řádku s obsahem značí, do kterého ze souborů musí být řádek v případě rekonstrukce přidán.
Edit formát (-e)
Tento formát odpovídá vstupu řádkového editoru Ed (z něj vychází i Sed). Výstup bude vypadat takto:
4a A když bude pršet, zmokneme, na sluníčku zase uschneme. . 3c nebude-li pršet, . 0a Básnička o kočce .
Tento formát je ještě jednodušší, protože příkaz vždy určuje číslo řádku a opět akci, kterou budeme konat: přidat (add), smazat (delete) nebo změnit (change). Tečka vyskakuje z editačního režimu a po ní editor očekává další příkaz. Tady tedy slouží jako přirozený oddělovač jednotlivých sekvencí.
Všimněte si, že diff je vlastně vytvořený pozpátku. To je elegantní způsob, jak se nezabývat posunem řádků mezi soubory. K posunu dochází postupně a jsou jím ovlivňovány nižší oblasti, které už diff měnit nebude.
Context (-c)
V kontextovém režimu se změněný řádek (řádky) objevuje vždy s nezměněnými řádky okolo. Tím je zachován onen kontext – kde v souboru ke změně došlo. Není proto potřeba zapisovat pořadí řádků, protože je vždy možné najít v souboru správné místo změny. Navíc je díky tomu tento formát velmi dobře čitelný pro člověka.
Počet „kontextových řádků“ nad a pod změnou může být nastaven, obvykle se používají tři. Pokud se tyto řádky překrývají, diff je chytře překryje a neduplikuje je. Protože je náš příklad krátký, objeví se ve výstupu nakonec celý, protože změny jsou velmi blízko u sebe.
*** prvni.txt 2014-02-19 14:21:56.494657890 +0100 --- druhy.txt 2014-02-19 14:22:04.054724672 +0100 *************** *** 1,4 **** Kočka leze dírou, pes oknem, ! nebudeli pršet, nezmoknem. --- 1,9 ---- + Básnička o kočce + Kočka leze dírou, pes oknem, ! nebude-li pršet, nezmoknem. + A když bude pršet, + zmokneme, + na sluníčku zase uschneme.
Na začátku celého patche je vidět cesta k souborům a časová značka. Pak následují jednotlivé editační oblasti, které jsou uvozeny hvězdičkami u prvního souboru a pomlčkami u druhého. Čísla značí rozsah řádků v tom kterém souboru. Vykřičník na začátku řádku označuje změnu, plus přidání řádků a mínus odebrání. Řádky bez značky jsou kontextové a nemění se.
Unified (-u)
Dnes jednoznačně nejpoužívanější formát, na který narazíte nejčastěji. Je vylepšením předchozího (kontextového) formátu a jeho výhodou je kratší výstup. Změny v obou souborech jsou totiž zapisovány dohromady.
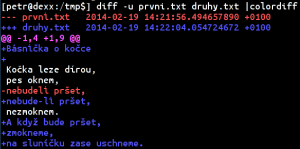
--- prvni.txt 2014-02-19 14:21:56.494657890 +0100 +++ druhy.txt 2014-02-19 14:22:04.054724672 +0100 @@ -1,4 +1,9 @@ +Básnička o kočce + Kočka leze dírou, pes oknem, -nebudeli pršet, +nebude-li pršet, nezmoknem. +A když bude pršet, +zmokneme, +na sluníčku zase uschneme.
Začátek opět popisuje název a časovou značku souboru, ale pro označení souboru se používají znaky plus a mínus. Následuje jedna či více oblastí popisujících změny, tato oblast vždy začíná dvěma zavináči. Mínus označuje informace o řádcích v prvním souboru, plus ve druhém. Čísla pak označují první řádek změny a počet řádků (pozor!), na které se změny vztahují. Někdy se druhá hodnota vynechává, protože je odvoditelná ze zbytku obsahu.
Počet změněných řádků původního souboru (v našem příkladu čtyři) odpovídá součtu kontextových řádků a odstraněných řádků (s mínusem). Počet změněných řádků nového souboru (v našem příkladu devět) zase odpovídá součtu kontextových řádků a přidaných řádků. Spočítejte si to. Pokud by tomu tak nebylo, byl by patch považován za vadný.
Unified nepoužívá žádný znak pro změnu, ta se provádí jednoduše odebráním a přidáním řádku. Proto jsou tyto změny pěkně pohromadě a soubor je přehledný.
Doporučuji si příklady projít a zahrát si na příkaz patch, který popisovaný výstup diffu aplikuje.
Ještě tip na závěr: abyste se v tom hezky vyznali, zkuste příkaz colordiff. Ten vám výstup pěkně obarví.
{kind=link}
-
Související články na blogu Petr Krčmář: blog nejen o Linuxu
-
Práva na sockety u PHP-FPM 2. 6. 2014 14:27
-
Generujeme pěknou uvítací hlášku (MOTD) 13. 3. 2014 14:42
-
Přehození běžícího procesu pod tmux/screen 19. 11. 2013 9:38
-
„Je lepší Windows nebo Linux?“ je špatná otázka 17. 5. 2013 0:03
-
Přeinstalace Debianu se zachováním balíčků 21. 1. 2013 23:00
-
Restart sítě v Debianu: jak správně na to 19. 11. 2012 22:27
-
-
Související články na ostatních blozích
-
Stav OSS projektů v roce 2025 5. 8. 2025 14:39
-
ZABBIX a neočekávaný nárůst velikosti databáze 4. 9. 2023 12:20
-
Recenze: Chromebook Education 11 3189 2-in-1 (2017) 30. 12. 2018 1:37
-
Ebook: Ze života správce linuxových serverů 29. 5. 2018 7:44
-
Co se mi osvědčilo v roce 2017 31. 12. 2017 13:45
-
Bitwig Studio - skládejte a produkujte hudbu v Linuxu profesionálně 14. 7. 2017 17:25
-
-
Související články na serveru Root.cz
-
Postřehy z bezpečnosti: léto plné duchů – Ghost phishing, GhostLock, GhostApproval Včera 0:00
-
Tuxedo OS přechází na Debian Testing, Astral portuje Wine Včera 0:00
-
Linux 7.3 přinese barevné formáty pro AMDGPU i konec souborového systému, který v 21. století nejspíš nikdo nepoužil 10. 7. 2026 0:00
-
COSMIC má nový monitor systému, Xfce testuje běh na Waylandu 8. 7. 2026 0:00
-
Obnova po resetu GPU v GNOME, nahrávání 4k/60p videa přes USB 5. 7. 2026 0:00
-
Postřehy z bezpečnosti: malware klame analytické AI nástroje 29. 6. 2026 0:00
-
-
kolujpoqwe (neregistrovaný)
Nie je nutné inštalovať ďalší program na zvýrazňovanie syntaxe. Pokiaľ používate vim, stačí ho spustiť v režime read-only a máte "zadarmo" zvýrazňovanie syntaxe aj pohyb v dokumente:
diff -u prvni.txt druhy.txt | view -
prípadne ak nemáte nastavený "view" ako read-only vim, tak rovno:
diff -u prvni.txt druhy.txt | vim -
-
andrej (neregistrovaný)
ked uz graficky tak multiplatformny http://meldmerge.org/ - vie robit aj diff adresarov.
