OCR v linuxu II - co dnes opravdu můžeme používat
Přemýšlel jsem, jestli nové zkušenosti, které jsem získal z podnětné diskuze pod textem OCR v linuxu nebude lepší přidat jako další odstavec do zmíněného textu. Ale pak jsem se rozhodl se trochu rozepsat i s návodem k instalaci.
UPDATE: Novější informace o OCR najdete v tomto článku.
Hledáme-li pohodlný program pro slušené skenování textu, můžeme si podle mě vybrat ze čtyř možností.
1. gscan2pdf

Jde o program, využívající gocr, případně Tesseract (ten ovšem zatím nepodporuje češtinu, což je škoda, je totiž úspěšnější). Používá prostředí GTK a SANE, dobřše detekuje skener, má řadu možností v nastavení a umí hromadné OCR více stran. Instalace je snadná, program je v repozitáři (zkoušel jsem v Ubuntu):
sudo apt-get install gscan2pdf
Výhodou je snadná instalace, možnosti nastavení, přehledné prostředí. Nevýhodou je pro Čechy i Slováky absence těchto jazyků pro Tesseract, gocr má podle mě mnohem horší výsledky.
2. YAGF
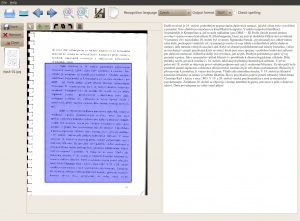
Jde o QT4 nadstavbu programu Cuneiform (ten lze samozřejmě používat i v terminálu, jde o multilanguage OCR). YAGF je přehledný, umí skenovat pomocí XSANE, převede do textu více stran – a podle mě je v převodu o dost úspěšnější než výše zmíněný gocr2pdf. S češtinou nemá problém, slovenština chybí.
Složitější je instalace, ale dá se to zvládnout. Nejprve nainstalujeme Cuneiform OCR, cmake a qt4. Pak stáhneme ze stránky projektu RPM balíček pro Fedoru, instalační script – postará se o doinstalování grafického prostředí YAGF, nebo arhiv se zdrojáky pro kompilaci.
Pokud tedy nemáte Fedoru (11), nefunguje vám instalační script, pak budeme kompilovat. Rozbalte stažený tar.gz archiv a v adresáři rozbaleného archivu postupně zadejte příkazy:
cmake CMakeLists.txt
make
sudo make install
Program se pouští příkazem yagf, možná bude třeba přidat položku do menu ručně. Nezapomeňte při skenování nastavit dostatečně jemné rozlišení (doporučuji 300 kpi) a dostatečný kontrast, dále po naskenování či nahrání obrázku vybrat (zamodřit) oblast s textem, jinak to OCR nepobere.
Výhodou je funkční čeština, pěkné prostředí, hromadné převedení textu. Nevýhodou je zpočátku složitější instalace a skromné možnosti nastavení programu.
3. VueSCAN

Jde o placený multiplatformní produkt za 40 / 80 dolarů (standard / professional), což mi nepřipadá zase tak moc peněz. Program vypadá dobře, domovské stránky jsou také v češtině a je zde ke stažení archiv pro Red Hat či pro Ubuntu.(samozřejmě kromě Windows). Program se neinstaluje, pouze rozbalíte archiv a spustíte vuescan.
Výhody – vypadá to hezky a četl jsem chválu, ale nemohl vyzkoušet, program hlásí, že můj Canon LIDE 35 není podporovaný v inuxu i když jinde skenuju jako divý. To je možná první nevýhoda aktuální verze – neumí každý skener, který vám funguje v linuxu. Jako další nevýhodu vidím nemožnost načítání naskenovaných souborů, ale to může být tím, že pouštím trial verzi. Pokud OCR funguje opravdu dobře, nebylo by mi líto něco zaplatit. Jak už jsem psal dříve, možnost volby mezi open source a placeným produktem v linuxu podporuju.
4. Aplikace pro Windows – TopOCR, FineReader či jiná
Psal jsem už o TopOCR, který převádí bitmapu s textem do PDF. Pod wine funguje i když ne bez chyby. Podstatné je, že skenuje a převádí, ale pouze jednu stranu. Výsledek měl problémy s diakritikou, takže to moc použitelné není. Ovšem ukazuje to na možnost vyhledat jiný program, který wine zvládne a pomůže tak zalepit díru v nabídce pro linux. Poslední verze Abbyy FineReaderu nefunguje (hlásí to neplatný příkazový řádek, možná by to šlo poladit), ale starší verze (7.0 Professional), kterou jsem dostal ke svému staršímu skeneru, se nainstaluje korektně. Skenování tentokrát nefunguje, ale OCR běží perfektně. Výsledky převodu i možnosti nastavení se s YAGF či gocr2pdf nedají srovnat, bohužel.

Takže rozpačité pocity přetrvávají i když je teď pro mě situace méně depresivní, beznadějná. YAGF se dá používat, gocr2pdf, respektive Tesseract, by potřebovalo nutně dodělat češtinu, byl by to velký skok kupředu. VueSCAN je slibný, ale asi si ještě počkáme. Aplikace pro Windows jsou jen náplastí, která určitě není bez chyby.
-
Související články na blogu Můj vztah s linuxem - kdy mi pomáhá a kdy mě ničí
-
OCR v linuxu 7. 6. 2010 22:59
-
Bitmapa jako ASCII 18. 12. 2011 11:52
-
Práce s grafikou v Androidu a linuxu 12. 7. 2011 11:00
-
Něco pro hračičky: Tablet na kreslení i ovládání systému 15. 10. 2010 19:19
-
Jak vytvořit z videa a fotek DVD 8. 8. 2010 14:51
-
Hromadné přejmenování souborů 19. 6. 2010 23:33
-
-
Související články na ostatních blozích
-
Knihovníci 26. 7. 2013 8:29
-
-
dan (neregistrovaný)
"Nevýhodou je pro Čechy i Slováky absence těchto jazyků pro Tesseract"
Tak ako som pisal v komentari k predoslom clanku o OCR, na tejto stranke: http://www.sk-spell.sk.cx/OCR sa vyvija modul pre podporu slovenciny v teserract-e
-
rs (neregistrovaný)
Pod WINE pouzivam uspesne stary program RECOGNITA STANDARD verzia 4 ktory manzelka kupila spolu so skenerom uz niekedy v roku 1998. Skenovanie som neskusal ale dokaze otvarat subory TIFF a BMP. Bezne prevadzam texty nafotene z fotaku. Rozlisovacia schopnost je podla mna skvela - zalezi od predlohy, ked som porovnaval s ABBYY tak bola dokonca lepsia.
-
me (neregistrovaný)
Je nutne OCR provozovat se scannerem? Autor pise ze VueSCAN si nerozumi s jeho scannerem. Nelze ulohu rozdelit na dve casti, nejak takto?
1) SCAN, uloz do obrazku
2) OCR, zpracuj obrazek, preved na TEXT dokument.Osobne si myslim, ze pokud OCR program neumi pouzit jako vstup obrazek, pak to neni dobry OCR program... Je mozne, ze mezikrok, kdy se dokument scannuje nejprve do obrazku muze byt narocny na misto na disku.
Scanner nemam, ale mam kvalitni digitalni fotak. Uvazuji, ze by jsem jej obcas pouzil na prevod nekterych starsich dokumentu do digitalni podoby. Pokud OCR program vyzaduje pripojeni scanneru, tak jsem s digitalnim fotakem (jako vstupnim zarizenim) v ...
-
ikarlos (neregistrovaný)
Používám Fedoru 12. Ze zdrojových balíčků,stažených z netu, jsem pomocí rpmbuild --rebuild vytvořil yagf-0.8.1-1.fc12.i686.rpm (naprosto bez problému, nic nebylo nutno doinstalovávat) a balíček cuneiform-0.6-5.1.i686.rpm (zdrojový balíček byl pro suse, vázl na závislosti na ImageMagick-Magick++-devel, která je ve Fedoře jinak pojmenovaná, takže bylo nutno k --rebuild přidat ještě --nodeps. I zde pak vytvoření binárního balíčku proběhlo bez chyby.). Shrnu - instalace YAGF/Cuneiform pod Fedorou 12 je brnkačka.
Co se týče provozu - oproti gocr nebe a dudy. Převod české předlohy tištěné laserovou tiskárnou na kancelářské A4 - celá stránka bez chyby - spellchecker (balíček aspell-cs) našel pár překlepů - ty ovšem byly už v původním textu. Převod stránky oskenované ze starší knihy a zešikma - občas chyba, ale opravdu minimum.
Závěr: Obrovské díky autorovi blogu, za to, že na tuto funkční aplikaci OCR upozornil! -
skrat (neregistrovaný)
Naucit tesseract cestinu alebo slovencinu by malo byt podla http://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract v celku jednoduche, bohuzial nepotrebujem to nutne, takze sa nechytam
-
Harvie (neregistrovaný)
Docela by se mi hodilo neco, co veme 60MB velky PDF (plny JPEGu) stazeny odnekud z netu a zOCRkuje ho (zase zpatky do OCR). Nektery warezaci se s tim totiz moc nese*ou a nez aby premejsleli o OCR, tak radsi uploadnou 50-500MB (ano opravdu i 500MB se najdou) velky PDF...
Dokonce jsem i videl dokonale ripnutou knihu, kde z normalniho scanu byly automaticky odstraneny okraje, vyrovnany zakrivene tvary, vsechno pismo bylo zOCRkovano a byl automaticky pouzit nejpodobnejsi font, zaroven veci, co se nepodarilo vyresit pomoci OCR byly nahrazeny puvodnim obrazkem (u textu se to stalo snad na jedinem miste v cele knize...). A byly k dispozice 2 verze - text pres obrazek (kde je zarucena 100% vernost) a text-nebo-obrazek, kde se v miste s textem obrazky vynechaji (nezaznamenal jsem temer zadny propad kvality proti prvni moznosti). A tak byl udelan velice kvalitni scan cele knihy (ale par veci nasvedcovalo tomu, ze to skutecne scan je). Nevite nekdo neco o takovem zazracnem softwaru?
-
Jordan 6 (neregistrovaný)
Interesting article as for me. It would be great to read a bit more about that topic.
Jordan 6 -
trofster (neregistrovaný)
Ako mozem doinstalovat jazyky, ked som si nainstaloval v ubuntu z repozitarov tesseract, kde bol len anglicky nemecky balik ale slovensky tam nebol, ten som stiahol zo zdrojov na internete a teraz by som to chcel doinstalovat. neviem do akeho adredsa ra to mam rozbalit :(.
Vedeli by ste mi pomoct?






















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}