Rozpoznání zápalu plic z RTG snímků - díl druhý
Tímto článkem navazuji na předchozí: Rozpoznání zápalu plic z RTG snímků – díl první .
Model VGG16
Jedná se o jeden ze základních modelů pro klasifikaci obrázků založených na konvolučních vrstvách. Principem je postupné zmenšování plošných dimenzí a naopak rozšiřování velikosti vlastností. Názorné schéma modelu vypadá takto:
Jako podklad pro detailnější studium by mohl posloužit například tento článek (ale další dostupných zdrojů je pochopitelně více): Everything you need to know about VGG16
VGG16 trénovaný z čistého stolu
Nejdříve si vyzkouším napsat implementaci modelu sám a také jej vytrénovat s využitím vlastních dat.
Takto si tedy vytvořím model:
In [13]:
def create_model_VGG16(X_shape, classes=2, name="VGG16"):
def mlp(x, hidden_units, activation='relu', dropout_rate=0.3, name=""):
for i, units in enumerate(hidden_units):
x = layers.Dense(units, activation=activation, name=f"{name}_{i}_dense")(x)
x = layers.Dropout(dropout_rate, name=f"{name}_{i}_dropout")(x)
return x
def conv_block(x, filters, *, kernels=None, steps=None, dropout=0.2, name=""):
for i in range(len(filters)):
x = layers.Conv2D(filters[i], kernels[i] if kernels else (3, 3), strides=steps[i] if steps else (1, 1), padding='same', name=f'{name}_conv_{i}')(x)
x = layers.BatchNormalization(name=f'{name}_norm_{i}')(x)
x = layers.Activation('relu', name=f'{name}_relu_{i}')(x)
x = layers.MaxPooling2D((2, 2), name=f'{name}_maxpool')(x)
return x
inputs = Input(X_shape[-3:], name='inputs')
x = conv_block(inputs, (64, 64), name="block_1")
x = conv_block(x, (128, 128), name="block_2")
x = conv_block(x, (256, 256, 256), name="block_3")
x = conv_block(x, (512, 512, 512), name="block_4")
x = conv_block(x, (512, 512, 512), name="block_5")
x = layers.Flatten(name="flatten")(x)
x = mlp(x, (1024, 512), name="dense")
outputs = layers.Dense(classes, activation='softmax', name='outputs')(x)
return Model(inputs=inputs, outputs=outputs, name=name)
Vidíte, že je poskládán z pěti konvolučních bloků, ve kterých se postupně zmenšují prostorové dimenze (to má na svědomí vrstva MaxPooling2D) a naopak se zvětšují počty vlastností (to je dáno počtem filtrů).
Po konvolučních blocích následuje úplné opuštění prostorových dimenzí – vrstva Flatten.
Závěr je zajištěn plně propojenými vrstvami ve formě multi-layer perceptron (MLP) a závěrečné klasifikační vrstvy s aktivací softmax.
Před testováním opět příprava dat. Budu používat snímky v odstínech šedi:
In [14]:
x_train, x_valid, y_train, y_valid = train_test_split(*get_datasource(DATA_TRAIN, DATA_VALID), test_size=0.2)
x_test, y_test = get_datasource(DATA_TEST)
x_train = np.expand_dims(x_train, axis=-1)
x_valid = np.expand_dims(x_valid, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)
datagen = ImageDataGenerator(
rotation_range = 30,
zoom_range = 0.2,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip = True,
vertical_flip=False)
datagen.fit(x_train)
A takto vypadá vlastní vyhodnocení modelu:
In [15]:
evaluate_model(create_model_VGG16(x_train.shape, 2, name='VGG16'), forced_training=False) === MODEL EVALUATION ================================================= Model: "VGG16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= inputs (InputLayer) [(None, 224, 224, 1)] 0 block_1_conv_0 (Conv2D) (None, 224, 224, 64) 640 block_1_norm_0 (BatchNorma (None, 224, 224, 64) 256 lization) block_1_relu_0 (Activation (None, 224, 224, 64) 0 ) block_1_conv_1 (Conv2D) (None, 224, 224, 64) 36928 block_1_norm_1 (BatchNorma (None, 224, 224, 64) 256 lization) block_1_relu_1 (Activation (None, 224, 224, 64) 0 ) block_1_maxpool (MaxPoolin (None, 112, 112, 64) 0 g2D) block_2_conv_0 (Conv2D) (None, 112, 112, 128) 73856 block_2_norm_0 (BatchNorma (None, 112, 112, 128) 512 lization) block_2_relu_0 (Activation (None, 112, 112, 128) 0 ) block_2_conv_1 (Conv2D) (None, 112, 112, 128) 147584 block_2_norm_1 (BatchNorma (None, 112, 112, 128) 512 lization) block_2_relu_1 (Activation (None, 112, 112, 128) 0 ) block_2_maxpool (MaxPoolin (None, 56, 56, 128) 0 g2D) block_3_conv_0 (Conv2D) (None, 56, 56, 256) 295168 block_3_norm_0 (BatchNorma (None, 56, 56, 256) 1024 lization) block_3_relu_0 (Activation (None, 56, 56, 256) 0 ) block_3_conv_1 (Conv2D) (None, 56, 56, 256) 590080 block_3_norm_1 (BatchNorma (None, 56, 56, 256) 1024 lization) block_3_relu_1 (Activation (None, 56, 56, 256) 0 ) block_3_conv_2 (Conv2D) (None, 56, 56, 256) 590080 block_3_norm_2 (BatchNorma (None, 56, 56, 256) 1024 lization) block_3_relu_2 (Activation (None, 56, 56, 256) 0 ) block_3_maxpool (MaxPoolin (None, 28, 28, 256) 0 g2D) block_4_conv_0 (Conv2D) (None, 28, 28, 512) 1180160 block_4_norm_0 (BatchNorma (None, 28, 28, 512) 2048 lization) block_4_relu_0 (Activation (None, 28, 28, 512) 0 ) block_4_conv_1 (Conv2D) (None, 28, 28, 512) 2359808 block_4_norm_1 (BatchNorma (None, 28, 28, 512) 2048 lization) block_4_relu_1 (Activation (None, 28, 28, 512) 0 ) block_4_conv_2 (Conv2D) (None, 28, 28, 512) 2359808 block_4_norm_2 (BatchNorma (None, 28, 28, 512) 2048 lization) block_4_relu_2 (Activation (None, 28, 28, 512) 0 ) block_4_maxpool (MaxPoolin (None, 14, 14, 512) 0 g2D) block_5_conv_0 (Conv2D) (None, 14, 14, 512) 2359808 block_5_norm_0 (BatchNorma (None, 14, 14, 512) 2048 lization) block_5_relu_0 (Activation (None, 14, 14, 512) 0 ) block_5_conv_1 (Conv2D) (None, 14, 14, 512) 2359808 block_5_norm_1 (BatchNorma (None, 14, 14, 512) 2048 lization) block_5_relu_1 (Activation (None, 14, 14, 512) 0 ) block_5_conv_2 (Conv2D) (None, 14, 14, 512) 2359808 block_5_norm_2 (BatchNorma (None, 14, 14, 512) 2048 lization) block_5_relu_2 (Activation (None, 14, 14, 512) 0 ) block_5_maxpool (MaxPoolin (None, 7, 7, 512) 0 g2D) flatten (Flatten) (None, 25088) 0 dense_0_dense (Dense) (None, 1024) 25691136 dense_0_dropout (Dropout) (None, 1024) 0 dense_1_dense (Dense) (None, 512) 524800 dense_1_dropout (Dropout) (None, 512) 0 outputs (Dense) (None, 2) 1026 ================================================================= Total params: 40947394 (156.20 MB) Trainable params: 40938946 (156.17 MB) Non-trainable params: 8448 (33.00 KB) _________________________________________________________________ --- Model training --------------------------------------------------- Epoch 1/40 131/131 [==============================] - ETA: 0s - loss: 1.3506 - accuracy: 0.6944 - auc: 0.7577 Epoch 1: val_auc improved from -inf to 0.74785, saving model to /kaggle/working/model/VGG16.ckpt 131/131 [==============================] - 62s 369ms/step - loss: 1.3506 - accuracy: 0.6944 - auc: 0.7577 - val_loss: 43.0450 - val_accuracy: 0.7479 - val_auc: 0.7479 Epoch 2/40 131/131 [==============================] - ETA: 0s - loss: 0.6281 - accuracy: 0.7376 - auc: 0.8404 Epoch 2: val_auc did not improve from 0.74785 131/131 [==============================] - 36s 276ms/step - loss: 0.6281 - accuracy: 0.7376 - auc: 0.8404 - val_loss: 12.9182 - val_accuracy: 0.7479 - val_auc: 0.7479 Epoch 3/40 131/131 [==============================] - ETA: 0s - loss: 0.4900 - accuracy: 0.8256 - auc: 0.9112 Epoch 3: val_auc did not improve from 0.74785 131/131 [==============================] - 37s 279ms/step - loss: 0.4900 - accuracy: 0.8256 - auc: 0.9112 - val_loss: 7.0124 - val_accuracy: 0.7479 - val_auc: 0.7479 Epoch 4/40 131/131 [==============================] - ETA: 0s - loss: 0.3516 - accuracy: 0.8597 - auc: 0.9375 Epoch 4: val_auc did not improve from 0.74785 131/131 [==============================] - 37s 278ms/step - loss: 0.3516 - accuracy: 0.8597 - auc: 0.9375 - val_loss: 6.2788 - val_accuracy: 0.7479 - val_auc: 0.7479 Epoch 5/40 131/131 [==============================] - ETA: 0s - loss: 0.2710 - accuracy: 0.8822 - auc: 0.9561 Epoch 5: val_auc improved from 0.74785 to 0.75282, saving model to /kaggle/working/model/VGG16.ckpt 131/131 [==============================] - 44s 332ms/step - loss: 0.2710 - accuracy: 0.8822 - auc: 0.9561 - val_loss: 0.6298 - val_accuracy: 0.6619 - val_auc: 0.7528 Epoch 6/40 131/131 [==============================] - ETA: 0s - loss: 0.2601 - accuracy: 0.8941 - auc: 0.9623 Epoch 6: val_auc improved from 0.75282 to 0.96774, saving model to /kaggle/working/model/VGG16.ckpt 131/131 [==============================] - 44s 332ms/step - loss: 0.2601 - accuracy: 0.8941 - auc: 0.9623 - val_loss: 0.2389 - val_accuracy: 0.8968 - val_auc: 0.9677 Epoch 7/40 131/131 [==============================] - ETA: 0s - loss: 0.2816 - accuracy: 0.8877 - auc: 0.9578 Epoch 7: val_auc did not improve from 0.96774 131/131 [==============================] - 37s 278ms/step - loss: 0.2816 - accuracy: 0.8877 - auc: 0.9578 - val_loss: 0.7441 - val_accuracy: 0.7832 - val_auc: 0.8990 Epoch 8/40 131/131 [==============================] - ETA: 0s - loss: 0.2391 - accuracy: 0.9020 - auc: 0.9658 Epoch 8: val_auc did not improve from 0.96774 131/131 [==============================] - 36s 277ms/step - loss: 0.2391 - accuracy: 0.9020 - auc: 0.9658 - val_loss: 0.7869 - val_accuracy: 0.6285 - val_auc: 0.6936 Epoch 9/40 131/131 [==============================] - ETA: 0s - loss: 0.2318 - accuracy: 0.9075 - auc: 0.9690 Epoch 9: val_auc did not improve from 0.96774 131/131 [==============================] - 37s 278ms/step - loss: 0.2318 - accuracy: 0.9075 - auc: 0.9690 - val_loss: 0.7344 - val_accuracy: 0.5979 - val_auc: 0.6878 Epoch 10/40 131/131 [==============================] - ETA: 0s - loss: 0.2295 - accuracy: 0.9109 - auc: 0.9692 Epoch 10: val_auc did not improve from 0.96774 131/131 [==============================] - 36s 277ms/step - loss: 0.2295 - accuracy: 0.9109 - auc: 0.9692 - val_loss: 0.3142 - val_accuracy: 0.8739 - val_auc: 0.9428 Epoch 11/40 131/131 [==============================] - ETA: 0s - loss: 0.2212 - accuracy: 0.9202 - auc: 0.9721 Epoch 11: val_auc did not improve from 0.96774 131/131 [==============================] - 36s 276ms/step - loss: 0.2212 - accuracy: 0.9202 - auc: 0.9721 - val_loss: 0.8512 - val_accuracy: 0.6122 - val_auc: 0.6439 Epoch 12/40 131/131 [==============================] - ETA: 0s - loss: 0.2093 - accuracy: 0.9183 - auc: 0.9746 Epoch 12: val_auc did not improve from 0.96774 131/131 [==============================] - 37s 279ms/step - loss: 0.2093 - accuracy: 0.9183 - auc: 0.9746 - val_loss: 0.2938 - val_accuracy: 0.8892 - val_auc: 0.9558 Epoch 13/40 131/131 [==============================] - ETA: 0s - loss: 0.1989 - accuracy: 0.9302 - auc: 0.9765 Epoch 13: val_auc did not improve from 0.96774 131/131 [==============================] - 36s 278ms/step - loss: 0.1989 - accuracy: 0.9302 - auc: 0.9765 - val_loss: 0.2497 - val_accuracy: 0.9035 - val_auc: 0.9614 Epoch 14/40 131/131 [==============================] - ETA: 0s - loss: 0.1884 - accuracy: 0.9345 - auc: 0.9783 Epoch 14: val_auc did not improve from 0.96774 131/131 [==============================] - 37s 279ms/step - loss: 0.1884 - accuracy: 0.9345 - auc: 0.9783 - val_loss: 0.5664 - val_accuracy: 0.7650 - val_auc: 0.8407 Epoch 15/40 131/131 [==============================] - ETA: 0s - loss: 0.2049 - accuracy: 0.9188 - auc: 0.9750 Epoch 15: val_auc did not improve from 0.96774 131/131 [==============================] - 36s 278ms/step - loss: 0.2049 - accuracy: 0.9188 - auc: 0.9750 - val_loss: 0.8792 - val_accuracy: 0.7698 - val_auc: 0.8510 Epoch 16/40 131/131 [==============================] - ETA: 0s - loss: 0.1908 - accuracy: 0.9309 - auc: 0.9776 Epoch 16: val_auc did not improve from 0.96774 131/131 [==============================] - 37s 279ms/step - loss: 0.1908 - accuracy: 0.9309 - auc: 0.9776 - val_loss: 0.4967 - val_accuracy: 0.7584 - val_auc: 0.8660 --- Training history -------------------------------------------------
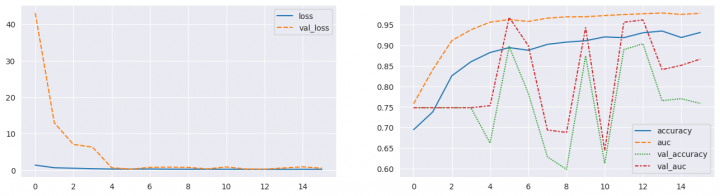
--- Test Predictions and Metrics -------------------------------------
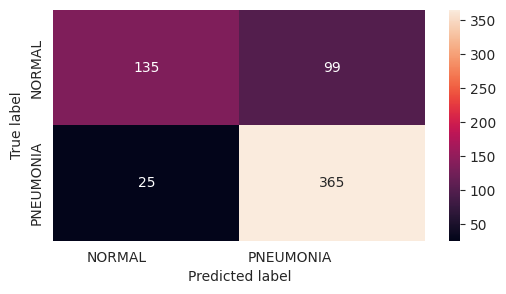
precision recall f1-score support
NORMAL 0.84 0.58 0.69 234
PNEUMONIA 0.79 0.94 0.85 390
accuracy 0.80 624
macro avg 0.82 0.76 0.77 624
weighted avg 0.81 0.80 0.79 624
=== MODEL EVALUATION FINISHED ========================================
VGG16 transfer learning
V předchozí kapitole jsem si model vytvořil sám a sám jsem jej také trénoval na vlastních datech. Druhou možností, a ta je také hodně oblíbená, je využití již dříve připravených a trénovaných modelů. Takových již připravených modelů je velké množství, například některé jako součást distribuce Keras. Vyzkouším si jeden takový použít.
Problémem je, že tyto modely byly trénovány pro jinou datovou sadu, než mám já, a také na jiné klasifikační třídy (prostě klasifikaci do třídy NORMAL a PNEUMONIA byste tam nenašli). To se řeší tak, že se použije jen část připraveného modelu, především ta konvoluční, a klasifikační vrstvy se tam dodají až následně. No a pak se trénují pouze ty doplněné vrstvy.
Takto nějak by to mohlo vypadat pro model VGG16:
In [16]:
from keras.applications import VGG16
def create_model_VGG16Trans(X_shape, classes=2, name="VGG16Trans"):
def mlp(x, hidden_units, activation='relu', dropout_rate=0.3, name=""):
for i, units in enumerate(hidden_units):
x = layers.Dense(units, activation=activation, name=f"{name}_{i}_dense")(x)
x = layers.Dropout(dropout_rate, name=f"{name}_{i}_dropout")(x)
return x
base_model = VGG16(include_top=False, input_shape=tuple(X_shape)[-3:])
base_model.trainable = False
inputs = Input(X_shape[-3:], name='inputs')
x = base_model(inputs, training=False)
x = layers.Flatten(name="flatten")(x)
x = mlp(x, (1024, 512), name="dense")
outputs = layers.Dense(classes, activation='softmax', name='outputs')(x)
return Model(inputs=inputs, outputs=outputs, name=name)
Načetl jsem si model z distribuce Keras s vyloučením klasifikačních vrstev. Ty jsem následně doplnil sám ve formě MLP a poslední plně propojené vrstvy s aktivační funkcí softmax do dvou klasifikačních tříd.
Musím si ještě připravit data. V tomto případě musím obrázky načíst jako RGB snímky, protože původní model takto trénován byl:
In [17]:
x_train, x_valid, y_train, y_valid = train_test_split(*get_datasource(DATA_TRAIN, DATA_VALID, flag=cv2.IMREAD_COLOR), test_size=0.2)
x_test, y_test = get_datasource(DATA_TEST, flag=cv2.IMREAD_COLOR)
datagen = ImageDataGenerator(
rotation_range = 30,
zoom_range = 0.2,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip = True,
vertical_flip=False)
datagen.fit(x_train)
A nyní již vlastní vyhodnocení:
In [18]:
evaluate_model(create_model_VGG16Trans(x_train.shape, 2), forced_training=False) Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 58889256/58889256 [==============================] - 0s 0us/step === MODEL EVALUATION ================================================= Model: "VGG16Trans" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= inputs (InputLayer) [(None, 224, 224, 3)] 0 vgg16 (Functional) (None, 7, 7, 512) 14714688 flatten (Flatten) (None, 25088) 0 dense_0_dense (Dense) (None, 1024) 25691136 dense_0_dropout (Dropout) (None, 1024) 0 dense_1_dense (Dense) (None, 512) 524800 dense_1_dropout (Dropout) (None, 512) 0 outputs (Dense) (None, 2) 1026 ================================================================= Total params: 40931650 (156.14 MB) Trainable params: 26216962 (100.01 MB) Non-trainable params: 14714688 (56.13 MB) _________________________________________________________________ --- Model training --------------------------------------------------- Epoch 1/40 131/131 [==============================] - ETA: 0s - loss: 0.7880 - accuracy: 0.8380 - auc: 0.9009 Epoch 1: val_auc improved from -inf to 0.97700, saving model to /kaggle/working/model/VGG16Trans.ckpt 131/131 [==============================] - 60s 427ms/step - loss: 0.7880 - accuracy: 0.8380 - auc: 0.9009 - val_loss: 0.1930 - val_accuracy: 0.9236 - val_auc: 0.9770 Epoch 2/40 131/131 [==============================] - ETA: 0s - loss: 0.2414 - accuracy: 0.9054 - auc: 0.9660 Epoch 2: val_auc improved from 0.97700 to 0.98849, saving model to /kaggle/working/model/VGG16Trans.ckpt 131/131 [==============================] - 54s 414ms/step - loss: 0.2414 - accuracy: 0.9054 - auc: 0.9660 - val_loss: 0.1473 - val_accuracy: 0.9484 - val_auc: 0.9885 Epoch 3/40 131/131 [==============================] - ETA: 0s - loss: 0.2004 - accuracy: 0.9197 - auc: 0.9756 Epoch 3: val_auc did not improve from 0.98849 131/131 [==============================] - 52s 397ms/step - loss: 0.2004 - accuracy: 0.9197 - auc: 0.9756 - val_loss: 0.1584 - val_accuracy: 0.9341 - val_auc: 0.9851 Epoch 4/40 131/131 [==============================] - ETA: 0s - loss: 0.1825 - accuracy: 0.9266 - auc: 0.9795 Epoch 4: val_auc improved from 0.98849 to 0.98866, saving model to /kaggle/working/model/VGG16Trans.ckpt 131/131 [==============================] - 55s 420ms/step - loss: 0.1825 - accuracy: 0.9266 - auc: 0.9795 - val_loss: 0.1331 - val_accuracy: 0.9503 - val_auc: 0.9887 Epoch 5/40 131/131 [==============================] - ETA: 0s - loss: 0.1848 - accuracy: 0.9271 - auc: 0.9789 Epoch 5: val_auc did not improve from 0.98866 131/131 [==============================] - 51s 392ms/step - loss: 0.1848 - accuracy: 0.9271 - auc: 0.9789 - val_loss: 0.1578 - val_accuracy: 0.9446 - val_auc: 0.9832 Epoch 6/40 131/131 [==============================] - ETA: 0s - loss: 0.1545 - accuracy: 0.9407 - auc: 0.9850 Epoch 6: val_auc improved from 0.98866 to 0.98935, saving model to /kaggle/working/model/VGG16Trans.ckpt 131/131 [==============================] - 55s 420ms/step - loss: 0.1545 - accuracy: 0.9407 - auc: 0.9850 - val_loss: 0.1329 - val_accuracy: 0.9436 - val_auc: 0.9893 Epoch 7/40 131/131 [==============================] - ETA: 0s - loss: 0.1591 - accuracy: 0.9395 - auc: 0.9842 Epoch 7: val_auc did not improve from 0.98935 131/131 [==============================] - 51s 389ms/step - loss: 0.1591 - accuracy: 0.9395 - auc: 0.9842 - val_loss: 0.1284 - val_accuracy: 0.9484 - val_auc: 0.9893 Epoch 8/40 131/131 [==============================] - ETA: 0s - loss: 0.1554 - accuracy: 0.9381 - auc: 0.9850 Epoch 8: val_auc improved from 0.98935 to 0.99141, saving model to /kaggle/working/model/VGG16Trans.ckpt 131/131 [==============================] - 55s 417ms/step - loss: 0.1554 - accuracy: 0.9381 - auc: 0.9850 - val_loss: 0.1194 - val_accuracy: 0.9513 - val_auc: 0.9914 Epoch 9/40 131/131 [==============================] - ETA: 0s - loss: 0.1449 - accuracy: 0.9417 - auc: 0.9869 Epoch 9: val_auc did not improve from 0.99141 131/131 [==============================] - 52s 395ms/step - loss: 0.1449 - accuracy: 0.9417 - auc: 0.9869 - val_loss: 0.1535 - val_accuracy: 0.9389 - val_auc: 0.9860 Epoch 10/40 131/131 [==============================] - ETA: 0s - loss: 0.1368 - accuracy: 0.9467 - auc: 0.9883 Epoch 10: val_auc did not improve from 0.99141 131/131 [==============================] - 51s 387ms/step - loss: 0.1368 - accuracy: 0.9467 - auc: 0.9883 - val_loss: 0.1240 - val_accuracy: 0.9561 - val_auc: 0.9909 Epoch 11/40 131/131 [==============================] - ETA: 0s - loss: 0.1611 - accuracy: 0.9352 - auc: 0.9839 Epoch 11: val_auc did not improve from 0.99141 131/131 [==============================] - 51s 390ms/step - loss: 0.1611 - accuracy: 0.9352 - auc: 0.9839 - val_loss: 0.1199 - val_accuracy: 0.9503 - val_auc: 0.9912 Epoch 12/40 131/131 [==============================] - ETA: 0s - loss: 0.1677 - accuracy: 0.9295 - auc: 0.9829 Epoch 12: val_auc did not improve from 0.99141 131/131 [==============================] - 51s 389ms/step - loss: 0.1677 - accuracy: 0.9295 - auc: 0.9829 - val_loss: 0.1267 - val_accuracy: 0.9522 - val_auc: 0.9894 Epoch 13/40 131/131 [==============================] - ETA: 0s - loss: 0.1464 - accuracy: 0.9405 - auc: 0.9867 Epoch 13: val_auc did not improve from 0.99141 131/131 [==============================] - 51s 391ms/step - loss: 0.1464 - accuracy: 0.9405 - auc: 0.9867 - val_loss: 0.1261 - val_accuracy: 0.9494 - val_auc: 0.9906 Epoch 14/40 131/131 [==============================] - ETA: 0s - loss: 0.1295 - accuracy: 0.9498 - auc: 0.9893 Epoch 14: val_auc improved from 0.99141 to 0.99262, saving model to /kaggle/working/model/VGG16Trans.ckpt 131/131 [==============================] - 54s 415ms/step - loss: 0.1295 - accuracy: 0.9498 - auc: 0.9893 - val_loss: 0.1198 - val_accuracy: 0.9589 - val_auc: 0.9926 Epoch 15/40 131/131 [==============================] - ETA: 0s - loss: 0.1374 - accuracy: 0.9503 - auc: 0.9881 Epoch 15: val_auc did not improve from 0.99262 131/131 [==============================] - 52s 395ms/step - loss: 0.1374 - accuracy: 0.9503 - auc: 0.9881 - val_loss: 0.1211 - val_accuracy: 0.9580 - val_auc: 0.9906 Epoch 16/40 131/131 [==============================] - ETA: 0s - loss: 0.1329 - accuracy: 0.9486 - auc: 0.9889 Epoch 16: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 392ms/step - loss: 0.1329 - accuracy: 0.9486 - auc: 0.9889 - val_loss: 0.1131 - val_accuracy: 0.9618 - val_auc: 0.9907 Epoch 17/40 131/131 [==============================] - ETA: 0s - loss: 0.1353 - accuracy: 0.9503 - auc: 0.9880 Epoch 17: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 393ms/step - loss: 0.1353 - accuracy: 0.9503 - auc: 0.9880 - val_loss: 0.1136 - val_accuracy: 0.9647 - val_auc: 0.9905 Epoch 18/40 131/131 [==============================] - ETA: 0s - loss: 0.1287 - accuracy: 0.9520 - auc: 0.9898 Epoch 18: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 391ms/step - loss: 0.1287 - accuracy: 0.9520 - auc: 0.9898 - val_loss: 0.1262 - val_accuracy: 0.9589 - val_auc: 0.9911 Epoch 19/40 131/131 [==============================] - ETA: 0s - loss: 0.1313 - accuracy: 0.9453 - auc: 0.9895 Epoch 19: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 390ms/step - loss: 0.1313 - accuracy: 0.9453 - auc: 0.9895 - val_loss: 0.1219 - val_accuracy: 0.9589 - val_auc: 0.9897 Epoch 20/40 131/131 [==============================] - ETA: 0s - loss: 0.1250 - accuracy: 0.9534 - auc: 0.9897 Epoch 20: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 393ms/step - loss: 0.1250 - accuracy: 0.9534 - auc: 0.9897 - val_loss: 0.1068 - val_accuracy: 0.9637 - val_auc: 0.9922 Epoch 21/40 131/131 [==============================] - ETA: 0s - loss: 0.1168 - accuracy: 0.9536 - auc: 0.9913 Epoch 21: val_auc did not improve from 0.99262 131/131 [==============================] - 52s 396ms/step - loss: 0.1168 - accuracy: 0.9536 - auc: 0.9913 - val_loss: 0.1225 - val_accuracy: 0.9522 - val_auc: 0.9909 Epoch 22/40 131/131 [==============================] - ETA: 0s - loss: 0.1160 - accuracy: 0.9558 - auc: 0.9909 Epoch 22: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 386ms/step - loss: 0.1160 - accuracy: 0.9558 - auc: 0.9909 - val_loss: 0.1367 - val_accuracy: 0.9532 - val_auc: 0.9884 Epoch 23/40 131/131 [==============================] - ETA: 0s - loss: 0.1098 - accuracy: 0.9572 - auc: 0.9925 Epoch 23: val_auc did not improve from 0.99262 131/131 [==============================] - 52s 398ms/step - loss: 0.1098 - accuracy: 0.9572 - auc: 0.9925 - val_loss: 0.1116 - val_accuracy: 0.9551 - val_auc: 0.9924 Epoch 24/40 131/131 [==============================] - ETA: 0s - loss: 0.1162 - accuracy: 0.9534 - auc: 0.9913 Epoch 24: val_auc did not improve from 0.99262 131/131 [==============================] - 51s 392ms/step - loss: 0.1162 - accuracy: 0.9534 - auc: 0.9913 - val_loss: 0.1244 - val_accuracy: 0.9580 - val_auc: 0.9894 --- Training history -------------------------------------------------
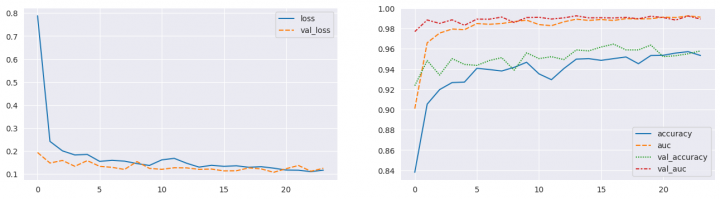
--- Test Predictions and Metrics -------------------------------------
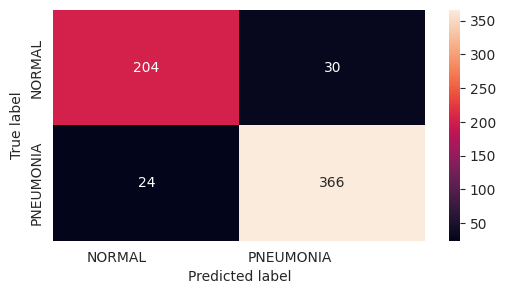
precision recall f1-score support
NORMAL 0.89 0.87 0.88 234
PNEUMONIA 0.92 0.94 0.93 390
accuracy 0.91 624
macro avg 0.91 0.91 0.91 624
weighted avg 0.91 0.91 0.91 624
=== MODEL EVALUATION FINISHED ========================================
V následujícím dílu budu pokračovat modelem ResNet50.




















