Rozpoznání zápalu plic z RTG snímků - ViT model
Vision Transformer model
Po nástupu GPT modelů se stala architektura transformerů velice oblíbenou i v jiných oblastech. Najednou vidíte tyhle modely založené na Attention všude. Nabízí se tedy vyzkoušet si je na vlastní kůži. A o tom bude tento článek.
Opět vycházím z datové sady Chest X-Ray Images (Pneumonia) stejně jako tomu bylo v předchozích článcích zabývajících se rozpoznáním zápalu plic z RTG snímků s využitím především konvolučních vrstev. V přípravě dat a následném vyhodnocení modelu jsem udělal drobné změny, proto je zde uvedu také.
V případě klasifikace obrazových dat se architektura transformerů přetavila na tzv. Vision Transformer. Schematických zobrazení najdete na webu jistě hodně, pro úvodní představu tohle je jeden z nich:
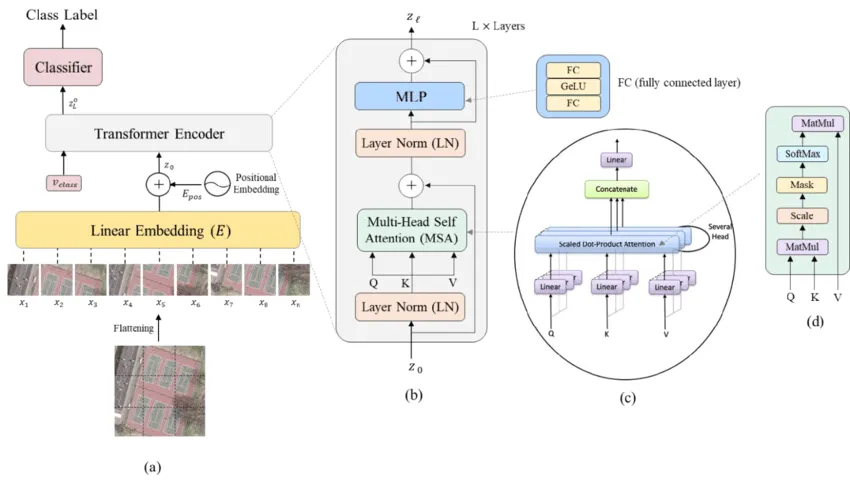
Jako předlohu pro implementaci modelu jsem využil především tento článek : Image classification with Vision Transformer
Opět vyzkouším napsat a trénovat model z čistého stolu a následně také jeden model dříve trénovaný na jiné datové sadě.
In [1]:
import sys
import os
import shutil
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.image import extract_patches
from keras.utils import image_dataset_from_directory
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.optimizers import AdamW
from keras import Input, Model
from keras import layers
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.utils.class_weight import compute_class_weight
import cv2
sns.set_style('darkgrid')
In [2]:
import random random.seed(42) np.random.seed(42) tf.random.set_seed(42) os.environ['PYTHONHASHSEED'] = str(42) os.environ['TF_DETERMINISTIC_OPS'] = '1'
Příprava dat
Definice cest k datům a základních konstant platných pro celý článek:
In [3]:
DATA_ROOT = '/kaggle/input/chest-xray-pneumonia/chest_xray' DATA_TRAIN = os.path.join(DATA_ROOT, "train") DATA_VALID = os.path.join(DATA_ROOT, "val") DATA_TEST = os.path.join(DATA_ROOT, "test") LABELS = ['NORMAL', 'PNEUMONIA'] IMAGE_SIZE = (224, 224) PATCH_SIZE = 16 BATCH_SIZE = 32
Tady je funkce pro načtení obrázků a jejich label z adresářové struktury datové sady. Provádí se konverze do jedné barvy nebo RGB, a také přizpůsobení na jedno rozlišení.
In [4]:
def get_datasource(*data_dirs, flag=cv2.IMREAD_GRAYSCALE):
x, y = list(), list()
for data_dir in data_dirs:
for i, label in enumerate(LABELS):
path = os.path.join(data_dir, label)
target = [0] * len(LABELS)
target[i] = 1
for img in os.listdir(path):
if img.endswith(".jpeg"):
img_arr = cv2.imread(os.path.join(path, img), flag)
resized_arr = cv2.resize(img_arr, IMAGE_SIZE)
x.append(resized_arr)
y.append(target)
return np.array(x) / 255, np.array(y)
A následně si tedy data načtu do interní paměti. Rozdělení na trénovací a validační sadu si udělám následně při trénování v poměru 80:20.
In [5]:
x_train, y_train = get_datasource(DATA_TRAIN, DATA_VALID) x_test, y_test = get_datasource(DATA_TEST) x_train = np.expand_dims(x_train, axis=-1) x_test = np.expand_dims(x_test, axis=-1)
Zde je poněkud jiný přístup k „vylepšení“ obrázků v průběhu trénování. V tomto případě jsem použil aktuálně prosazovanou variantu zařazení těchto kroků do samotného modelu jako jednu z úvodních vrstev. Vytvořím tedy sekvenční model s vrstvami dělajícími právě ty požadované změny:
In [6]:
data_augmentation = keras.Sequential([
layers.Normalization(),
layers.RandomFlip("horizontal"),
layers.RandomRotation(factor=0.2),
layers.RandomZoom(height_factor=0.2, width_factor=0.2),
], name="data_augmentation")
data_augmentation.layers[0].adapt(x_train)
Vrstva pro normalizaci se musí před použitím přizpůsobit konkrétní datové sadě. Proto to volání metody adapt() na první vrstvě modelu.
Framework pro vyhodnocení modelu
Takto vypadá mírně upravený framework pro vyhodnocení modelů. Změnou je především použití jinak nastaveného optimazer pro minimalizaci ztrátové funkce. No a pak je tam ta drobnost s dělením na trénovací a validační sadu.
In [8]:
LEARNING_RATE = 0.001
WEIGHT_DECAY = 0.0001
def evaluate_model(model, *, epochs=40, batch_size=32, forced_training=False):
print(f"=== MODEL EVALUATION =================================================\n")
optimizer = AdamW(learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy', 'AUC'])
model.summary()
MODEL_CHECKPOINT = f"/kaggle/working/model/{model.name}.ckpt"
if not os.path.exists(MODEL_CHECKPOINT) or forced_training:
print(f"\n--- Model training ---------------------------------------------------\n")
shutil.rmtree(MODEL_CHECKPOINT, ignore_errors=True)
callbacks_list = [
keras.callbacks.EarlyStopping(
monitor='val_auc',
patience=10),
keras.callbacks.ModelCheckpoint(
filepath=MODEL_CHECKPOINT,
monitor='val_auc',
save_best_only=True,
mode='max',
verbose=1)
]
history = model.fit(
x=x_train,
y=y_train,
epochs=epochs,
callbacks=callbacks_list,
validation_split=0.2,
verbose=1)
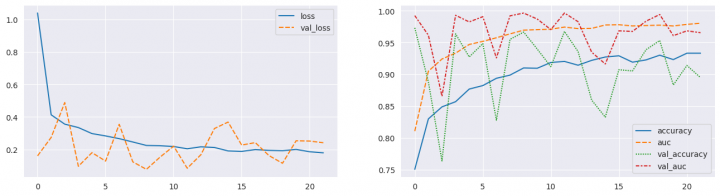
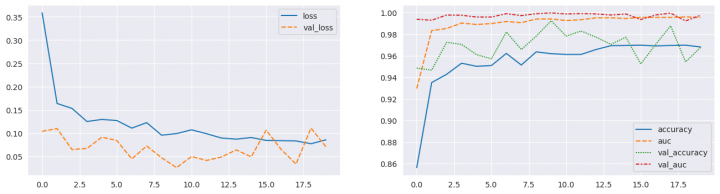
print(f"\n--- Training history -------------------------------------------------\n")
fig, ax = plt.subplots(1, 2, figsize=(16, 4))
sns.lineplot(data={k: history.history[k] for k in ('loss', 'val_loss')}, ax=ax[0])
sns.lineplot(data={k: history.history[k] for k in history.history.keys() if k not in ('loss', 'val_loss')}, ax=ax[1])
plt.show()
else:
print(f"\n--- Model is already trainded ... loading ----------------------------\n")
model.load_weights(MODEL_CHECKPOINT)
print(f"\n--- Test Predictions and Metrics -------------------------------------\n")
y_pred = model.predict(x_test, verbose=0)
plt.figure(figsize=(6, 3))
heatmap = sns.heatmap(confusion_matrix(np.argmax(y_test, axis=-1), np.argmax(y_pred, axis=-1)), annot=True, fmt="d", cbar=True)
heatmap.yaxis.set_ticklabels(LABELS, rotation=90, ha='right')
heatmap.xaxis.set_ticklabels(LABELS, rotation=0, ha='right')
heatmap.axes.set_ylabel('True label')
heatmap.axes.set_xlabel('Predicted label')
plt.show()
print()
print(classification_report(np.argmax(y_test, axis=-1), np.argmax(y_pred, axis=-1), target_names=LABELS, zero_division=0))
print(f"\n=== MODEL EVALUATION FINISHED ========================================")
return y_pred
ViT model z čistého stolu
Nevím jak to máte vy, ale já si každou novou věc potřebuji osahat vlastníma rukama abych pochopil, jak to vlastně funguje. A o tom je primárně tato kapitola.
Originální transformer model vychází z toho, že potřebuje na vstupu sekvenci token. V případě obrázků to autoři navrhli tak, že si původní obrázek rozsekali na malé čtverečky o stejní velikosti (říká se tomu patch). Velikost čtverečku je dána zvolenou konstantou, v mém případě je to 16×16 bodů. Obvykle se to dělá například takto:
In [9]:
class Patches(layers.Layer):
def __init__(self, patch_size, **kwargs):
super().__init__(**kwargs)
self.patch_size = patch_size
def call(self, images):
patches = extract_patches(images=images,
sizes=[1, self.patch_size, self.patch_size, 1],
strides=[1, self.patch_size, self.patch_size, 1],
rates=[1, 1, 1, 1],
padding='VALID')
b = tf.shape(patches)[0]
h = tf.shape(patches)[1]
w = tf.shape(patches)[2]
p = tf.shape(patches)[3]
return tf.reshape(patches, (b, h * w, p))
def get_config(self):
config = super().get_config()
config.update({"patch_size": self.patch_size})
return config
Pro lepší představu, takhle vypadá výsledek rozsekání:
In [10]:
patches = Patches(PATCH_SIZE)(x_test)
In [11]:
plt.figure(figsize=(4, 4))
image = x_test[0]*255.
plt.imshow((image).astype("uint8"), cmap='gray')
plt.axis("off")
Out[11]:
(-0.5, 223.5, 223.5, -0.5)
In [12]:
n = int(np.sqrt(patches.shape[1]))
plt.figure(figsize=(4, 4))
for i, patch in enumerate(patches[0].numpy()):
ax = plt.subplot(n, n, i + 1)
patch *= 255.
patch_img = patch.reshape((PATCH_SIZE, PATCH_SIZE, 1))
plt.imshow(patch_img.astype("uint8"), cmap='gray')
plt.axis("off")
plt.show()
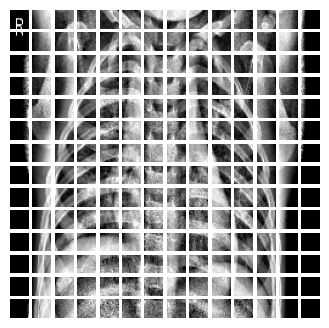
Jestli vám stejně jako mně připadá, že se změnily odstíny šedi, tak vězte, že to je optický klam způsobený těmi bílými rámečky. Kontroloval jsem to.
Z jednoho obrázku tak vznikne sekvence patchů.
Druhým krokem je lineární projekce těchto patchů do interní reprezentace. Konkrétně v mém případě je každý patch velký 256 dimenzí (můžete si to představit jako vektor). A ten je projektován na vektor o 64 dimenzích. Navíc se ještě pro každý patch vezme jeho pořadové číslo v sekvenci, a to je opět projektováno do 64 dimenzionálního vektoru. No a na závěr se oba tyto vektory sečtou. Jen pro upřesnění, projekce patch i jejich pořadových čísel je předmětem učení, takže by se měly optimálně nastavit při trénování sítě.
Takto by mohla vypadat implementace takové vrstvy:
In [13]:
class PatchEncoder(layers.Layer):
def __init__(self, projection_dim, **kwargs):
super().__init__(**kwargs)
self.projection_dim = projection_dim
def build(self, input_shape):
self.patches = input_shape[-2]
self.projection = layers.Dense(units=self.projection_dim)
self.position_embedding = layers.Embedding(input_dim=self.patches, output_dim=self.projection_dim)
def call(self, patch):
projected = self.projection(patch);
encoded = self.position_embedding(np.expand_dims(np.arange(0, self.patches), axis=0))
return projected + encoded
def get_config(self):
config = super().get_config()
config.update({"projection_dim": self.projection_dim})
return config
Nyní se již dostávám k implementaci samotného modelu. Asi nejdříve ukážu zdrojový text, a pak několik poznámek k němu:
In [14]:
PROJECTION_DIMENSION = 64
ATTENTION_HEADS = 4
TRANSFORMER_LAYERS = 8
TRANSFORMER_UNITS = [
PROJECTION_DIMENSION * 2,
PROJECTION_DIMENSION,
]
MLP_HEAD_UNITS = [1024, 512]
def create_model_ViT(X_shape, classes=2, name="ViT"):
def mlp(x, hidden_units, dropout_rate=0.3, name=""):
for i, units in enumerate(hidden_units):
x = layers.Dense(units, activation=keras.activations.gelu, name=f"{name}_{i}_dense")(x)
x = layers.Dropout(dropout_rate, name=f"{name}_{i}_dropout")(x)
return x
inputs = layers.Input(X_shape[-3:], name='inputs')
augmented = data_augmentation(inputs)
patches = Patches(PATCH_SIZE, name=f'patches')(augmented)
encoded_patches = PatchEncoder(PROJECTION_DIMENSION, name=f'patch_encoder')(patches)
for i in range(TRANSFORMER_LAYERS):
x1 = layers.LayerNormalization(epsilon=1e-6, name=f"normalization_a_{i}")(encoded_patches)
attention_output = layers.MultiHeadAttention(
num_heads=ATTENTION_HEADS,
key_dim=PROJECTION_DIMENSION,
dropout=0.1,
name=f"multihead_attention_{i}"
)(x1, x1)
x2 = layers.Add(name=f"skip_a_{i}")([attention_output , encoded_patches])
x3 = layers.LayerNormalization(epsilon=1e-6, name=f"normalization_b_{i}")(x2)
x3 = mlp(x3, hidden_units=TRANSFORMER_UNITS, dropout_rate=0.1, name=f"mlp_{i}")
encoded_patches = layers.Add(name=f"skip_b_{i}")([x3, x2])
representation = layers.LayerNormalization(epsilon=1e-6, name=f"representation_norm")(encoded_patches)
representation = layers.Flatten(name=f"representation_flatten")(representation)
representation = layers.Dropout(0.5, name="representation_dropout")(representation)
x = mlp(representation, MLP_HEAD_UNITS, name="dense")
outputs = layers.Dense(classes, activation='softmax', name='outputs')(x)
return Model(inputs=inputs, outputs=outputs, name=name)
V tomto modelu již žádnou konvoluci nenajdete. Vše je primárně postaveno na Multi-head Self Attention vrstvách.
Pokud se podíváte na implementaci, pak postupně uvidíte:
-
Úvodní vrstvu pro přizpůsobení obrázků před učením (viz. sekvenční model data_augmentation v sekci o přípravě dat)
-
Následně se z obrázku udělá sekvence patchů
-
V dalším kroku jsou patche převedeny do interní reprezentace včetně zakódování jejich pozice v sekvenci (interní reprezentace PROJECTION_DIMENSION).
-
Dostávám se k jádru celého modelu – posloupnost transformer bloků (v mém případě jich bude TRANSFORER_LAYERS)
-
V každém bloku se nejdříve udělá normalizace v rámci batch
-
Následuje MultiHeadAttention vrstva s počtem ATTENTION_HEADS hlav a velikosti klíče i hodnoty odpovídající interní reprezentaci PROJECTION_DIMENSION. Jedná se o self-attention, takže vstupy pro dotaz i klíč jsou stejné vektory.
-
Dále se přidá reziduální cesta pro tok původního vektoru (tady odkazuji na modely ResNet)
-
Dalším krokem je normalizace a MLP vrstva. V té jsou vektory postupně rozšířeny na dvojnásobnou velikost, aby byly v zapěti opět transformovány zpět do velikosti PROJECTION_DIMENSION. Za zmínku stojí i použití aktivační funkce GELU.
-
A na závěr se opět doplňuje reziduální zkratka před MLP vrstvy.
-
-
Celý model je pak zakončen již obvyklou sekvencí. Provede se normalizace, převedení do jednoho rozměru v rámci batch (vrstva Flatten), následuje několik plně propojených vrstev, a na závěr klasifikační vrstva s aktivací softmax.
-
A to je vše.
Rovnou si to můžu vyzkoušet:
In [15]:
y_pred = evaluate_model(create_model_ViT(x_train.shape, 2), forced_training=True)
=== MODEL EVALUATION =================================================
Model: "ViT"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
inputs (InputLayer) [(None, 224, 224, 1)] 0 []
data_augmentation (Sequent (None, 224, 224, 1) 3 ['inputs[0][0]']
ial)
patches (Patches) (None, 196, 256) 0 ['data_augmentation[0][0]']
patch_encoder (PatchEncode (None, 196, 64) 28992 ['patches[0][0]']
r)
normalization_a_0 (LayerNo (None, 196, 64) 128 ['patch_encoder[0][0]']
rmalization)
multihead_attention_0 (Mul (None, 196, 64) 66368 ['normalization_a_0[0][0]',
tiHeadAttention) 'normalization_a_0[0][0]']
skip_a_0 (Add) (None, 196, 64) 0 ['multihead_attention_0[0][0]'
, 'patch_encoder[0][0]']
normalization_b_0 (LayerNo (None, 196, 64) 128 ['skip_a_0[0][0]']
rmalization)
mlp_0_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_0[0][0]']
mlp_0_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_0_0_dense[0][0]']
mlp_0_1_dense (Dense) (None, 196, 64) 8256 ['mlp_0_0_dropout[0][0]']
mlp_0_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_0_1_dense[0][0]']
skip_b_0 (Add) (None, 196, 64) 0 ['mlp_0_1_dropout[0][0]',
'skip_a_0[0][0]']
normalization_a_1 (LayerNo (None, 196, 64) 128 ['skip_b_0[0][0]']
rmalization)
multihead_attention_1 (Mul (None, 196, 64) 66368 ['normalization_a_1[0][0]',
tiHeadAttention) 'normalization_a_1[0][0]']
skip_a_1 (Add) (None, 196, 64) 0 ['multihead_attention_1[0][0]'
, 'skip_b_0[0][0]']
normalization_b_1 (LayerNo (None, 196, 64) 128 ['skip_a_1[0][0]']
rmalization)
mlp_1_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_1[0][0]']
mlp_1_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_1_0_dense[0][0]']
mlp_1_1_dense (Dense) (None, 196, 64) 8256 ['mlp_1_0_dropout[0][0]']
mlp_1_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_1_1_dense[0][0]']
skip_b_1 (Add) (None, 196, 64) 0 ['mlp_1_1_dropout[0][0]',
'skip_a_1[0][0]']
normalization_a_2 (LayerNo (None, 196, 64) 128 ['skip_b_1[0][0]']
rmalization)
multihead_attention_2 (Mul (None, 196, 64) 66368 ['normalization_a_2[0][0]',
tiHeadAttention) 'normalization_a_2[0][0]']
skip_a_2 (Add) (None, 196, 64) 0 ['multihead_attention_2[0][0]'
, 'skip_b_1[0][0]']
normalization_b_2 (LayerNo (None, 196, 64) 128 ['skip_a_2[0][0]']
rmalization)
mlp_2_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_2[0][0]']
mlp_2_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_2_0_dense[0][0]']
mlp_2_1_dense (Dense) (None, 196, 64) 8256 ['mlp_2_0_dropout[0][0]']
mlp_2_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_2_1_dense[0][0]']
skip_b_2 (Add) (None, 196, 64) 0 ['mlp_2_1_dropout[0][0]',
'skip_a_2[0][0]']
normalization_a_3 (LayerNo (None, 196, 64) 128 ['skip_b_2[0][0]']
rmalization)
multihead_attention_3 (Mul (None, 196, 64) 66368 ['normalization_a_3[0][0]',
tiHeadAttention) 'normalization_a_3[0][0]']
skip_a_3 (Add) (None, 196, 64) 0 ['multihead_attention_3[0][0]'
, 'skip_b_2[0][0]']
normalization_b_3 (LayerNo (None, 196, 64) 128 ['skip_a_3[0][0]']
rmalization)
mlp_3_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_3[0][0]']
mlp_3_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_3_0_dense[0][0]']
mlp_3_1_dense (Dense) (None, 196, 64) 8256 ['mlp_3_0_dropout[0][0]']
mlp_3_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_3_1_dense[0][0]']
skip_b_3 (Add) (None, 196, 64) 0 ['mlp_3_1_dropout[0][0]',
'skip_a_3[0][0]']
normalization_a_4 (LayerNo (None, 196, 64) 128 ['skip_b_3[0][0]']
rmalization)
multihead_attention_4 (Mul (None, 196, 64) 66368 ['normalization_a_4[0][0]',
tiHeadAttention) 'normalization_a_4[0][0]']
skip_a_4 (Add) (None, 196, 64) 0 ['multihead_attention_4[0][0]'
, 'skip_b_3[0][0]']
normalization_b_4 (LayerNo (None, 196, 64) 128 ['skip_a_4[0][0]']
rmalization)
mlp_4_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_4[0][0]']
mlp_4_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_4_0_dense[0][0]']
mlp_4_1_dense (Dense) (None, 196, 64) 8256 ['mlp_4_0_dropout[0][0]']
mlp_4_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_4_1_dense[0][0]']
skip_b_4 (Add) (None, 196, 64) 0 ['mlp_4_1_dropout[0][0]',
'skip_a_4[0][0]']
normalization_a_5 (LayerNo (None, 196, 64) 128 ['skip_b_4[0][0]']
rmalization)
multihead_attention_5 (Mul (None, 196, 64) 66368 ['normalization_a_5[0][0]',
tiHeadAttention) 'normalization_a_5[0][0]']
skip_a_5 (Add) (None, 196, 64) 0 ['multihead_attention_5[0][0]'
, 'skip_b_4[0][0]']
normalization_b_5 (LayerNo (None, 196, 64) 128 ['skip_a_5[0][0]']
rmalization)
mlp_5_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_5[0][0]']
mlp_5_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_5_0_dense[0][0]']
mlp_5_1_dense (Dense) (None, 196, 64) 8256 ['mlp_5_0_dropout[0][0]']
mlp_5_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_5_1_dense[0][0]']
skip_b_5 (Add) (None, 196, 64) 0 ['mlp_5_1_dropout[0][0]',
'skip_a_5[0][0]']
normalization_a_6 (LayerNo (None, 196, 64) 128 ['skip_b_5[0][0]']
rmalization)
multihead_attention_6 (Mul (None, 196, 64) 66368 ['normalization_a_6[0][0]',
tiHeadAttention) 'normalization_a_6[0][0]']
skip_a_6 (Add) (None, 196, 64) 0 ['multihead_attention_6[0][0]'
, 'skip_b_5[0][0]']
normalization_b_6 (LayerNo (None, 196, 64) 128 ['skip_a_6[0][0]']
rmalization)
mlp_6_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_6[0][0]']
mlp_6_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_6_0_dense[0][0]']
mlp_6_1_dense (Dense) (None, 196, 64) 8256 ['mlp_6_0_dropout[0][0]']
mlp_6_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_6_1_dense[0][0]']
skip_b_6 (Add) (None, 196, 64) 0 ['mlp_6_1_dropout[0][0]',
'skip_a_6[0][0]']
normalization_a_7 (LayerNo (None, 196, 64) 128 ['skip_b_6[0][0]']
rmalization)
multihead_attention_7 (Mul (None, 196, 64) 66368 ['normalization_a_7[0][0]',
tiHeadAttention) 'normalization_a_7[0][0]']
skip_a_7 (Add) (None, 196, 64) 0 ['multihead_attention_7[0][0]'
, 'skip_b_6[0][0]']
normalization_b_7 (LayerNo (None, 196, 64) 128 ['skip_a_7[0][0]']
rmalization)
mlp_7_0_dense (Dense) (None, 196, 128) 8320 ['normalization_b_7[0][0]']
mlp_7_0_dropout (Dropout) (None, 196, 128) 0 ['mlp_7_0_dense[0][0]']
mlp_7_1_dense (Dense) (None, 196, 64) 8256 ['mlp_7_0_dropout[0][0]']
mlp_7_1_dropout (Dropout) (None, 196, 64) 0 ['mlp_7_1_dense[0][0]']
skip_b_7 (Add) (None, 196, 64) 0 ['mlp_7_1_dropout[0][0]',
'skip_a_7[0][0]']
representation_norm (Layer (None, 196, 64) 128 ['skip_b_7[0][0]']
Normalization)
representation_flatten (Fl (None, 12544) 0 ['representation_norm[0][0]']
atten)
representation_dropout (Dr (None, 12544) 0 ['representation_flatten[0][0]
opout) ']
dense_0_dense (Dense) (None, 1024) 1284608 ['representation_dropout[0][0]
0 ']
dense_0_dropout (Dropout) (None, 1024) 0 ['dense_0_dense[0][0]']
dense_1_dense (Dense) (None, 512) 524800 ['dense_0_dropout[0][0]']
dense_1_dropout (Dropout) (None, 512) 0 ['dense_1_dense[0][0]']
outputs (Dense) (None, 2) 1026 ['dense_1_dropout[0][0]']
==================================================================================================
Total params: 14066629 (53.66 MB)
Trainable params: 14066626 (53.66 MB)
Non-trainable params: 3 (16.00 Byte)
__________________________________________________________________________________________________
--- Model training ---------------------------------------------------
Epoch 1/40
131/131 [==============================] - ETA: 0s - loss: 1.0398 - accuracy: 0.7508 - auc: 0.8108
Epoch 1: val_auc improved from -inf to 0.99240, saving model to /kaggle/working/model/ViT.ckpt
131/131 [==============================] - 58s 217ms/step - loss: 1.0398 - accuracy: 0.7508 - auc: 0.8108 - val_loss: 0.1607 - val_accuracy: 0.9733 - val_auc: 0.9924
Epoch 2/40
131/131 [==============================] - ETA: 0s - loss: 0.4132 - accuracy: 0.8301 - auc: 0.9050
Epoch 2: val_auc did not improve from 0.99240
131/131 [==============================] - 10s 74ms/step - loss: 0.4132 - accuracy: 0.8301 - auc: 0.9050 - val_loss: 0.2742 - val_accuracy: 0.8883 - val_auc: 0.9616
Epoch 3/40
131/131 [==============================] - ETA: 0s - loss: 0.3558 - accuracy: 0.8490 - auc: 0.9242
Epoch 3: val_auc did not improve from 0.99240
131/131 [==============================] - 10s 74ms/step - loss: 0.3558 - accuracy: 0.8490 - auc: 0.9242 - val_loss: 0.4887 - val_accuracy: 0.7641 - val_auc: 0.8657
Epoch 4/40
131/131 [==============================] - ETA: 0s - loss: 0.3348 - accuracy: 0.8571 - auc: 0.9334
Epoch 4: val_auc improved from 0.99240 to 0.99294, saving model to /kaggle/working/model/ViT.ckpt
131/131 [==============================] - 25s 193ms/step - loss: 0.3348 - accuracy: 0.8571 - auc: 0.9334 - val_loss: 0.0967 - val_accuracy: 0.9637 - val_auc: 0.9929
Epoch 5/40
131/131 [==============================] - ETA: 0s - loss: 0.2978 - accuracy: 0.8769 - auc: 0.9470
Epoch 5: val_auc did not improve from 0.99294
131/131 [==============================] - 10s 74ms/step - loss: 0.2978 - accuracy: 0.8769 - auc: 0.9470 - val_loss: 0.1804 - val_accuracy: 0.9274 - val_auc: 0.9825
Epoch 6/40
131/131 [==============================] - ETA: 0s - loss: 0.2834 - accuracy: 0.8824 - auc: 0.9519
Epoch 6: val_auc did not improve from 0.99294
131/131 [==============================] - 10s 75ms/step - loss: 0.2834 - accuracy: 0.8824 - auc: 0.9519 - val_loss: 0.1286 - val_accuracy: 0.9484 - val_auc: 0.9908
Epoch 7/40
131/131 [==============================] - ETA: 0s - loss: 0.2666 - accuracy: 0.8939 - auc: 0.9576
Epoch 7: val_auc did not improve from 0.99294
131/131 [==============================] - 10s 74ms/step - loss: 0.2666 - accuracy: 0.8939 - auc: 0.9576 - val_loss: 0.3550 - val_accuracy: 0.8281 - val_auc: 0.9260
Epoch 8/40
131/131 [==============================] - ETA: 0s - loss: 0.2461 - accuracy: 0.8989 - auc: 0.9637
Epoch 8: val_auc did not improve from 0.99294
131/131 [==============================] - 10s 74ms/step - loss: 0.2461 - accuracy: 0.8989 - auc: 0.9637 - val_loss: 0.1238 - val_accuracy: 0.9551 - val_auc: 0.9921
Epoch 9/40
131/131 [==============================] - ETA: 0s - loss: 0.2247 - accuracy: 0.9102 - auc: 0.9696
Epoch 9: val_auc improved from 0.99294 to 0.99643, saving model to /kaggle/working/model/ViT.ckpt
131/131 [==============================] - 25s 195ms/step - loss: 0.2247 - accuracy: 0.9102 - auc: 0.9696 - val_loss: 0.0777 - val_accuracy: 0.9666 - val_auc: 0.9964
Epoch 10/40
131/131 [==============================] - ETA: 0s - loss: 0.2230 - accuracy: 0.9097 - auc: 0.9704
Epoch 10: val_auc did not improve from 0.99643
131/131 [==============================] - 10s 74ms/step - loss: 0.2230 - accuracy: 0.9097 - auc: 0.9704 - val_loss: 0.1530 - val_accuracy: 0.9398 - val_auc: 0.9870
Epoch 11/40
131/131 [==============================] - ETA: 0s - loss: 0.2184 - accuracy: 0.9188 - auc: 0.9711
Epoch 11: val_auc did not improve from 0.99643
131/131 [==============================] - 10s 75ms/step - loss: 0.2184 - accuracy: 0.9188 - auc: 0.9711 - val_loss: 0.2205 - val_accuracy: 0.9121 - val_auc: 0.9704
Epoch 12/40
131/131 [==============================] - ETA: 0s - loss: 0.2044 - accuracy: 0.9204 - auc: 0.9744
Epoch 12: val_auc improved from 0.99643 to 0.99653, saving model to /kaggle/working/model/ViT.ckpt
131/131 [==============================] - 25s 193ms/step - loss: 0.2044 - accuracy: 0.9204 - auc: 0.9744 - val_loss: 0.0845 - val_accuracy: 0.9675 - val_auc: 0.9965
Epoch 13/40
131/131 [==============================] - ETA: 0s - loss: 0.2164 - accuracy: 0.9145 - auc: 0.9720
Epoch 13: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 75ms/step - loss: 0.2164 - accuracy: 0.9145 - auc: 0.9720 - val_loss: 0.1675 - val_accuracy: 0.9360 - val_auc: 0.9828
Epoch 14/40
131/131 [==============================] - ETA: 0s - loss: 0.2124 - accuracy: 0.9221 - auc: 0.9724
Epoch 14: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 74ms/step - loss: 0.2124 - accuracy: 0.9221 - auc: 0.9724 - val_loss: 0.3291 - val_accuracy: 0.8596 - val_auc: 0.9350
Epoch 15/40
131/131 [==============================] - ETA: 0s - loss: 0.1911 - accuracy: 0.9274 - auc: 0.9777
Epoch 15: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 74ms/step - loss: 0.1911 - accuracy: 0.9274 - auc: 0.9777 - val_loss: 0.3687 - val_accuracy: 0.8329 - val_auc: 0.9164
Epoch 16/40
131/131 [==============================] - ETA: 0s - loss: 0.1882 - accuracy: 0.9293 - auc: 0.9781
Epoch 16: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 75ms/step - loss: 0.1882 - accuracy: 0.9293 - auc: 0.9781 - val_loss: 0.2271 - val_accuracy: 0.9074 - val_auc: 0.9685
Epoch 17/40
131/131 [==============================] - ETA: 0s - loss: 0.1993 - accuracy: 0.9192 - auc: 0.9762
Epoch 17: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 74ms/step - loss: 0.1993 - accuracy: 0.9192 - auc: 0.9762 - val_loss: 0.2424 - val_accuracy: 0.9054 - val_auc: 0.9676
Epoch 18/40
131/131 [==============================] - ETA: 0s - loss: 0.1945 - accuracy: 0.9228 - auc: 0.9768
Epoch 18: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 74ms/step - loss: 0.1945 - accuracy: 0.9228 - auc: 0.9768 - val_loss: 0.1629 - val_accuracy: 0.9389 - val_auc: 0.9838
Epoch 19/40
131/131 [==============================] - ETA: 0s - loss: 0.1923 - accuracy: 0.9302 - auc: 0.9774
Epoch 19: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 75ms/step - loss: 0.1923 - accuracy: 0.9302 - auc: 0.9774 - val_loss: 0.1151 - val_accuracy: 0.9532 - val_auc: 0.9941
Epoch 20/40
131/131 [==============================] - ETA: 0s - loss: 0.2003 - accuracy: 0.9233 - auc: 0.9761
Epoch 20: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 74ms/step - loss: 0.2003 - accuracy: 0.9233 - auc: 0.9761 - val_loss: 0.2535 - val_accuracy: 0.8835 - val_auc: 0.9609
Epoch 21/40
131/131 [==============================] - ETA: 0s - loss: 0.1861 - accuracy: 0.9333 - auc: 0.9786
Epoch 21: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 74ms/step - loss: 0.1861 - accuracy: 0.9333 - auc: 0.9786 - val_loss: 0.2518 - val_accuracy: 0.9140 - val_auc: 0.9685
Epoch 22/40
131/131 [==============================] - ETA: 0s - loss: 0.1793 - accuracy: 0.9333 - auc: 0.9805
Epoch 22: val_auc did not improve from 0.99653
131/131 [==============================] - 10s 78ms/step - loss: 0.1793 - accuracy: 0.9333 - auc: 0.9805 - val_loss: 0.2415 - val_accuracy: 0.8949 - val_auc: 0.9656
--- Training history -------------------------------------------------
--- Test Predictions and Metrics -------------------------------------
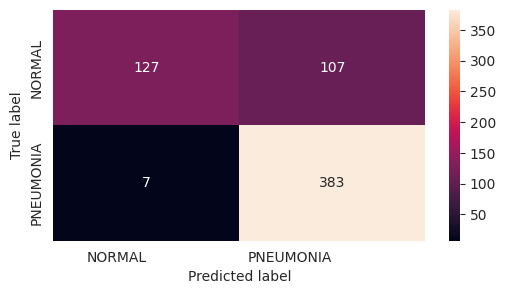
precision recall f1-score support
NORMAL 0.95 0.54 0.69 234
PNEUMONIA 0.78 0.98 0.87 390
accuracy 0.82 624
macro avg 0.86 0.76 0.78 624
weighted avg 0.84 0.82 0.80 624
=== MODEL EVALUATION FINISHED ========================================
ViT model – Transfer Learning
V rychlejším tempu si vyzkouším i variantu, kdy zkusím použít již dříve trénovaný model na jiné datové sadě. V tomto případě jsem musel sáhnou pro model z produkce Google: Vision Transformer and MLP-Mixer Architectures
Takže potřebuji doinstalovat balíček:
In [16]:
!pip install vit-keras Collecting vit-keras Downloading vit_keras-0.1.2-py3-none-any.whl (24 kB) Requirement already satisfied: scipy in /opt/conda/lib/python3.10/site-packages (from vit-keras) (1.11.4) Collecting validators (from vit-keras) Obtaining dependency information for validators from https://files.pythonhosted.org/packages/3a/0c/785d317eea99c3739821718f118c70537639aa43f96bfa1d83a71f68eaf6/validators-0.22.0-py3-none-any.whl.metadata Downloading validators-0.22.0-py3-none-any.whl.metadata (4.7 kB) Requirement already satisfied: numpy<1.28.0,>=1.21.6 in /opt/conda/lib/python3.10/site-packages (from scipy->vit-keras) (1.24.3) Downloading validators-0.22.0-py3-none-any.whl (26 kB) Installing collected packages: validators, vit-keras Successfully installed validators-0.22.0 vit-keras-0.1.2
In [17]:
from vit_keras import vit
Připravím si zdrojová dat. Jako již obvykle budu muset načítat jako RGB snímky, neboť právě tak je základní model trénován:
In [18]:
x_train, y_train = get_datasource(DATA_TRAIN, DATA_VALID, flag=cv2.IMREAD_COLOR)
x_test, y_test = get_datasource(DATA_TEST, flag=cv2.IMREAD_COLOR)
data_augmentation = keras.Sequential([
layers.Normalization(),
layers.RandomFlip("horizontal"),
layers.RandomRotation(factor=0.2),
layers.RandomZoom(height_factor=0.2, width_factor=0.2),
], name="data_augmentation")
data_augmentation.layers[0].adapt(x_train)
A takto by mohl vypadat samotný model vycházející z Base16 modelu. Základní model je doplněn o MLP a klasifikační vrstvu:
In [19]:
def create_model_ViTTrans(X_shape, classes=2, name="ViTTrans"):
def mlp(x, hidden_units, activation='relu', dropout_rate=0.3, name=""):
for i, units in enumerate(hidden_units):
x = layers.Dense(units, activation=activation, name=f"{name}_{i}_dense")(x)
x = layers.Dropout(dropout_rate, name=f"{name}_{i}_dropout")(x)
return x
base_model = vit.vit_b16(image_size=IMAGE_SIZE, include_top=False, pretrained_top=False)
base_model.trainable = False
inputs = Input(X_shape[-3:], name='inputs')
x = base_model(inputs, training=False)
# x = layers.GlobalAveragePooling2D(name=f"global_average")(x)
x = mlp(x, (1024, 512), name="dense")
outputs = layers.Dense(classes, activation='softmax', name='outputs')(x)
return Model(inputs=inputs, outputs=outputs, name=name)
Na závěr vyhodnocení toho, jak mně takový model zafungoval na konkrétní datové sadě:
In [20]:
y_pred = evaluate_model(create_model_ViTTrans(x_train.shape, 2), forced_training=True) Downloading data from https://github.com/faustomorales/vit-keras/releases/download/dl/ViT-B_16_imagenet21k+imagenet2012.npz 347502902/347502902 [==============================] - 11s 0us/step /opt/conda/lib/python3.10/site-packages/vit_keras/utils.py:81: UserWarning: Resizing position embeddings from 24, 24 to 14, 14 warnings.warn( === MODEL EVALUATION ================================================= Model: "ViTTrans" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= inputs (InputLayer) [(None, 224, 224, 3)] 0 vit-b16 (Functional) (None, 768) 85798656 dense_0_dense (Dense) (None, 1024) 787456 dense_0_dropout (Dropout) (None, 1024) 0 dense_1_dense (Dense) (None, 512) 524800 dense_1_dropout (Dropout) (None, 512) 0 outputs (Dense) (None, 2) 1026 ================================================================= Total params: 87111938 (332.31 MB) Trainable params: 1313282 (5.01 MB) Non-trainable params: 85798656 (327.30 MB) _________________________________________________________________ --- Model training --------------------------------------------------- Epoch 1/40 131/131 [==============================] - ETA: 0s - loss: 0.3584 - accuracy: 0.8562 - auc: 0.9295 Epoch 1: val_auc improved from -inf to 0.99368, saving model to /kaggle/working/model/ViTTrans.ckpt 131/131 [==============================] - 87s 556ms/step - loss: 0.3584 - accuracy: 0.8562 - auc: 0.9295 - val_loss: 0.1037 - val_accuracy: 0.9484 - val_auc: 0.9937 Epoch 2/40 131/131 [==============================] - ETA: 0s - loss: 0.1637 - accuracy: 0.9350 - auc: 0.9832 Epoch 2: val_auc did not improve from 0.99368 131/131 [==============================] - 42s 320ms/step - loss: 0.1637 - accuracy: 0.9350 - auc: 0.9832 - val_loss: 0.1097 - val_accuracy: 0.9465 - val_auc: 0.9928 Epoch 3/40 131/131 [==============================] - ETA: 0s - loss: 0.1530 - accuracy: 0.9427 - auc: 0.9851 Epoch 3: val_auc improved from 0.99368 to 0.99759, saving model to /kaggle/working/model/ViTTrans.ckpt 131/131 [==============================] - 68s 523ms/step - loss: 0.1530 - accuracy: 0.9427 - auc: 0.9851 - val_loss: 0.0646 - val_accuracy: 0.9723 - val_auc: 0.9976 Epoch 4/40 131/131 [==============================] - ETA: 0s - loss: 0.1248 - accuracy: 0.9529 - auc: 0.9902 Epoch 4: val_auc did not improve from 0.99759 131/131 [==============================] - 42s 320ms/step - loss: 0.1248 - accuracy: 0.9529 - auc: 0.9902 - val_loss: 0.0670 - val_accuracy: 0.9704 - val_auc: 0.9974 Epoch 5/40 131/131 [==============================] - ETA: 0s - loss: 0.1293 - accuracy: 0.9501 - auc: 0.9888 Epoch 5: val_auc did not improve from 0.99759 131/131 [==============================] - 42s 319ms/step - loss: 0.1293 - accuracy: 0.9501 - auc: 0.9888 - val_loss: 0.0911 - val_accuracy: 0.9608 - val_auc: 0.9957 Epoch 6/40 131/131 [==============================] - ETA: 0s - loss: 0.1269 - accuracy: 0.9508 - auc: 0.9897 Epoch 6: val_auc did not improve from 0.99759 131/131 [==============================] - 42s 320ms/step - loss: 0.1269 - accuracy: 0.9508 - auc: 0.9897 - val_loss: 0.0839 - val_accuracy: 0.9570 - val_auc: 0.9957 Epoch 7/40 131/131 [==============================] - ETA: 0s - loss: 0.1106 - accuracy: 0.9620 - auc: 0.9916 Epoch 7: val_auc improved from 0.99759 to 0.99888, saving model to /kaggle/working/model/ViTTrans.ckpt 131/131 [==============================] - 68s 519ms/step - loss: 0.1106 - accuracy: 0.9620 - auc: 0.9916 - val_loss: 0.0445 - val_accuracy: 0.9819 - val_auc: 0.9989 Epoch 8/40 131/131 [==============================] - ETA: 0s - loss: 0.1223 - accuracy: 0.9513 - auc: 0.9905 Epoch 8: val_auc did not improve from 0.99888 131/131 [==============================] - 43s 325ms/step - loss: 0.1223 - accuracy: 0.9513 - auc: 0.9905 - val_loss: 0.0722 - val_accuracy: 0.9656 - val_auc: 0.9970 Epoch 9/40 131/131 [==============================] - ETA: 0s - loss: 0.0954 - accuracy: 0.9634 - auc: 0.9939 Epoch 9: val_auc did not improve from 0.99888 131/131 [==============================] - 42s 322ms/step - loss: 0.0954 - accuracy: 0.9634 - auc: 0.9939 - val_loss: 0.0469 - val_accuracy: 0.9780 - val_auc: 0.9989 Epoch 10/40 131/131 [==============================] - ETA: 0s - loss: 0.0989 - accuracy: 0.9618 - auc: 0.9939 Epoch 10: val_auc improved from 0.99888 to 0.99959, saving model to /kaggle/working/model/ViTTrans.ckpt 131/131 [==============================] - 68s 523ms/step - loss: 0.0989 - accuracy: 0.9618 - auc: 0.9939 - val_loss: 0.0256 - val_accuracy: 0.9924 - val_auc: 0.9996 Epoch 11/40 131/131 [==============================] - ETA: 0s - loss: 0.1069 - accuracy: 0.9611 - auc: 0.9925 Epoch 11: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 322ms/step - loss: 0.1069 - accuracy: 0.9611 - auc: 0.9925 - val_loss: 0.0495 - val_accuracy: 0.9780 - val_auc: 0.9986 Epoch 12/40 131/131 [==============================] - ETA: 0s - loss: 0.0987 - accuracy: 0.9611 - auc: 0.9932 Epoch 12: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 322ms/step - loss: 0.0987 - accuracy: 0.9611 - auc: 0.9932 - val_loss: 0.0410 - val_accuracy: 0.9828 - val_auc: 0.9990 Epoch 13/40 131/131 [==============================] - ETA: 0s - loss: 0.0893 - accuracy: 0.9656 - auc: 0.9950 Epoch 13: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 322ms/step - loss: 0.0893 - accuracy: 0.9656 - auc: 0.9950 - val_loss: 0.0484 - val_accuracy: 0.9771 - val_auc: 0.9986 Epoch 14/40 131/131 [==============================] - ETA: 0s - loss: 0.0869 - accuracy: 0.9692 - auc: 0.9950 Epoch 14: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 323ms/step - loss: 0.0869 - accuracy: 0.9692 - auc: 0.9950 - val_loss: 0.0638 - val_accuracy: 0.9704 - val_auc: 0.9976 Epoch 15/40 131/131 [==============================] - ETA: 0s - loss: 0.0904 - accuracy: 0.9694 - auc: 0.9943 Epoch 15: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 323ms/step - loss: 0.0904 - accuracy: 0.9694 - auc: 0.9943 - val_loss: 0.0488 - val_accuracy: 0.9771 - val_auc: 0.9986 Epoch 16/40 131/131 [==============================] - ETA: 0s - loss: 0.0842 - accuracy: 0.9697 - auc: 0.9954 Epoch 16: val_auc did not improve from 0.99959 131/131 [==============================] - 44s 336ms/step - loss: 0.0842 - accuracy: 0.9697 - auc: 0.9954 - val_loss: 0.1063 - val_accuracy: 0.9522 - val_auc: 0.9934 Epoch 17/40 131/131 [==============================] - ETA: 0s - loss: 0.0836 - accuracy: 0.9689 - auc: 0.9954 Epoch 17: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 322ms/step - loss: 0.0836 - accuracy: 0.9689 - auc: 0.9954 - val_loss: 0.0649 - val_accuracy: 0.9704 - val_auc: 0.9977 Epoch 18/40 131/131 [==============================] - ETA: 0s - loss: 0.0831 - accuracy: 0.9694 - auc: 0.9953 Epoch 18: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 323ms/step - loss: 0.0831 - accuracy: 0.9694 - auc: 0.9953 - val_loss: 0.0333 - val_accuracy: 0.9876 - val_auc: 0.9994 Epoch 19/40 131/131 [==============================] - ETA: 0s - loss: 0.0770 - accuracy: 0.9697 - auc: 0.9959 Epoch 19: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 322ms/step - loss: 0.0770 - accuracy: 0.9697 - auc: 0.9959 - val_loss: 0.1107 - val_accuracy: 0.9542 - val_auc: 0.9921 Epoch 20/40 131/131 [==============================] - ETA: 0s - loss: 0.0854 - accuracy: 0.9680 - auc: 0.9952 Epoch 20: val_auc did not improve from 0.99959 131/131 [==============================] - 42s 322ms/step - loss: 0.0854 - accuracy: 0.9680 - auc: 0.9952 - val_loss: 0.0706 - val_accuracy: 0.9675 - val_auc: 0.9973 --- Training history -------------------------------------------------
--- Test Predictions and Metrics -------------------------------------
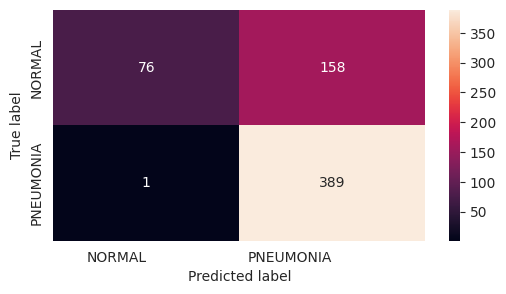
precision recall f1-score support
NORMAL 0.99 0.32 0.49 234
PNEUMONIA 0.71 1.00 0.83 390
accuracy 0.75 624
macro avg 0.85 0.66 0.66 624
weighted avg 0.81 0.75 0.70 624
=== MODEL EVALUATION FINISHED ========================================
-

Ano musím uznat, že sepsání článku a celkově vysvětlení je super.
Jen mě osobně děsí, že by rtg snímek popisoval bohužel program....
Myslím si, že XXX variant co všechno tam může být a pro program je to sněď bílého, šedého a černého. Nic víc... V tomhle by možná, ale opravdu možná mohla uspět AI, kdy dostane databázi nemocních snímku třeba z nemocnice se 100% nechybovém vyhnodnocení. Pak ano, ale pogram rozhodně ne...




















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU