Máte třetí vlnu? A mohl bych ji vidět?
Pandemické vlny zřejmě nemají žádnou definici. Jde vlastně jen o shodu vlády, médií, lidu, že tomuhle kopečku na grafu budeme nějak říkat. Pojmenování vyvolává dojem, že jsme něco poznali a provedli nějakou akci (aspoň tedy ono pojmenování). No a tak se stalo, že se pacienti ptají, jestli bude čtvrtá vlna.
Tohle je fakt záludná otázka. Nejsem odborník a prakticky vůbec nesleduju zpravodajství. Tak mi nezbývá, než spustit eRko a podívat se do dat. Zjistím, kolik kopečků se od začátku pandemie událo.
Vezmu si data Evropského střediska pro prevenci a kontrolu nemocí (European Centre for Disease Prevention and Control, ECDC). Sice během prosince přešli z denního na týdenní cyklus zveřejňování dat, ale pro můj účel to nevadí, spíše budu rád.
Pro zobrazení dat použiju jazyk R a balíček ggplot2.
# nacteme balicek ggplot2 pro zobrazeni dat
library(ggplot2)
# nacteme data ze stranek ECDC
covid_data <- read.csv("https://opendata.ecdc.europa.eu/covid19/casedistribution/csv")
Prozkoumám, jak vypadají získaná data.
str(covid_data) #> 'data.frame': 10005 obs. of 10 variables: #> $ dateRep : chr "18/01/2021" "11/01/2021" "04/01/2021" "28/12/2020" ... #> $ year_week : chr "2021-02" "2021-01" "2020-53" "2020-52" ... #> $ cases_weekly : int 557 675 902 1994 740 1757 1672 1073 1368 1164 ... #> $ deaths_weekly : int 45 71 60 88 111 71 137 68 69 61 ... #> $ countriesAndTerritories : chr "Afghanistan" "Afghanistan" "Afghanistan" "Afghanistan" ... #> $ geoId : chr "AF" "AF" "AF" "AF" ... #> $ countryterritoryCode : chr "AFG" "AFG" "AFG" "AFG" ... #> $ popData2019 : int 38041757 38041757 38041757 38041757 38041757 38041757 38041757 38041757 38041757 38041757 ... #> $ continentExp : chr "Asia" "Asia" "Asia" "Asia" ... #> $ notification_rate_per_100000_population_14.days: num 3.24 4.15 7.61 7.19 6.56 9.01 7.22 6.42 6.66 4.65 ...
To vypadá slušně, mám přehled o týdenním počtu případů (proměnná cases_weekly) a úmrtí ( deaths_weekly) v jednotlivých zemích ( countriesAndTerritories) k danému datu ( dateRep).
Potřebuji jen převést proměnnou dateRep na datum:
covid_data$dateRep = as.Date(covid_data$dateRep, format = "%d/%m/%Y")
Rád bych měl přehled o všech zemích EU, tak si připravím vektor:
# toto jsou evropske zeme
eu_countries <- c("Austria", "Belgium", "Bulgaria", "Croatia", "Cyprus",
"Czechia", "Denmark", "Estonia", "Finland", "France",
"Germany", "Greece", "Hungary", "Ireland", "Italy", "Latvia",
"Lithuania", "Luxembourg", "Malta", "Netherlands", "Poland",
"Portugal", "Romania", "Slovakia", "Slovenia", "Spain",
"Sweden")
A profiltruji dataset, abych získal opravdu jen data EU:
eu_data <- covid_data[covid_data$countriesAndTerritories %in% eu_countries, ]
No a konečně můžu kreslit:
ggplot(eu_data, aes(x = dateRep, y = cases_weekly)) +
geom_line() +
facet_wrap(~ countriesAndTerritories)
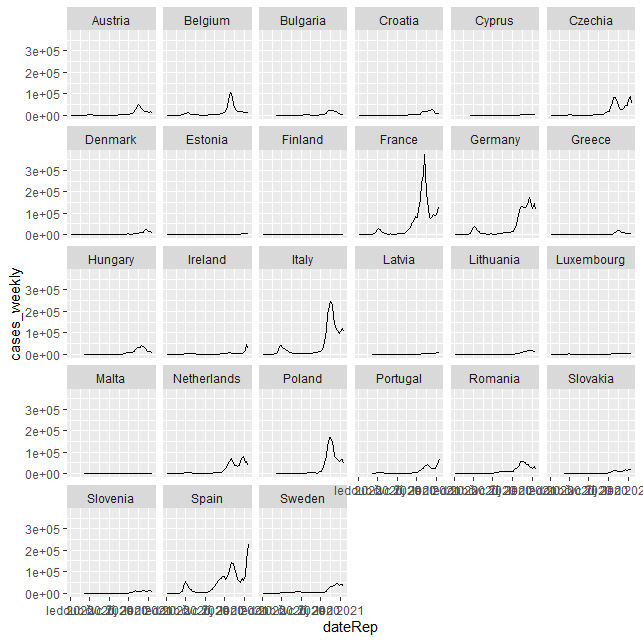
Nevypadá to úplně špatně. Kreslím týdenní počet případů na ose y k danému datu na ose x. Grafy pak rozdělím pomocífacet_wrap() podle zemí, ať je nemám všechny v jedné hromadě.
Protože cílem je vidět jen kopečky a spočítat vlny, můžu si dovolit zrušit čísla na osách pomocí theme_void() a popisku země přesunu pod jednotlivé grafy pomocí parametru strip.position ve funkci facet_wrap().
ggplot(eu_data, aes(x = dateRep, y = cases_weekly)) +
geom_line() +
facet_wrap(~ countriesAndTerritories,
strip.position = "bottom") +
theme_void() +
labs(title = "Absolutní počet případů COVID-19 v EU zemích")
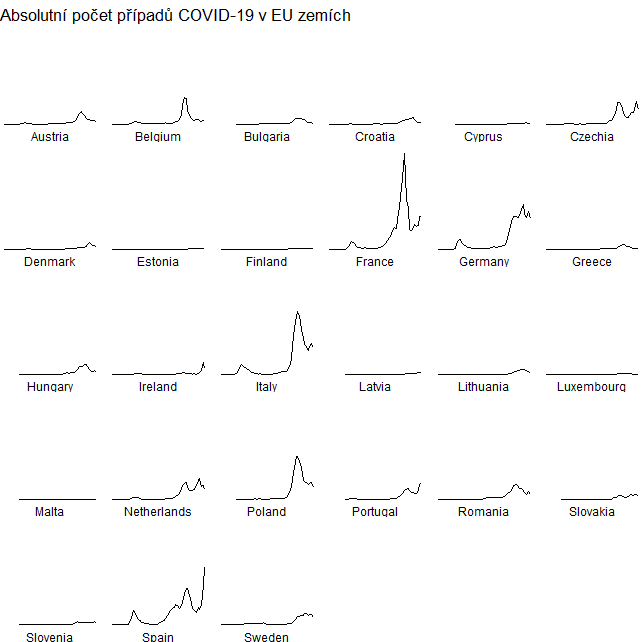
Tohle vypadá ještě lépe. Vidíme, že některé země bojují s virem víc než jiné. Můžu si zkusit vykreslit stejná data s přepočtem na počet obyvatel dané země, protože dataset obsahuje proměnnou popData2019 , čili počet obyvatel dané země v roce 2019.
ggplot(eu_data, aes(x = dateRep, y = cases_weekly/popData2019)) +
geom_line() +
facet_wrap(~ countriesAndTerritories,
strip.position = "bottom") +
theme_void() +
labs(title = "Relativní počet případů COVID-19 v EU zemích na počet obyvatel")

Tady už naše republika nevypadá jako úplné neviňátko. Pokud chci dokonale spočítat kopečky pandemie v dané zemi, můžu rozvolnit osu y. Neboli každá země bude mít svou vlastní osu y tak, aby linie grafu vyplnila prostor až nahoru ke kraji. To pak ale znamená, že země nebudou porovnatelné mezi sebou navzájem, půjde jen o relativní vývoj nových případů onemocnění v dané zemi v daném týdnu vůči maximálnímu počtu případů za týden v dané zemi. Z takového grafu jde už jen propočítat, zda je první vlna větší než druhá, nebo zda daná země pomalu ztrácí disciplínu a třetí vlna je nejhorší.
Rozvolnění osy y provedeme parametrem scale = "free_y" ve funkci facet_wrap:
ggplot(eu_data, aes(x = dateRep, y = cases_weekly)) +
geom_line() +
facet_wrap(~ countriesAndTerritories,
scale = "free_y",
strip.position = "bottom") +
theme_void() +
labs(title = "Počet případů COVID-19 v EU zemích s volnou osou 'y'")

Z tohoto grafu vychází např. Taiwan výborně (má první vlnu nejvyšší, ale není na tomto EU grafu), zatímco ČR po vzorové první vlně najednou skáče jako jojo a Španělsko se utrhává z řetězu s každou další vlnou.
Jsou to jen prachbídné hrátky s vizualizací dat a nakonec nám grafy neřekly nic nového, co bychom dávno nevěděli. Aspoň si můžeme psát čárky za každý nový kopeček. A až bude vln pandemie více než vln EET, pak teprve začne ta pravá legrace!
-
Související články na blogu eHealth
-
Čekáme na plochou křivku, pojďme si ji zatím nakreslit 24. 3. 2020 11:56
-
Vakcína na 95 % 31. 1. 2021 0:54
-
Jak zabalit kolegům data do balíčku v R 27. 1. 2021 15:59
-
Nenechte se zmást odstíny růžové aneb pozor na pandemické grafy 20. 9. 2020 19:25
-
Analýza úniků zdravotnických dat v USA: přibývá vzdálených útoků po síti 2. 10. 2018 23:56
-
Jak je to s tou Mirkou Spáčilovou a jejími 60 % 13. 8. 2018 23:19
-
-
Související články na serveru Root.cz
-
Postřehy z bezpečnosti: chyby v prohlížečích a nová quishingová kampaň 2. 9. 2024 0:00
-
Postřehy z bezpečnosti: Trump's Dumps a další fóra s karetními údaji jsou mimo provoz 21. 2. 2022 0:00
-
Postřehy z bezpečnosti: Apache neví, že není tečka jako tečka 11. 10. 2021 0:00
-
Postřehy z bezpečnosti: kryptoměny táhnou 11. 1. 2021 0:00
-
Co nás čeká v roce 2021: linuxové distribuce, desktopy i hardware 8. 1. 2021 0:00
-
Co se v roce 2020 nepovedlo: šindelové disky, upadající Firefox a ztrácející Intel 29. 12. 2020 0:00
-
-
Smazaný profil
@Poleno: Dobrý postřeh. Pro účel "sečtení vln" jsem to neřešil. Tipuju, že ECDC ta data nijak nečistí, prostě je sečte a zobrazí. Takže pokud daná země nahlásí nějakou "zpětnou korekci", tak se dostane do záporných čísel. Pokud bychom chtěli data zpracovávat dál, tak bychom museli zapátrat po metodice ECDC. Mimochodem ještě v době, kdy ECDC zveřejňovala denní data (a nikoli týdenní jako teď), jsem narazil na to, že hodnoty přírůstků u ECDC a JHU (která se běžně využívají) se trochu liší. Země nejsou úplně konzistentní v tom, jak a jaká data získávají (a hlásí), proto se pořád celosvětově jedná o zdánlivě přesné součty velmi nepřesných čísel... :-)
-
Smazaný profil
@Poleno: Ano, všechny začínají nulou, ovšem poslední graf má volnou osu y, tj. Lucembursko má nulu o něco výše než ostatní země. Každý graf má svůj účel a své limity, něco zviditelňuje a něco jiného zase skrývá, musíte si na to dávat pozor.
Takže poslední graf zviditelňuje rozdíly mezi vlnami v rámci jedné země, ale na druhou stranu již neumožňuje porovnávat země mezi sebou, protože každá má jinou osu y. Roztahuje se od nejmenší hodnoty k nejvyšší hodnotě tak, aby vyplnil celou výšku políčka. Lucembursko tam má jednu negativní korekční hodnotu, proto má nulu na ose y výše, aby se tam ta negativní hodnota vešla. Pokud chcete porovnávat země mezi sebou, slouží k tomu ty dřívější grafy.
-
nil nil (neregistrovaný)
Nejde o to, že je nula výše. Pokud se podívám na graf [3], kde by pořád počet případů měl začínat na 0, nehledě nato jestli je posunutá (y), tak počet případů na počet obyvatel je záporný. Nezlobte se na mne, ale že by měla nějaká země počet případů na obyvatele záporný, tedy nějaké k dobru než bude mít vůbec 0 případů, to se mi moc nezdá.
A taky to je v podstatě vlastně jediná negativní vlna. Což by mohlo být zajímavé zmínit v závěru analýzy ;-)
[3] "Relativní počet případů COVID-19 v EU zemích na počet obyvatel"
-

Pokud by někoho zajímalo jak je to podle obcí v ČR tak jsem udělal vizualizaci počtu nemocných a nových případů. Takhle to vypadá u nás v Horoměřicích http://seeker.azair.cz/cgi-bin/covid19.sh?id=539236 celé je to napsané v bash
-
Jenom doplním, že některé země poskytují data, o kterých se snad ani nedá říct, že jsou nepřesná, protože to jsou úplná hausnumera. Třeba Švédsko skoro vůbec před podzimem netestovalo. Vláda veřejně prohlašovala, že testy nejsou potřeba, protože jediný důležitý údaj je zaplněnost jednotek intezivní péče. Možná ty vlny jsou vidět na grafech zaplněnosti těch jednotek. Ale třeba Švédsko lidi nad 80 let na ty jednotky vůbec neposílalo. Dostávali morfium a do covidových statistik se v řadě případů vůbec nedostali. Ta data nebyla sbírána podle vědecké metodiky, ale podle politického zadání, případně ekonomických zájmů jednotlivých nemocnic. Je to typická rubbish in, rubbish out situace.
-
S tím Švédskem, jsem se na to chtěl v rychlosti podívat. Docela mě zaujala tato datová řada.
https://www.statista.com/statistics/525353/sweden-number-of-deaths/V roce 2019, mají docela podstatný propad počtu úmrtí, oproti rokům 2017 a 2018. A v roce 2020, pak samozřejmě podstatný nárůst kvůli Covidu. Zajímalo by mě, jestli je ten nárůst v roce 2020 ještě vyšší o lidi kteří nějakou náhodu utekli hrobníkovi z lopaty v roce 2019.
Anebo, když teď koukám na statistiku porodnosti ve Švédsku kolem roku 1940, (což je s průměrným věkem dožití 81let) rok narození lidí kteří teď budou umírat je tam dost podstatný skok. Což opět může mít podstatný vliv, na to jaký je zrovna očekávaný počet úmrtí. (Ačkoli v tomto případě nejsem schopen říct, na jakou stranu by se to mělo projevit.)
Zajímalo by mě, jestli se tato data také berou v potaz. Asi nejpřesnější, jak by se to dalo počítat je vzít celkový počet obyvatel státu dle věku v daném roce a z něj zkusit spočítat předpokládaný počet úmrtí, dle věku dožití. A pak to porovnat, s výsledky.
Ale, průměrný člověk (natož politik) nemají rádi statistiku. Možná by z toho nevyšly politicky korektní výsledky pro vládní politiku různých států.
-
Vědecké publikace by to v potaz brát měly. Vím, že ve zdravotním systému mají statistiky, kteří se vytvářením takových modelů živí, ale detaily těch modelů neznám.
Celé je to komplikovanější. V roce 2015 proběhla migrační vlna. Ve Švédsku se pak ohromně zvýšila kriminalita. Vláda a sdělovací prostředky to popíraly (vítací kultura importovaná z Německa jela na 100%), ale policie doporučovala po setmění vycházet jen ve skupinách, nebo radši vůbec. V některých městech to došlo tak daleko, že se občané začali organizovat do občanských gard a hlídkovali v ulicích. Důchodci byli přepadáváni a okrádáni. Když pak svou zkušenost popsali na sociálních sítích, dostali od soudu pokutu za šíření nenávisti. V některých případech dostávali i nepodmíněné tresty vězením. Domovy důchodců byly přeměňovány na ubytovny pro migranty, důchodci se museli stěhovat. (Vytržení z navyklého prostředí má pro staré lidi devastující účinky.). Celá ta atmosféra určitě vedla ke zvýšeným počtům úmrtí. Který státem placený statistik si tyto faktory dovolí zahrnout do modelů, když ví, že mu za to hrozí okamžitý vyhazov?
Ohledně zvýšení kriminality se vedly dlouhé diskuze. Oficiální sdělovací prostředky tvrdily, že k žádnému nárustu kriminality nedošlo. Někteří vládou placení ideologové naopak tvrdili, že došlo ke snížení kriminality. Fak byl ale ten, že ve Švédsku bylo kromě legálních migrantů (s povolením k pobytu nebo čekajících na vyjádření) i kolem 80 000 nelegálních migrantů (žádost zamítnuta nebo žádný pokus o registraci). A ti prostředky k obživě nezískávali legální prací.
V roce 2019 byla situace trochu klidnější. Na Balkáně byly ploty a migrace nebyla tak divoká. Lidé si nové podmínky zvykli.
-
"Vubec nic" bych netvrdil. Nejaky ukazatel to je, ale jak rikate, je vhodne ho nejakym zpusobem ocistit od tohoto vlivu. Jenze to neni tak jednoduche. Takze ty grafy se daji pouzit na velmi hrube srovnani, napriklad je jasne, ze u nas to bylo v lete mnohem lepsi nez je ted na podzim.
Neboli je dobre znat co presne data zobrazuji, ale pokud data nejsou dokonala, neni duvod je hned zahazovat.
-
nil nil (neregistrovaný)
Zajímavé to moc nebude, protože to bude více méně stejné + počet úmrtí s/na covid, protože nejvíc lidí umže prostě věkem, přirozeně, to číslo se nezmění víc než za poslední roky.
Možná bude mít nějaký vliv úplně zastavený provoz země, takže nehody a následky nebudou takové číslo, lockdown omezil i jiné nemoci - jako chřipka, ale to zas takové rozdíly nebudou. -
Smazaný profil
@Poleno: Článek z TV Nova je jen plytká spekulace. Pokud vás zajímají rozdíly v úmrtích za 2020 a předchozí léta, podívejte se do dat (příp. počkejte, až budou k dispozici). Pěkná vizualizace např. od Petra Bouchala zde:
https://petrbouchal.xyz/covid/
Přejděte na záložku "Mortality: Covid vs. rest", kde jsou přepočteny příčiny úmrtí na věkovou strukturu obyvatelstva, příp. "Mortality: all cause", kde jsou porovnány jen počty úmrtí podle věku.
Jeho aplikace je napsána v R a má otevřený zdrojový kód, takže se lze podívat i na to, jak data zpracovává.
-
To jste se nemusel trápit v eRku, když pro každého, kdo umí otevřít prohlížeč, jsou k dispozici prakticky neomezeně konfigurovatelné klikací grafy tady: https://covid-19.nic.cz/cs/
-

Tady je neco co jsem hledal. Pocet celkovy umrti versus pocet umrti na COVID
https://www.facebook.com/jaroslav.borovicka/posts/10161123837190329Cely článek pak
https://www.idnes.cz/technet/veda/kvuli-covidu-umrti-s-covidem-na-covid.A210124_130130_veda_pka -

Ahoj
K článku: https://blog.root.cz/ehealth-v-cr/vakcina-na-95-procent/
není otevřená diskuze, proto volím tuto nestandardní formu reakce pod jiný autorův příspěvek.Ve zmiňovaném článku je jediná, zvýrazněná věta. Předpokládám, že je jako jediná zvýrazněná, protože jí Petr Kejzar přikládá velkou váhu.
Jde o větu:
Je totiž vždy lepší dostat očkování než jakoukoli nepředvídatelnou nemoc.S významem této věty rozhodně nesouhlasím.
Problematika očkování je mnohem širší a hlubší, než aby šla redukovat na tak prosté sdělení. Reakce organismu na očkování rozhodně nepatří mezi předvídatelné události o čemž svědčí dlouhé seznamy vedlejších příznaků a náročnost testování před plošným nasazením.Osobně se domnívám, že očkování jakož i další techniky posilování imunitního systému, jsou pro lidstvo v globálu velmi přínosné, přesto je však potřebné vidět i zápory.























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU