HTML report v jazyce Java na pár řádků
Dnes vám představím jednoduchý tabulkový HTML report vytvořený pomocí pouhých třinácti řádků zdrojového kódu zapsaných do jediného příkazu jazyka Java. Předpokládejme přitom, že služba pro získání dat už existuje. Pokud budeme chtít uživatelům nabídnout také jednoduché (sekvenční) filtrování obsahu tabulky s řazením sloupců, implementace vezme ještě pár řádků navíc. Pro případnou optimalizaci filtrování však bude třeba sáhnout hlouběji do backendu. Webová komponenta si bere data z objektu typu Stream a tak maximální objem prezentovaných dat je limitován pouze možnostmi webového prohlížeče. Pro datový zdroj jsem použil volně dostupný seznam hotelů ve formátu CSV a snad nebude vadit, že některé informace už nejsou aktuální. Podívejme se do těla metody doGet() starého dobrého Java servletu na těch třináct deklarovaných řádků. Model tabulky budeme sestavovat pomocí třídy ReportBuilder z frameworku Ujorm.

Každé volání metody add() přidá do tabulky jeden další sloupec. První argument této metody obsahuje kód pro získání obsahu buňky tabulky, druhý obsahuje název sloupce v hlavičce. Pokud budeme chtít sloupec filtrovat, uvedeme také konstantu reprezentující HTTP parametr webové stránky. Pro podporu řazení doplníme volání metody sortable(), jejíž (volitelný) parametr určuje směr řazení, ten však slouží jen pro grafickou prezentaci, o reálné řazení dat se stará metoda další. Kvůli licenčním podmínkám je třeba doplnit odkaz na původní datový projekt, který vložíme do patičky metodu setFooter(). Nadpis HTML stránky se generuje implicitně z textu uvedeného v konstruktoru builderu, pomocí metody setHeader() ho však můžeme nahradit implementací vlastní. Metoda build() zavolá nakonec metodu pro získání dat, její kód přikládám:

Pro ignorování velikosti znaků převedeme nejdříve hodnoty parametrů na velká písmena, ale implementace vhodného filtru je tady jen na nás. Pokud datový typ sloupec implementuje rozhraní Sortable, tak pro řazení můžeme využít komparátor poskytovaný objektem GridBuilder, v ostatních případech je třeba napsat implementaci vlastní. Nakonec omezíme počet řádků podle limitu. Při velkém objemu dat bude však vhodnější poslední dva řádky prohodit, aby se řazení zúčastnilo menší množství záznamů. Upozorňuji ještě, že všechny HTTP požadavky typu POST je třeba směrovat do metody sevletu doGet(). A to je snad vše podstatné, po spuštění projektu spatříme výsledek podobný následujícím obrázku:
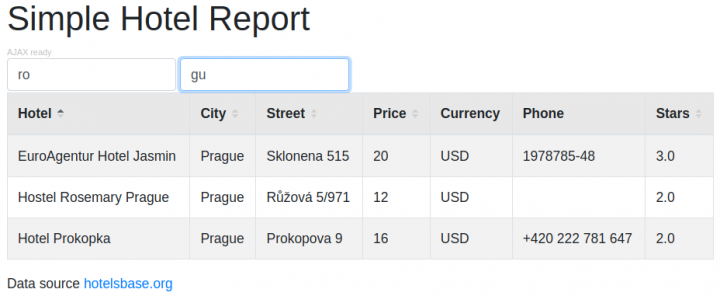
Snímek obrazovky naznačuje, že tabulka se překresluje při změně textu filtru automaticky, stránka však funguje i na na prohlížečích bez podpory Javascriptu, jen hodnoty filtru bude třeba potvrzovat klávesou Enter. Chování AJAX lze potlačit také programově – pomocí metody setAjaxEnabled(false). Všechny parametry formuláře stránky lze přenastavit v parametrech URL, přitom objekt ReportBuilder si neukládá žádná data do Session.
Závěr
Je pravda, že třída ReportBuilder neřeší jen vykreslování tabulky, ale obsluhuje spíše celou stránku. Samotnou tabulku vykresluje třída GridBuilder a na tomto případě je vidět, jak lze takové komponenty skládat do celku. Celé řešení je postavené na objektech třídy Element, která byla zmíněna v minulém blogu.
Pro spuštění projektu je třeba JDK verze 8 a webový prohlížeč s podporu Javascript Vanilla ES6, použitý Javascript však nevyžaduje žádné knihovny. Celý projekt je volně dostupný na GitHub. Projekt se spouští ve Windows skriptem run.cmd (na Linuxu skriptem: run.sh), při prvním startu dojde ke stažení potřebných knihoven. Příště si ukážeme možnosti formátování buněk v této tabulce.
Užitečné odkazy:
- Projekt na GitHub
- JavaDoc tříd ReportBuilder a Element
- Motivační blog o použití třídy Element a příklad integrace s AJAX.
- Dokončení článku
-
Související články na blogu ponec
-
Jednoduché webové stránky s AJAX v jazyce Java 8. 3. 2021 8:30
-
Jak psát webové stránky v jazyce Java bez HTML šablon? 19. 11. 2018 7:00
-
Preferenční hlasování ve sdílené tabulce Schulzeho metodou 9. 9. 2024 8:00
-
Multiplatformní samorozbalitelný archiv ve skriptu jazyka Java 1. 7. 2024 19:16
-
Jak efektivně pracovat s JDBC ve skriptech Java 17 8. 4. 2024 8:00
-
Příběh frameworku Ujorm 25. 3. 2019 7:00
-
-
Související články na ostatních blozích
-
Automatické testování příkladů v dokumentaci pomocí JUnit 5 a JShell 23. 5. 2023 8:39
-
Knihovna Diffator 15. 10. 2013 22:23
-
Mocný AJAX nebo Ajax mocný? 16. 5. 2009 23:28
-
jsem deformovaný ITák 16. 3. 2009 9:57
-
Nejsou RIA aplikace cestou do pekel? 29. 1. 2009 21:05
-
Glassfish v2 9.1_02 + ActiveMQ 5.2.0 + Example 23. 1. 2009 19:42
-
-
Související články na serveru Root.cz
-
Lexikální a syntaktická analýza zdrojových kódů programovacího jazyka Python (3.část) 18. 8. 2022 0:00
-
Postřehy z bezpečnosti: léto plné duchů – Ghost phishing, GhostLock, GhostApproval 13. 7. 2026 0:00
-
Elm: kombinace možností ML jazyka s prostředím JavaScriptu 30. 6. 2026 0:00
-
Postřehy z bezpečnosti: varování před podvodnými weby FIFA 1. 6. 2026 0:00
-
Z jádra mizí podpora ISDN a AX.25, GCC posoudí využití AI/LLM ve vývoji 26. 4. 2026 0:00
-
Postřehy z bezpečnosti: Tycoon2FA zpátky v provozu 30. 3. 2026 0:00
-
-

Přijde mi dost zavádějící napsat, že je něco na 13 řádku v jazyce Java, když je to jen volání nějakého frameworku, kde těch řádek bude schováno mnohem víc.
To bych stejně tak mohl tvrdit třeba že to umím seřadit pole na jeden řádek a zavolat funkci sort z nějaké knihovny.
Celý článek je selfpromo pro ujorm. Proti tomu osobně nic nemám, ale byla by slušnost to (ideálně hned v úvodu) uvést.
-

> je to jen volání nějakého frameworku
Ono jde skoro vždy o volání nějaké knihovny. Co třeba komponenta DataGrid z šablonovacího frameworku PrimeFaces? Učebnicové použití této komponenty se zdá být intuitivní, navíc samotná komponenta obsahuje algoritmy pro filtrování (či řazení) sloupců tabulky. Jakmile však potřebujeme zapracovat specifické filtrování (třeba jednoduché prohledávání celých textů), použití se komplikuje. K tomu chybí typová kontrola parametrů komponenty, refaktoring služeb kolem textové šablony je rizikový, tvorba vlastního potomka komponenty (pro opakované použití) je pracná - zejména ve srovnání s přímým napojením komponent v jazyce Java. Pokud to někomu vyhovuje je to fajn, v opačném případě někdo třeba ocení alternativu.
https://www.primefaces.org/showcase/ui/data/datatable/field.xhtml?jfwid=99877
