Variational AutoEncoder na ořechy
Variational AutoEncoder (dále také VAE) je dost zajímavý model, který se obvykle řadí k těm generativním. Svou strukturou vychází z běžného AutoEncoder modelu (dále také AE), rozdíly najdete především ve struktuře jeho vnitřní reprezentace. Zatímco AE má vnitřní reprezentaci obrázku tvořenou n-rozměrným vektorem čísel, VAE tuto vnitřní reprezentaci vytváří ve formě pravděpodobnostního rozložení pro každou vlastnost. Trochu blíže se k modelu dostanu v průběhu článku.
Opět jsem si jako výchozí datovou sadu pro své pokusy zvolil MVTec AD, ze které použiji pouze obrázky s lískovými ořechy. Pokusím se jako v předchozím článku najít metodu, jak odlišit obrázky neporušených ořechů od těch s různou mírou deformace. Ono na těch ořeších to vypadá jako legrace, ale obdobný způsob můžete použít pro automatizaci hledání zmetkových či jinak nevyhovujících výrobků. Nebo můžete se pokusit odlišit například rentgenové snímky, na kterých se objevila nějaká patologie.
V průběhu přípravy článku jsem si nasbíral nějaké zajímavé odkazy, možná by se vám také mohly hodit:
-
Alibi Detect Project GitHub – knihovna implementující metody mimo jiné pro Outlier Detection a VAE
-
How to Build a Variational Autoencoder in Keras – pěkný úvod do problému VAE
-
Variational AutoEncoder in Keras – návod z dokumentace Keras
-
Variational Autoencoder with Tensorflow – dost hluboký rozbor problémů implementace VAE ve verzích Keras a doporučení pro jejich řešení
Jako obvykle rychlá příprava prostředí:
import sys, os, random, shutil, warnings, glob os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from tqdm import tqdm import tensorflow as tf import tensorflow.keras as keras from tensorflow.keras import backend as K from keras import layers from keras import Sequential import cv2 sns.set_style('darkgrid') warnings.simplefilter(action='ignore', category=FutureWarning) def seed_all(value=42): random.seed(value) np.random.seed(value) tf.random.set_seed(value) os.environ['PYTHONHASHSEED'] = str(value) # os.environ['TF_DETERMINISTIC_OPS'] = '1' seed_all()
Jako výchozí rozlišení budu používat 64×64×3, a to z důvodu redukce potřebných zdrojů pro trénování.
IMAGE_ROOT = "/kaggle/input/mvtec-ad/hazelnut"
IMAGE_SIZE = (64, 64)
Datová sada
Obsahuje samostatnou skupinu obrázků ořechů bez vad. Ta je určena pro trénování modelu a obsahuje 391 snímků.
Další skupiny obrázků jsou pak určeny pro testování výsledků modelu a obsahují obrázky pro ořechy s různou mírou poškození.
Dnes ale použiji poněkud jiný přístup. Pro trénování modelu použiji všechna dostupná data, tedy obrázky ořechů bez vad i ty s vadami. Chtěl bych si tak ověřit přístup, kdy mám velkou sadu dat bez rozlišení toho, který obrázek je v pořádku a který vykazuje nějaké chyby. Pouze vím, že v té datové sadě jsou obrázky s vadami, a chtěl bych je touto metodou najít.
Pro načtení podmnožiny obrázků mám tuhle funkci:
def get_subset(pathname, name=""):
images = list()
for fn in tqdm(glob.glob(pathname), desc=name):
image = cv2.imread(fn, flags=cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, IMAGE_SIZE).astype(np.float32) / 255.0
images.append(image)
return np.array(images)
Takto načtu všechny podmnožiny obrázků, které mám k dispozici:
x_train = get_subset(os.path.join(IMAGE_ROOT, 'train', 'good', '*.png'), 'Train images') x_good = get_subset(os.path.join(IMAGE_ROOT, 'test', 'good', '*.png'), f"Good nuts") x_crack = get_subset(os.path.join(IMAGE_ROOT, 'test', 'crack', '*.png'), f"Crack nuts") x_cut = get_subset(os.path.join(IMAGE_ROOT, 'test', 'cut', '*.png'), f"Cut nuts") x_hole = get_subset(os.path.join(IMAGE_ROOT, 'test', 'hole', '*.png'), f"Hole nuts")
Train images: 100%|██████████| 391/391 [00:19<00:00, 20.56it/s] Good nuts: 100%|██████████| 40/40 [00:01<00:00, 21.50it/s] Crack nuts: 100%|██████████| 18/18 [00:00<00:00, 21.09it/s] Cut nuts: 100%|██████████| 17/17 [00:00<00:00, 21.47it/s] Hole nuts: 100%|██████████| 18/18 [00:00<00:00, 21.69it/s]
A ještě si podmnožiny spojím do jednoho velkého celku. Navíc jsem přidal i permutaci, abych ty obrázky s vadami zamíchal mezi ty bez vad.
x_all = np.vstack((x_train, x_good, x_crack, x_cut, x_hole))
x_all = x_all[np.random.permutation(len(x_all))]
Aby to nebylo tak nasucho, tak několik příkladů obrázků bez vad:
rows, cols = 2, 5 fig=plt.figure(figsize=(14, 6)) for i in range(1, rows*cols+1): fig.add_subplot(rows, cols, i) image = x_train[random.randrange(x_train.shape[0])] plt.imshow(image) plt.show()
Variational AutoEncoder model
VAE model se obvykle zobrazuje nějak takto:
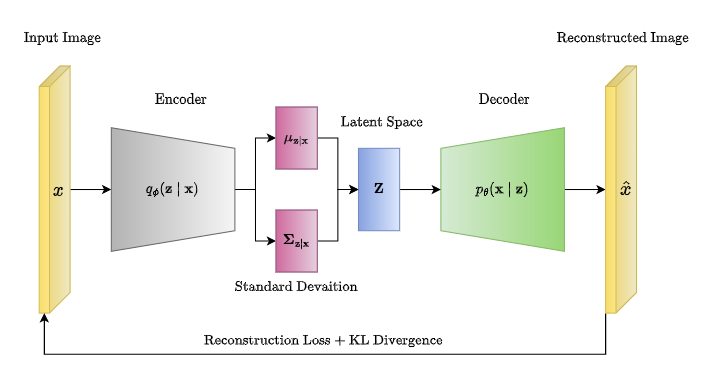
Jako každý AE model má dvě fáze:
-
Encoder – bere na vstupu zdrojový obrázek, ze kterého kaskádou několika konvolučních vrstev vytváří sadu vlastností. Tyto vlastnosti jsou podkladem pro generování vnitřní reprezentace obrázku, ale k tomu se dostanu až vzápětí.
-
Decoder – na vstupu očekává vnitřní reprezentaci obrázku, ze které kaskádou vrstev inverzní konvoluce vytváří zpětně novou podobu obrázku.
To byla zatím ta jednodušší část. Jak jsem již napsal v úvodu, je vnitřní reprezentace obrázku tvořena pravděpodobnostním rozložením pro každou sledovanou vlastnost. A co více, požadujeme, aby se pravděpodobnostní rozložení co nejvíce blížilo normálnímu rozložení.
Vnitřní reprezentace bude tedy tvořena dvěma sadami vektorů. Prvním bude vektor středních hodnot pro každou vlastnost, a druhým vektorem budou jejich směrodatné odchylky. Tím mám v zásadě definováno Gaussovo rozložení.
První problém ovšem nastává v tom, že jako vstup do fáze Decoder musí být nějaký skutečný vektor čísel. Pro napojení obou fází budu tedy potřebovat nějaký specifický krok, který mně zajistí vytvoření náhodného vzorku na základě parametrů pravděpodobnostního rozložení. Navíc mně musí tento krok umožnit zpětný tok gradientu, jinak bych síť nebyl schopen učit. K tomu se dostanu dále.
Jako vnitřní reprezentaci jsem si zvolil vektor 64 vlastností:
LATENT_SPACE = 64
Fáze Encoder
Následuje funkce, která vytvoří část Encoder. Jedna se o tu část, ve které jsou na sebe naskládány konvoluční vrstvy pro vytváření vlastností a redukci prostorových dimenzí:
def create_encoder(X_shape, latent_space, name="Encoder"):
def conv_block(model, *, filters, kernel_size=(3, 3), strides=(1, 1), padding='same', activation=layers.LeakyReLU(), name=""):
model.add(layers.Conv2D(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding, kernel_initializer="he_normal", name=f"{name}_conv"))
model.add(layers.BatchNormalization(name=f"{name}_norm"))
if activation:
model.add(layers.Activation(activation, name=f"{name}_acti"))
model = keras.Sequential()
model.add(keras.Input(X_shape[-3:], name='enc_inputs'))
conv_block(model, filters=64, kernel_size=(3, 3), strides=(2, 2), name="enc_1")
conv_block(model, filters=128, kernel_size=(3, 3), strides=(2, 2), name="enc_2")
conv_block(model, filters=256, kernel_size=(3, 3), strides=(2, 2), name="enc_3")
conv_block(model, filters=512, kernel_size=(3, 3), strides=(2, 2), name="enc_4")
return model
enc_seq = create_encoder(x_train.shape, LATENT_SPACE)
enc_seq.summary(line_length=110)
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩
│ enc_1_conv (Conv2D) │ (None, 32, 32, 64) │ 1,792 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_1_norm (BatchNormalization) │ (None, 32, 32, 64) │ 256 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_1_acti (Activation) │ (None, 32, 32, 64) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_2_conv (Conv2D) │ (None, 16, 16, 128) │ 73,856 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_2_norm (BatchNormalization) │ (None, 16, 16, 128) │ 512 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_2_acti (Activation) │ (None, 16, 16, 128) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_3_conv (Conv2D) │ (None, 8, 8, 256) │ 295,168 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_3_norm (BatchNormalization) │ (None, 8, 8, 256) │ 1,024 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_3_acti (Activation) │ (None, 8, 8, 256) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_4_conv (Conv2D) │ (None, 4, 4, 512) │ 1,180,160 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_4_norm (BatchNormalization) │ (None, 4, 4, 512) │ 2,048 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_4_acti (Activation) │ (None, 4, 4, 512) │ 0 │
└────────────────────────────────────────────────┴─────────────────────────────────────┴─────────────────────┘
Total params: 1,554,816(5.93 MB)
Trainable params: 1,552,896(5.92 MB)
Non-trainable params: 1,920(7.50 KB)
Z výpisu je zřejmé, že ze zdrojového obrázku s rozlišením 64×64×3 postupně vytvořím sadu vlastností 4×4×512.
Toto ještě není celý Encoder. Potřebuji k němu doplnit Dense vrstvy pro střední hodnotu a směrodatnou odchylku. No a pak ještě tu „fintu“ s generováním vzorků.
Protože tuto část není úplně jednoduché napsat z ruky, použil jsem již hotovou implementaci z knihovny Alibi Detect. Zdrojový kód k ukázce najdete tady: https://github.com/SeldonIO/alibi-detect/blob/master/alibi_detect/models/tensorflow/autoencoder.py
class Sampling(Layer):
""" Reparametrization trick. Uses (z_mean, z_log_var) to sample the latent vector z. """
def call(self, inputs: Tuple[tf.Tensor, tf.Tensor]) -> tf.Tensor:
"""
Sample z.
Parameters
----------
inputs
Tuple with mean and log variance.
Returns
-------
Sampled vector z.
"""
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
class EncoderVAE(Layer):
def __init__(self,
encoder_net: tf.keras.Model,
latent_dim: int,
name: str = 'encoder_vae') -> None:
"""
Encoder of VAE.
Parameters
----------
encoder_net
Layers for the encoder wrapped in a tf.keras.Sequential class.
latent_dim
Dimensionality of the latent space.
name
Name of encoder.
"""
super(EncoderVAE, self).__init__(name=name)
self.encoder_net = encoder_net
self.fc_mean = Dense(latent_dim, activation=None)
self.fc_log_var = Dense(latent_dim, activation=None)
self.sampling = Sampling()
def call(self, x: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
x = self.encoder_net(x)
if len(x.shape) > 2:
x = Flatten()(x)
z_mean = self.fc_mean(x)
z_log_var = self.fc_log_var(x)
z = self.sampling((z_mean, z_log_var))
return z_mean, z_log_var, z
Podstatná je vrstva EncoderVAE. Ta očekává, že dostane při vytvoření dva parametry. Prvním je model encoder (to jsem si vytvořil funkcí create_encoder), druhým pak velikost vektoru vnitřní reprezentace.
EncoderVAE si přidá dvě vrstvy pro střední hodnotu fc_mean a směrodatnou odchylku fc_log_var (jsou to dva vektory velikosti vnitřní reprezentace). A ještě si přidá vrstvu pro vytvoření náhodného vzorku sampling.
Vrstva pro vytvoření náhodného vzorku dostane při svém volání dva parametry pravděpodobnostního rozložení. Vytvoří náhodný vzorek dat se střední hodnotou 0.0 a směrodatnou odchylkou 1.0. Ten pak vynásobí směrodatnou odchylkou a přičte střední hodnotu. Tím se oddělilo generování náhodného vzorku od parametrů fc_mean a fc_log_var, což následně umožňuje diferencování vrstvy a zpětný tok gradientu.
Fáze Decoder
Decoder je z pohledu předchozí kapitoly daleko jednodušší.
Vstupem fáze je vektor vlastností z vnitřní reprezentace obrázku (jedná se o náhodný vzorek dle parametrů normálního rozložení). Z tohoto vektoru budu kaskádou vrstev inverzní konvoluce vytvářet obrázek v původním rozlišení.
conv_shape = enc_seq.output_shape[-3:]
Do proměnné conv_shape jsem si uschoval rozlišení poslední vrstvy Encoder sekvence. To budu potřebovat proto, abych z jednorozměrného vektoru udělal prostorovou matici. V tomto konkrétním případě je to rozlišení 4×4×512.
A touto funkcí si vytvořím celou implementace Decoder fáze (nebudu potřebovat nic dalšího doplnit):
def create_decoder(latent_space, conv_shape, name="Decoder"):
def conv_block(model, *, filters, kernel_size=(3, 3), strides=(1, 1), padding='same', activation=layers.LeakyReLU(), name=""):
model.add(layers.Conv2DTranspose(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding, kernel_initializer="he_normal", name=f"{name}_conv"))
model.add(layers.BatchNormalization(name=f"{name}_norm"))
if activation:
model.add(layers.Activation(activation, name=f"{name}_acti"))
model = keras.Sequential()
model.add(keras.Input((latent_space, ), name='dec_inputs'))
model.add(layers.Dense(units=np.prod(conv_shape), name="dec_dense"))
model.add(layers.Reshape(target_shape=conv_shape, name="dec_reshape"))
conv_block(model, filters=256, kernel_size=(3, 3), strides=(2, 2), name="enc_3")
conv_block(model, filters=128, kernel_size=(3, 3), strides=(2, 2), name="enc_2")
conv_block(model, filters=64, kernel_size=(3, 3), strides=(2, 2), name="enc_1")
conv_block(model, filters=3, kernel_size=(3, 3), strides=(2, 2), activation="sigmoid", name="outputs")
return model
dec_seq = create_decoder(LATENT_SPACE, conv_shape)
dec_seq.summary(line_length=110)
Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩
│ dec_dense (Dense) │ (None, 8192) │ 532,480 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ dec_reshape (Reshape) │ (None, 4, 4, 512) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_3_conv (Conv2DTranspose) │ (None, 8, 8, 256) │ 1,179,904 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_3_norm (BatchNormalization) │ (None, 8, 8, 256) │ 1,024 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_3_acti (Activation) │ (None, 8, 8, 256) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_2_conv (Conv2DTranspose) │ (None, 16, 16, 128) │ 295,040 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_2_norm (BatchNormalization) │ (None, 16, 16, 128) │ 512 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_2_acti (Activation) │ (None, 16, 16, 128) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_1_conv (Conv2DTranspose) │ (None, 32, 32, 64) │ 73,792 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_1_norm (BatchNormalization) │ (None, 32, 32, 64) │ 256 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ enc_1_acti (Activation) │ (None, 32, 32, 64) │ 0 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ outputs_conv (Conv2DTranspose) │ (None, 64, 64, 3) │ 1,731 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ outputs_norm (BatchNormalization) │ (None, 64, 64, 3) │ 12 │
├────────────────────────────────────────────────┼─────────────────────────────────────┼─────────────────────┤
│ outputs_acti (Activation) │ (None, 64, 64, 3) │ 0 │
└────────────────────────────────────────────────┴─────────────────────────────────────┴─────────────────────┘
Total params: 2,084,751(7.95 MB)
Trainable params: 2,083,849(7.95 MB)
Non-trainable params: 902(3.52 KB)
if 'alibi_detect' not in sys.modules:
!pip install alibi-detect
...
Installing collected packages: alibi-detect
Successfully installed alibi-detect-0.12.0
A nyní si již model mohu vytvořit a přeložit:
from alibi_detect.models.tensorflow.autoencoder import VAE vae = VAE(encoder_net=enc_seq, decoder_net=dec_seq, latent_dim=LATENT_SPACE, beta=1e-3) vae.compile(optimizer="adam", loss="mse", metrics=['accuracy'])
Dále budu svůj připravený model trénovat na všech obrázcích, které mám k dipozici. Pole x_all obsahuje obrázky ořechů bez vad i ty s vadami, prostě vše v jednom:
MODEL_CHECKPOINT = f"/kaggle/working/model/{vae.name}.keras"
EPOCHS = 100
callbacks_list = [
keras.callbacks.ModelCheckpoint(filepath=MODEL_CHECKPOINT, monitor='val_accuracy', save_best_only=True, mode='max', verbose=1)
]
history = vae.fit(x=x_all, y=x_all, epochs=EPOCHS, callbacks=callbacks_list, validation_split=0.2, verbose=1)
vae.load_weights(MODEL_CHECKPOINT)
Epoch 1/100
10/13 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.3958 - loss: 0.0800
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1726328558.188122 76 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
13/13 ━━━━━━━━━━━━━━━━━━━━ 0s 331ms/step - accuracy: 0.3988 - loss: 0.0723
W0000 00:00:1726328562.189071 76 graph_launch.cc:671] Fallback to op-by-op mode because memset node breaks graph update
Epoch 1: val_accuracy improved from -inf to 0.38712, saving model to /kaggle/working/model/vae.keras
13/13 ━━━━━━━━━━━━━━━━━━━━ 19s 589ms/step - accuracy: 0.3994 - loss: 0.0704 - val_accuracy: 0.3871 - val_loss: 0.0130
...
Epoch 99/100
11/13 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step - accuracy: 0.9041 - loss: 0.0014
Epoch 99: val_accuracy did not improve from 0.92304
13/13 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - accuracy: 0.9034 - loss: 0.0014 - val_accuracy: 0.9132 - val_loss: 0.0016
Epoch 100/100
11/13 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step - accuracy: 0.9098 - loss: 0.0014
Epoch 100: val_accuracy improved from 0.92304 to 0.92355, saving model to /kaggle/working/model/vae.keras
13/13 ━━━━━━━━━━━━━━━━━━━━ 1s 43ms/step - accuracy: 0.9069 - loss: 0.0014 - val_accuracy: 0.9236 - val_loss: 0.0015
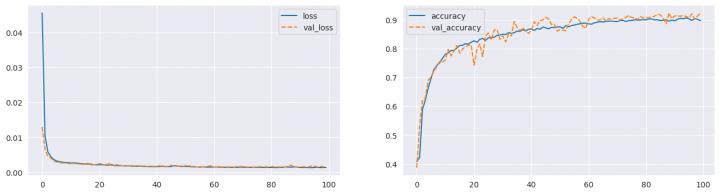
A takto vypadal průběh trénování z pohledu ztrátové funkce a metrik (použil jsem jedinou – accuracy):
fig, ax = plt.subplots(1, 2, figsize=(16, 4)) sns.lineplot(data={k: history.history[k] for k in ('loss', 'val_loss')}, ax=ax[0]) sns.lineplot(data={k: history.history[k] for k in history.history.keys() if k not in ('loss', 'val_loss')}, ax=ax[1]) plt.show()
Vyhodnocení výsledků
No a jak mně tady můj model vlastně funguje? Zkusím se na něj podívat z několika pohledů …
Predikce modelu pro ořechy s vadami i bez nich
Zkusím se podívat, co mně model predikuje u obrázků z různých testovacích sad.
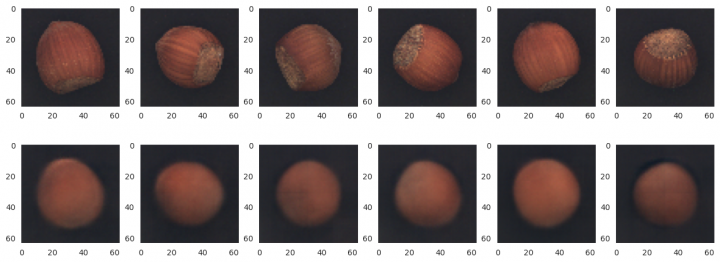
Pro testovací sadu ořechů bez vad
x_test = x_good x_pred = vae.predict(x_test) rows, cols = 3, 6 fig=plt.figure(figsize=(16, 9)) for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)): fig.add_subplot(rows, cols, i + 1) image = x_test[ind] plt.grid(False) plt.imshow(image) fig.add_subplot(rows, cols, i + cols + 1) image = x_pred[ind] plt.grid(False) plt.imshow(image) plt.show() 2/2 ━━━━━━━━━━━━━━━━━━━━ 2s 1s/step
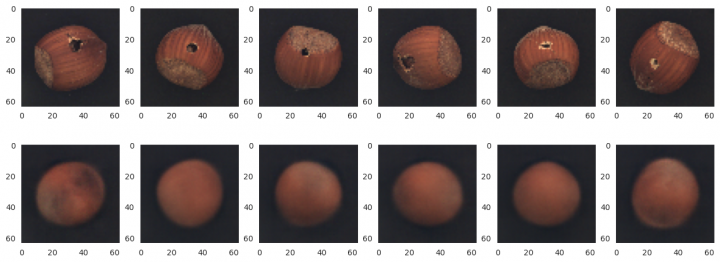
Testovací sada rozbitých ořechů
x_test = x_crack x_pred = vae.predict(x_test) rows, cols = 3, 6 fig=plt.figure(figsize=(16, 9)) for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)): fig.add_subplot(rows, cols, i + 1) image = x_test[ind] plt.grid(False) plt.imshow(image) fig.add_subplot(rows, cols, i + cols + 1) image = x_pred[ind] plt.grid(False) plt.imshow(image) plt.show() 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 985ms/step
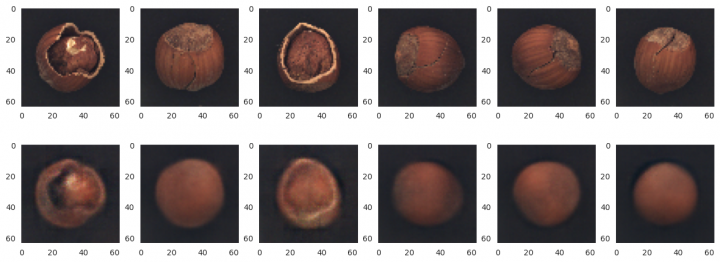
Testovací sada ořechů s prasklinami
x_test = x_cut x_pred = vae.predict(x_test) rows, cols = 3, 6 fig=plt.figure(figsize=(16, 9)) for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)): fig.add_subplot(rows, cols, i + 1) image = x_test[ind] plt.grid(False) plt.imshow(image) fig.add_subplot(rows, cols, i + cols + 1) image = x_pred[ind] plt.grid(False) plt.imshow(image) plt.show() 1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 974ms/step

A na závěr testovací sada ořechů s dírkou
x_test = x_hole x_pred = vae.predict(x_test) rows, cols = 3, 6 fig=plt.figure(figsize=(16, 9)) for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)): fig.add_subplot(rows, cols, i + 1) image = x_test[ind] plt.grid(False) plt.imshow(image) fig.add_subplot(rows, cols, i + cols + 1) image = x_pred[ind] plt.grid(False) plt.imshow(image) plt.show() 1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
Vizualizace vnitřní reprezentace
Pokusil jsem se také podávat na to, jak vypadá vnitřní reprezentace modelu pro různé skupiny obrázků (dále se budu zabývat pouze jedním z vektorů, a sice střední hodnotou vlastností mu).
pred_all = vae.encoder(x_all) mean_all = pred_all[0].numpy().mean(axis=0) pred_good = vae.encoder(x_good) pred_crack = vae.encoder(x_crack) pred_cut = vae.encoder(x_cut) pred_hole = vae.encoder(x_hole)
Vypočítal jsem si vnitřní reprezentaci pro všechny obrázky dohromady, a následně pro všechny testovací sady (jen připomínám, že výstupem fáze Encoder je trojice mu, log_var a z).
data = pd.DataFrame({
'good': (np.subtract(pred_good[0].numpy(), mean_all)).mean(axis=0),
'crack': (np.subtract(pred_crack[0].numpy(), mean_all)).mean(axis=0),
'cut': (np.subtract(pred_cut[0].numpy(), mean_all)).mean(axis=0),
'hole': (np.subtract(pred_hole[0].numpy(), mean_all)).mean(axis=0),
})
Pro všechny testovací sady jsem porovnal průměrné hodnoty vlastností proti těm reprezentujícím všechny obrázky. Předpokládám, že obrázky ořechů bez sad se budou od průměru lišit jen velmi málo. U těch sad s významnými vadami bych mohl vidět také významné rozdíly ve vnitřní reprezentaci.
A takto vypadá grafické zobrazení:
fig=plt.figure(figsize=(14, 6)) sns.lineplot(data) plt.show()

Generování nových instancí
V úvodu článku jsem napsal, že VAE model je možné řadit mezi generativní modely. Tedy měl by mně umožňovat generovat obrázky ořechů, které dříve nikdo neviděl. Vyzkouším si to.
Zkusím si vybrat nějaký zajímavý zdrojový obrázek, v tomto případě je to pořadové číslo 13 v sadě rozbitých ořechů.
instance = 13 fig=plt.figure(figsize=(3, 3)) plt.imshow(x_crack[instance]) plt.grid(False) plt.show()

Z dříve vytvořené predikce si vezmu parametry rozložení pro každou vlastnost, mu a log_var. Z těchto parametrů vytvořím několik náhodných vzorků, které následně pošlu do Decoder fáze. Výsledek pak vypadá takto:
beta = 3.0 mu, log_var = pred_crack[0][instance], pred_crack[1][instance] rows, cols = 2, 6 fig=plt.figure(figsize=(16, 8)) for i in range(1, rows*cols+1): fig.add_subplot(rows, cols, i) z = mu + tf.exp(0.5 * log_var) * beta * keras.backend.random_normal(shape=(mu.shape)) image = vae.decoder(np.expand_dims(z, axis=0))[0] plt.grid(False) plt.imshow(image) plt.show()

Detekce anomálií
Nakonec se dostávám k tomu původnímu cíli, proč jsem se VAE modelem zabýval. A tím je detekce anomálií ve snímcích ořechů. Budu schopen najít ty s nějakou vadou?
Postup bude stejný jako v předchozím článku. Vytvořím si outlier detector na základě již existujícího a vytrénovaného modelu. Následně vyzkouším na všech testovacích sadách, zdali je detektor schopen označit správně obrázek za anomálii, a případně ukázat místo na obrázku, které k tomuto závěru vedlo.
from alibi_detect.od import OutlierVAE THRESHOLD = 0.0045 od = OutlierVAE(threshold=THRESHOLD, vae=vae, data_type='image')
Detekce anomálií pro testovací sadu ořechů bez vad
pred = od.predict(x_good,
outlier_type='instance',
outlier_perc=20,
return_feature_score=True,
return_instance_score=True)
outliers = pred['data']['is_outlier']
print(f"Correctly predicted: {(outliers == 0).sum() / len(outliers):.00%}")
Correctly predicted: 72%
Detekce anomálií pro testovací sadu rozbitých ořechů
pred = od.predict(x_crack,
outlier_type='instance',
outlier_perc=20,
return_feature_score=True,
return_instance_score=True)
outliers = pred['data']['is_outlier']
print(f"Correctly predicted: {(outliers == 1).sum() / len(outliers):.00%}")
x_pred = pred['data']['feature_score']
x_pred = np.linalg.norm(x_pred, axis=-1, keepdims=True)
rows, cols = 3, 6
fig=plt.figure(figsize=(16, 9))
for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)):
fig.add_subplot(rows, cols, i + 1)
image = x_crack[ind]
plt.grid(False)
plt.imshow(image)
fig.add_subplot(rows, cols, i + cols + 1)
image = x_pred[ind]
plt.grid(False)
plt.imshow(image, cmap='gray')
plt.show()
Correctly predicted: 83%

Detekce anomálií pro testovací sadu prasklých ořechů
pred = od.predict(x_cut,
outlier_type='instance',
outlier_perc=20,
return_feature_score=True,
return_instance_score=True)
outliers = pred['data']['is_outlier']
print(f"Correctly predicted: {(outliers == 1).sum() / len(outliers):.00%}")
x_pred = pred['data']['feature_score']
x_pred = np.linalg.norm(x_pred, axis=-1, keepdims=True)
rows, cols = 3, 6
fig=plt.figure(figsize=(16, 9))
for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)):
fig.add_subplot(rows, cols, i + 1)
image = x_cut[ind]
plt.grid(False)
plt.imshow(image)
fig.add_subplot(rows, cols, i + cols + 1)
image = x_pred[ind]
plt.grid(False)
plt.imshow(image, cmap='gray')
plt.show()
Correctly predicted: 47%

Detekce anomálií pro testovací sadu ořechů s dírkou
pred = od.predict(x_hole,
outlier_type='instance',
outlier_perc=20,
return_feature_score=True,
return_instance_score=True)
outliers = pred['data']['is_outlier']
print(f"Correctly predicted: {(outliers == 1).sum() / len(outliers):.00%}")
x_pred = pred['data']['feature_score']
x_pred = np.linalg.norm(x_pred, axis=-1, keepdims=True)
rows, cols = 3, 6
fig=plt.figure(figsize=(16, 9))
for i, ind in enumerate(random.sample(range(x_pred.shape[0]), cols)):
fig.add_subplot(rows, cols, i + 1)
image = x_hole[ind]
plt.grid(False)
plt.imshow(image)
fig.add_subplot(rows, cols, i + cols + 1)
image = x_pred[ind]
plt.grid(False)
plt.imshow(image, cmap='gray')
plt.show()
Correctly predicted: 83%

Žádné názory
