Rozpoznání zápalu plic z RTG snímků - díl první
V tomto článku a několika následujících bych se rád podíval na problematiku klasifikace obrázků. Posouvám se tedy od jednorozměrných signálů, jak tomu bylo u EKG křivek, ke dvěma rozměrům v případně snímků.
Jako téma jsem si vybral opět něco z oblasti zdravotnictví, a tím je rozpoznávání zápalu plic z rentgenových snímků. Důvodem je opět dostupnost vhodných dat pro experimentování. Zvolil jsem si velice oblíbenou datovou sadu poskytovanou na serveru Kaggle: Chest X-Ray Images (Pneumonia).
Ve svých pokusech bych se chtěl podívat na několik modelů vhodných pro tento úkol, a to rovnou ze dvou možných přístupů. Jedním možným přístupen je napsat a trénovat model z „čistého stolu“ pouze na základě dat, které mám aktuálně k dispozici. Druhý možný, a také hodně oblíbený, způsob je využití již existujících modelů trénovaných na úplně jiné datové sadě, a přizpůsobení jejich výstupů mým aktuálním potřebám. Tomuto přístupu se také říká „transfer learning“.
In [1]:
import sys
import os
import glob
import shutil
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import tensorflow.keras as keras
from keras.utils import image_dataset_from_directory
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras import Input, Model
from keras import layers
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.utils.class_weight import compute_class_weight
import cv2
sns.set_style('darkgrid')
Příprava dat
V prvém kroku bude jistě zajímavé se podívat, jaká data mám vlastně k dispozici.
In [2]:
DATA_ROOT = '/kaggle/input/chest-xray-pneumonia/chest_xray' DATA_TRAIN = os.path.join(DATA_ROOT, "train") DATA_VALID = os.path.join(DATA_ROOT, "val") DATA_TEST = os.path.join(DATA_ROOT, "test")
Takto vypadá adresářová struktura datové sady:
In [3]:
print("TRAINING Directory >>>")
for dirpath, dirnames, filenames in os.walk(DATA_TRAIN):
if len(filenames):
print(f" {os.path.normpath(dirpath).lstrip(os.path.sep).split(os.path.sep)[-1]:9}: {len(filenames)}")
print("VALIDATION Directory >>>")
for dirpath, dirnames, filenames in os.walk(DATA_VALID):
if len(filenames):
print(f" {os.path.normpath(dirpath).lstrip(os.path.sep).split(os.path.sep)[-1]:9}: {len(filenames)}")
print("TESTING Directory >>>")
for dirpath, dirnames, filenames in os.walk(DATA_TEST):
if len(filenames):
print(f" {os.path.normpath(dirpath).lstrip(os.path.sep).split(os.path.sep)[-1]:9}: {len(filenames)}")
TRAINING Directory >>>
PNEUMONIA: 3875
NORMAL : 1341
VALIDATION Directory >>>
PNEUMONIA: 8
NORMAL : 8
TESTING Directory >>>
PNEUMONIA: 390
NORMAL : 234
Jak můžete vidět, autoři již rozdělili sadu na množinu pro trénování, validaci a testování. V každé množině jsou snímky zařazeny do adresáře PNEUMONIA v případě, že snímek byl diagnostikován jako zápal plic. Snímek zařazen do adresáře NORMAL pak znamená, že zde žádný zápal plic diagnostikován nebyl. Strukturou adresářů mám tedy dáno také označení (label) snímku a tím také jeho zařazení do třídy.
Bude jistě zajímavé, jak vypadají soubory se samotnými snímky. Jsou to vždy soubory ve formátu JPEG, tedy barevné obrázky se ztrátovou kompresí původních dat. Další otázkou je, v jakém rozlišení jsou tyto snímky uloženy. Tady je orientační odpověď:
In [4]:
pd.DataFrame([keras.utils.load_img(fn, color_mode="grayscale").size for fn in glob.glob(f"{DATA_TRAIN}/**/*.jpeg", recursive=True)], columns=["height", "width"]).describe()
Out[4]:
|
height |
width |
|
|---|---|---|
|
count |
5216.000000 |
5216.000000 |
|
mean |
1320.610813 |
968.074770 |
|
std |
355.298743 |
378.855691 |
|
min |
384.000000 |
127.000000 |
|
25% |
1056.000000 |
688.000000 |
|
50% |
1284.000000 |
888.000000 |
|
75% |
1552.000000 |
1187.750000 |
|
max |
2916.000000 |
2663.000000 |
In [5]:
def show_batch(image_batch, label_batch):
plt.figure(figsize=(16, 8))
for n in range(10):
ax = plt.subplot(2, 5, n+1)
plt.imshow(image_batch[n], cmap='gray')
if label_batch[n]:
plt.title("PNEUMONIA")
else:
plt.title("NORMAL")
# plt.axis("off")
image_batch, label_batch = next(iter(image_dataset_from_directory(
DATA_VALID,
label_mode='binary',
class_names=['NORMAL', 'PNEUMONIA'],
color_mode='grayscale')))
show_batch(image_batch.numpy(), label_batch.numpy())
Found 16 files belonging to 2 classes.
Načítání dat
Pro své experimenty budu načítat všechny obrázky do numpy pole. Při načítání udělám také konverzi do škály šedi, pokud je to požadováno, a také konverzi rozlišení do jedné společné velikosti. Výsledkem funkce jsou dvě pole. První s načtenými obrázky a druhé s jejich label.
In [6]:
LABELS = ['NORMAL', 'PNEUMONIA']
IMAGE_SIZE = (224, 224)
def get_datasource(*data_dirs, flag=cv2.IMREAD_GRAYSCALE):
x, y = list(), list()
for data_dir in data_dirs:
for i, label in enumerate(LABELS):
path = os.path.join(data_dir, label)
target = [0] * len(LABELS)
target[i] = 1
for img in os.listdir(path):
if img.endswith(".jpeg"):
img_arr = cv2.imread(os.path.join(path, img), flag)
resized_arr = cv2.resize(img_arr, IMAGE_SIZE)
x.append(resized_arr)
y.append(target)
return np.array(x) / 255, np.array(y)
Nevyvážená data
Ještě je dobré dopředu zvážit, jak jsem na tom se zastoupením vzorků v jednotlivých třídách:
In [7]:
_, y = get_datasource(DATA_TRAIN, DATA_VALID) y.sum(axis=0)
Out[7]:
array([1349, 3883])
Je zřejmé, že těch označených jako NORMAL je výrazně méně. Při svých pokusech se tímto ale zabývat dále nebudu.
Framework pro vyhodnocení modelu
Vzhledem k tomu, že bych rád vyzkoušel několik modelů na jedné sadě dat, udělal jsem si jednu společnou proceduru pro vyhodnocení výsledků modelu. Nejdříve ukázka, jak taková funkce vypadá:
In [9]:
def evaluate_model(model, *, epochs=40, batch_size=32, forced_training=False):
print(f"=== MODEL EVALUATION =================================================\n")
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy', 'AUC'])
model.summary()
MODEL_CHECKPOINT = f"/kaggle/working/model/{model.name}.ckpt"
if not os.path.exists(MODEL_CHECKPOINT) or forced_training:
print(f"\n--- Model training ---------------------------------------------------\n")
shutil.rmtree(MODEL_CHECKPOINT, ignore_errors=True)
callbacks_list = [
keras.callbacks.EarlyStopping(
monitor='val_auc',
patience=10),
keras.callbacks.ModelCheckpoint(
filepath=MODEL_CHECKPOINT,
monitor='val_auc',
save_best_only=True,
mode='max',
verbose=1)
]
history = model.fit(
datagen.flow(x_train, y_train, batch_size=batch_size),
epochs=epochs,
callbacks=callbacks_list,
validation_data=datagen.flow(x_valid, y_valid),
verbose=1)
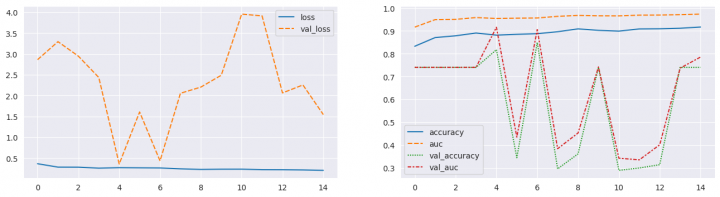
print(f"\n--- Training history -------------------------------------------------\n")
fig, ax = plt.subplots(1, 2, figsize=(16, 4))
sns.lineplot(data={k: history.history[k] for k in ('loss', 'val_loss')}, ax=ax[0])
sns.lineplot(data={k: history.history[k] for k in history.history.keys() if k not in ('loss', 'val_loss')}, ax=ax[1])
plt.show()
else:
print(f"\n--- Model is already trainded ... loading ----------------------------\n")
model.load_weights(MODEL_CHECKPOINT)
print(f"\n--- Test Predictions and Metrics -------------------------------------\n")
y_pred = model.predict(x_test, verbose=0)
plt.figure(figsize=(6, 3))
heatmap = sns.heatmap(confusion_matrix(np.argmax(y_test, axis=-1), np.argmax(y_pred, axis=-1)), annot=True, fmt="d", cbar=True)
heatmap.yaxis.set_ticklabels(LABELS, rotation=90, ha='right')
heatmap.xaxis.set_ticklabels(LABELS, rotation=0, ha='right')
heatmap.axes.set_ylabel('True label')
heatmap.axes.set_xlabel('Predicted label')
plt.show()
print()
print(classification_report(np.argmax(y_test, axis=-1), np.argmax(y_pred, axis=-1), target_names=LABELS, zero_division=0))
print(f"\n=== MODEL EVALUATION FINISHED ========================================")
Při vyhodnocení modelu se postupuje zhruba takto:
-
Model přeložím a vypíšu si jeho schéma na obrazovku
-
jako metodu pro gradient descent jsem zvolil Adam
-
optimalizovanou funkcí je cross entrophy, protože hledám dvě třídy
-
doplnil jsem ještě metriky pro vyhodnocení úspěšnosti, a sice accuracy a AUC
-
-
Při trénování budu používat dvě callback funkce:
-
jednou z nich je kontrola, zda nedochází k „přetrénování“ modelu a tedy dřívějšímu ukončení trénování. Jako hlídanou metriku jsem použil AUC.
-
druhou funkcí je uschování modelu s nejlepšími výsledky při validaci, měřeno opět metrikou AUC. Na konci trénování pak model s nejlepšími výsledky znovu načtu jako model pro testování na testovací sadě.
-
-
Dále již pokračuje vlastní trénování na trénovací a validační datové sadě.
-
průběh trénování, tedy optimalizované funkce a metriky na trénovací i validační datové sadě, je následně zobrazen do grafu.
-
-
Posledním krokem je vyhodnocení modelu na testovací sadě dat
-
nejdříve udělám predikce pro celou testovací sadu a následně výsledek predikce porovnám s očekávanými label
-
vše se pak zobrazí jako „confusion matrix“ a také ve formě klasifikačního reportu se stanovením metrik Precision, Recall a F1-score.
-
Pro představu bude asi lepší si ukázat, jak to celé funguje na nějakém jednoduchém modelu. A o tom bude další kapitola.
Mělká 2D konvoluční síť – 3 vrstvy
Jako výchozí model pro vyzkoušení jsem si zvolil jednoduchou síť se třemi konvolučními vrstvami. Následují pak dvě plně propojené vrstvy se závěrečnou klasifikační vrstvou. Aktivační funkcí poslední vrstvy je softmax pro výběr nejlepší label.
In [10]:
def create_model_ShallowCNN(X_shape, classes=2, name="ShallowCNN"):
def mlp(x, hidden_units, activation='relu', dropout_rate=0.3, name=""):
for i, units in enumerate(hidden_units):
x = layers.Dense(units, activation=activation, name=f"{name}_{i}_dense")(x)
x = layers.Dropout(dropout_rate, name=f"{name}_{i}_dropout")(x)
return x
inputs = Input(X_shape[-3:], name='inputs')
x = layers.Conv2D(64, (3, 3), strides=(1, 1), padding='same', name=f'conv_1')(inputs)
x = layers.BatchNormalization(name=f'norm_1')(x)
x = layers.Activation('relu', name=f'actv_1')(x)
x = layers.MaxPooling2D((2, 2), name=f'pool_1')(x)
x = layers.Conv2D(128, (3, 3), strides=(1, 1), padding='same', name=f'conv_2')(x)
x = layers.BatchNormalization(name=f'norm_2')(x)
x = layers.Activation('relu', name=f'actv_2')(x)
x = layers.MaxPooling2D((2, 2), name=f'pool_2')(x)
x = layers.Conv2D(256, (3, 3), strides=(1, 1), padding='same', name=f'conv_3')(x)
x = layers.BatchNormalization(name=f'norm_3')(x)
x = layers.Activation('relu', name=f'actv_3')(x)
x = layers.GlobalAveragePooling2D(name=f'aver')(x)
x = layers.Flatten(name="flatten")(x)
x = mlp(x, (1024, 512), name="dense")
outputs = layers.Dense(classes, activation='softmax', name='outputs')(x)
return Model(inputs=inputs, outputs=outputs, name=name)
Dříve, než začnu model trénovat, musím načíst zdrojová data a udělat potřebné konverze. Vzhledem k tomu, že autory navržená validační data je dost malá, rozhodl jsem se načíst společně jak trénovací tak validační sadu do jedné a udělat si rozdělení sám (zvolil jsem poměr 80:20).
Následuje ještě definice generátoru pro náhodnou úpravu obrázků před jejich použitím. Provede se postupně náhodná rotace snímku, zoomování, posun v horizontální a vertikální rovině a také náhodné otočení snímku. To vše by mělo pomoci při trénování oddálit overfitting a zlepšit predikci modelu.
In [11]:
x_train, x_valid, y_train, y_valid = train_test_split(*get_datasource(DATA_TRAIN, DATA_VALID), test_size=0.2)
x_test, y_test = get_datasource(DATA_TEST)
x_train = np.expand_dims(x_train, axis=-1)
x_valid = np.expand_dims(x_valid, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)
datagen = ImageDataGenerator(
rotation_range = 30,
zoom_range = 0.2,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip = True,
vertical_flip=False)
datagen.fit(x_train)
A takto vypadá vyhodnocení modelu:
In [12]:
evaluate_model(create_model_ShallowCNN(x_train.shape, 2), forced_training=False) === MODEL EVALUATION ================================================= Model: "ShallowCNN" _______________________________________________________________ Layer (type) Output Shape Param # ================================================================= inputs (InputLayer) [(None, 224, 224, 1)] 0 conv_1 (Conv2D) (None, 224, 224, 64) 640 norm_1 (BatchNormalization (None, 224, 224, 64) 256 ) actv_1 (Activation) (None, 224, 224, 64) 0 pool_1 (MaxPooling2D) (None, 112, 112, 64) 0 conv_2 (Conv2D) (None, 112, 112, 128) 73856 norm_2 (BatchNormalization (None, 112, 112, 128) 512 ) actv_2 (Activation) (None, 112, 112, 128) 0 pool_2 (MaxPooling2D) (None, 56, 56, 128) 0 conv_3 (Conv2D) (None, 56, 56, 256) 295168 norm_3 (BatchNormalization (None, 56, 56, 256) 1024 ) actv_3 (Activation) (None, 56, 56, 256) 0 aver (GlobalAveragePooling (None, 256) 0 2D) flatten (Flatten) (None, 256) 0 dense_0_dense (Dense) (None, 1024) 263168 dense_0_dropout (Dropout) (None, 1024) 0 dense_1_dense (Dense) (None, 512) 524800 dense_1_dropout (Dropout) (None, 512) 0 outputs (Dense) (None, 2) 1026 ================================================================= Total params: 1160450 (4.43 MB) Trainable params: 1159554 (4.42 MB) Non-trainable params: 896 (3.50 KB) _________________________________________________________________ --- Model training --------------------------------------------------- Epoch 1/40 131/131 [==============================] - ETA: 0s - loss: 0.3664 - accuracy: 0.8327 - auc: 0.9168 Epoch 1: val_auc improved from -inf to 0.74021, saving model to /kaggle/working/model/ShallowCNN.ckpt 131/131 [==============================] - 28s 163ms/step - loss: 0.3664 - accuracy: 0.8327 - auc: 0.9168 - val_loss: 2.8615 - val_accuracy: 0.7402 - val_auc: 0.7402 Epoch 2/40 131/131 [==============================] - ETA: 0s - loss: 0.2852 - accuracy: 0.8710 - auc: 0.9496 Epoch 2: val_auc did not improve from 0.74021 131/131 [==============================] - 18s 136ms/step - loss: 0.2852 - accuracy: 0.8710 - auc: 0.9496 - val_loss: 3.2940 - val_accuracy: 0.7402 - val_auc: 0.7402 Epoch 3/40 131/131 [==============================] - ETA: 0s - loss: 0.2840 - accuracy: 0.8786 - auc: 0.9507 Epoch 3: val_auc did not improve from 0.74021 131/131 [==============================] - 18s 136ms/step - loss: 0.2840 - accuracy: 0.8786 - auc: 0.9507 - val_loss: 2.9459 - val_accuracy: 0.7402 - val_auc: 0.7402 Epoch 4/40 131/131 [==============================] - ETA: 0s - loss: 0.2607 - accuracy: 0.8908 - auc: 0.9587 Epoch 4: val_auc did not improve from 0.74021 131/131 [==============================] - 18s 136ms/step - loss: 0.2607 - accuracy: 0.8908 - auc: 0.9587 - val_loss: 2.4346 - val_accuracy: 0.7402 - val_auc: 0.7402 Epoch 5/40 131/131 [==============================] - ETA: 0s - loss: 0.2720 - accuracy: 0.8815 - auc: 0.9547 Epoch 5: val_auc improved from 0.74021 to 0.91602, saving model to /kaggle/working/model/ShallowCNN.ckpt 131/131 [==============================] - 20s 153ms/step - loss: 0.2720 - accuracy: 0.8815 - auc: 0.9547 - val_loss: 0.3597 - val_accuracy: 0.8176 - val_auc: 0.9160 Epoch 6/40 131/131 [==============================] - ETA: 0s - loss: 0.2685 - accuracy: 0.8851 - auc: 0.9560 Epoch 6: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 134ms/step - loss: 0.2685 - accuracy: 0.8851 - auc: 0.9560 - val_loss: 1.6074 - val_accuracy: 0.3438 - val_auc: 0.4344 Epoch 7/40 131/131 [==============================] - ETA: 0s - loss: 0.2653 - accuracy: 0.8879 - auc: 0.9568 Epoch 7: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 136ms/step - loss: 0.2653 - accuracy: 0.8879 - auc: 0.9568 - val_loss: 0.4351 - val_accuracy: 0.8491 - val_auc: 0.9059 Epoch 8/40 131/131 [==============================] - ETA: 0s - loss: 0.2437 - accuracy: 0.8965 - auc: 0.9639 Epoch 8: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 135ms/step - loss: 0.2437 - accuracy: 0.8965 - auc: 0.9639 - val_loss: 2.0558 - val_accuracy: 0.2951 - val_auc: 0.3835 Epoch 9/40 131/131 [==============================] - ETA: 0s - loss: 0.2298 - accuracy: 0.9090 - auc: 0.9680 Epoch 9: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 136ms/step - loss: 0.2298 - accuracy: 0.9090 - auc: 0.9680 - val_loss: 2.2041 - val_accuracy: 0.3610 - val_auc: 0.4524 Epoch 10/40 131/131 [==============================] - ETA: 0s - loss: 0.2353 - accuracy: 0.9025 - auc: 0.9663 Epoch 10: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 136ms/step - loss: 0.2353 - accuracy: 0.9025 - auc: 0.9663 - val_loss: 2.4885 - val_accuracy: 0.7402 - val_auc: 0.7421 Epoch 11/40 131/131 [==============================] - ETA: 0s - loss: 0.2359 - accuracy: 0.8992 - auc: 0.9660 Epoch 11: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 134ms/step - loss: 0.2359 - accuracy: 0.8992 - auc: 0.9660 - val_loss: 3.9542 - val_accuracy: 0.2884 - val_auc: 0.3418 Epoch 12/40 131/131 [==============================] - ETA: 0s - loss: 0.2238 - accuracy: 0.9087 - auc: 0.9692 Epoch 12: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 135ms/step - loss: 0.2238 - accuracy: 0.9087 - auc: 0.9692 - val_loss: 3.9108 - val_accuracy: 0.2989 - val_auc: 0.3346 Epoch 13/40 131/131 [==============================] - ETA: 0s - loss: 0.2226 - accuracy: 0.9094 - auc: 0.9696 Epoch 13: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 135ms/step - loss: 0.2226 - accuracy: 0.9094 - auc: 0.9696 - val_loss: 2.0640 - val_accuracy: 0.3133 - val_auc: 0.4007 Epoch 14/40 131/131 [==============================] - ETA: 0s - loss: 0.2175 - accuracy: 0.9118 - auc: 0.9713 Epoch 14: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 137ms/step - loss: 0.2175 - accuracy: 0.9118 - auc: 0.9713 - val_loss: 2.2555 - val_accuracy: 0.7402 - val_auc: 0.7367 Epoch 15/40 131/131 [==============================] - ETA: 0s - loss: 0.2074 - accuracy: 0.9171 - auc: 0.9738 Epoch 15: val_auc did not improve from 0.91602 131/131 [==============================] - 18s 135ms/step - loss: 0.2074 - accuracy: 0.9171 - auc: 0.9738 - val_loss: 1.5446 - val_accuracy: 0.7402 - val_auc: 0.7854 --- Training history -------------------------------------------------
--- Test Predictions and Metrics -------------------------------------
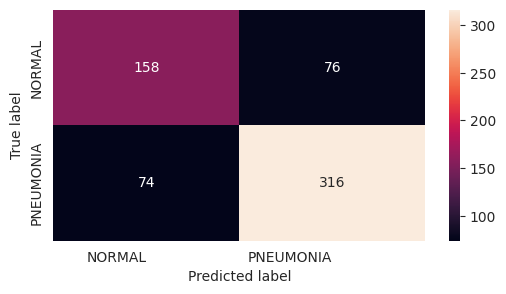
precision recall f1-score support
NORMAL 0.68 0.68 0.68 234
PNEUMONIA 0.81 0.81 0.81 390
accuracy 0.76 624
macro avg 0.74 0.74 0.74 624
weighted avg 0.76 0.76 0.76 624
=== MODEL EVALUATION FINISHED ========================================
Příště budu pokračovat již zajímavějším modelem, a tím je VGG16.
Žádné názory






















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU