Detectron2 - jak vlastně funguje
Hned na začátku se musím omluvit za poněkud zavádějící nadpis. Detectron 2 je jeho autory označován za platformu pro detekci objektů, segmentaci a další vizuální úkoly. Co si pod tím ale představit? Jedná se o sadu modelů, které byly pro tyto účely navrženy a trénovány na vybraných datových sadách. Vy si můžete tyto modely stáhnout včetně zdrojových kódů a používat v souladu s licencí.
Takže pokud bych se chtěl dozvědět, jak taková platforma funguje, musím si zvolit nějaký úkol a k němu vybrat vhodný model. No a pak se podívat, jak tento model v konkrétním případě funguje. A o to se pokusím v tomto článku.
Zvolené zadání
Pro své zkoumání jsem si vybral jeden ze základních úkolů platformy, a to je detekce objektů na obrázku. Jako výchozí jsem si zvolil model Faster R-CNN trénovaný na datové sadě COCO Dataset.
Používané podklady
Své bádání jsem nedělal na zelené louce. Prvotní inspirací byla sada článků Digging into Detectron 2, na kterou budu v mnoha bodech navazovat. Dále byly pro mne zásadním zdrojem informací o modelu a jeho chování zdrojové kódy. Bez nich by bylo obtížné pochopit celý proces odvození od surových dat obrázku až po konečnou predikci objektů.
Rozsah mého bádání
A ještě poslední informace na úvod, než se pustím do samotného tématu. Zaměřil jsem se pouze na proces inference, tedy vytvoření predikce na trénovaném modelu. Proces trénování jsem v tomto textu záměrně pominul, neb ten je výrazně komplikovanější a problémů s tím spojených je na jeden článek skutečně hodně. Tak snad to bude téma na některý z příštích příspěvků.
Příprava prostředí
Následuje jen rychlý přehled kroků, které je potřeba udělat pro instalaci Detectron 2 do běhového prostředí Kaggle.
!git clone 'https://github.com/facebookresearch/detectron2' Cloning into 'detectron2'... remote: Enumerating objects: 15832, done. remote: Counting objects: 100% (62/62), done. remote: Compressing objects: 100% (50/50), done. remote: Total 15832 (delta 27), reused 12 (delta 12), pack-reused 15770 (from 2) Receiving objects: 100% (15832/15832), 6.40 MiB | 26.42 MiB/s, done. Resolving deltas: 100% (11529/11529), done.
import sys, os, distutils.core
dist = distutils.core.run_setup("./detectron2/setup.py")
!python -m pip install {' '.join([f"'{x}'" for x in dist.install_requires])}
sys.path.insert(0, os.path.abspath('./detectron2'))
Ignoring dataclasses: markers 'python_version < "3.7"' don't match your environment
Requirement already satisfied: Pillow>=7.1 in /opt/conda/lib/python3.10/site-packages (10.3.0)
Requirement already satisfied: matplotlib in /opt/conda/lib/python3.10/site-packages (3.7.5)
Collecting pycocotools>=2.0.2
Downloading pycocotools-2.0.8-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (1.1 kB)
Requirement already satisfied: termcolor>=1.1 in /opt/conda/lib/python3.10/site-packages (2.4.0)
Collecting yacs>=0.1.8
Downloading yacs-0.1.8-py3-none-any.whl.metadata (639 bytes)
Requirement already satisfied: tabulate in /opt/conda/lib/python3.10/site-packages (0.9.0)
Requirement already satisfied: cloudpickle in /opt/conda/lib/python3.10/site-packages (3.0.0)
Requirement already satisfied: tqdm>4.29.0 in /opt/conda/lib/python3.10/site-packages (4.66.4)
Requirement already satisfied: tensorboard in /opt/conda/lib/python3.10/site-packages (2.16.2)
Collecting fvcore<0.1.6,>=0.1.5
Downloading fvcore-0.1.5.post20221221.tar.gz (50 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 50.2/50.2 kB 2.4 MB/s eta 0:00:00
Preparing metadata (setup.py) ... - done
Collecting iopath<0.1.10,>=0.1.7
Downloading iopath-0.1.9-py3-none-any.whl.metadata (370 bytes)
Collecting omegaconf<2.4,>=2.1
Downloading omegaconf-2.3.0-py3-none-any.whl.metadata (3.9 kB)
Collecting hydra-core>=1.1
Downloading hydra_core-1.3.2-py3-none-any.whl.metadata (5.5 kB)
Collecting black
Downloading black-24.10.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_28_x86_64.whl.metadata (79 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 79.2/79.2 kB 5.4 MB/s eta 0:00:00
Requirement already satisfied: packaging in /opt/conda/lib/python3.10/site-packages (21.3)
Requirement already satisfied: contourpy>=1.0.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (1.2.1)
Requirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (4.53.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (1.4.5)
Requirement already satisfied: numpy<2,>=1.20 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (1.26.4)
Requirement already satisfied: pyparsing>=2.3.1 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (3.1.2)
Requirement already satisfied: python-dateutil>=2.7 in /opt/conda/lib/python3.10/site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: PyYAML in /opt/conda/lib/python3.10/site-packages (from yacs>=0.1.8) (6.0.2)
Requirement already satisfied: absl-py>=0.4 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (1.4.0)
Requirement already satisfied: grpcio>=1.48.2 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (1.62.2)
Requirement already satisfied: markdown>=2.6.8 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (3.6)
Requirement already satisfied: protobuf!=4.24.0,>=3.19.6 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (3.20.3)
Requirement already satisfied: setuptools>=41.0.0 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (70.0.0)
Requirement already satisfied: six>1.9 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (1.16.0)
Requirement already satisfied: tensorboard-data-server<0.8.0,>=0.7.0 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (0.7.2)
Requirement already satisfied: werkzeug>=1.0.1 in /opt/conda/lib/python3.10/site-packages (from tensorboard) (3.0.4)
Collecting portalocker (from iopath<0.1.10,>=0.1.7)
Downloading portalocker-3.1.1-py3-none-any.whl.metadata (8.6 kB)
Collecting antlr4-python3-runtime==4.9.* (from omegaconf<2.4,>=2.1)
Downloading antlr4-python3-runtime-4.9.3.tar.gz (117 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 117.0/117.0 kB 9.2 MB/s eta 0:00:00
Preparing metadata (setup.py) ... - done
Requirement already satisfied: click>=8.0.0 in /opt/conda/lib/python3.10/site-packages (from black) (8.1.7)
Requirement already satisfied: mypy-extensions>=0.4.3 in /opt/conda/lib/python3.10/site-packages (from black) (1.0.0)
Collecting packaging
Downloading packaging-24.2-py3-none-any.whl.metadata (3.2 kB)
Collecting pathspec>=0.9.0 (from black)
Downloading pathspec-0.12.1-py3-none-any.whl.metadata (21 kB)
Requirement already satisfied: platformdirs>=2 in /opt/conda/lib/python3.10/site-packages (from black) (3.11.0)
Requirement already satisfied: tomli>=1.1.0 in /opt/conda/lib/python3.10/site-packages (from black) (2.0.1)
Requirement already satisfied: typing-extensions>=4.0.1 in /opt/conda/lib/python3.10/site-packages (from black) (4.12.2)
Requirement already satisfied: MarkupSafe>=2.1.1 in /opt/conda/lib/python3.10/site-packages (from werkzeug>=1.0.1->tensorboard) (2.1.5)
Downloading pycocotools-2.0.8-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (427 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 427.8/427.8 kB 11.9 MB/s eta 0:00:00
Downloading yacs-0.1.8-py3-none-any.whl (14 kB)
Downloading iopath-0.1.9-py3-none-any.whl (27 kB)
Downloading omegaconf-2.3.0-py3-none-any.whl (79 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 79.5/79.5 kB 5.1 MB/s eta 0:00:00
Downloading hydra_core-1.3.2-py3-none-any.whl (154 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 154.5/154.5 kB 10.6 MB/s eta 0:00:00
Downloading black-24.10.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_28_x86_64.whl (1.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 57.6 MB/s eta 0:00:00
Downloading packaging-24.2-py3-none-any.whl (65 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 65.5/65.5 kB 4.1 MB/s eta 0:00:00
Downloading pathspec-0.12.1-py3-none-any.whl (31 kB)
Downloading portalocker-3.1.1-py3-none-any.whl (19 kB)
Building wheels for collected packages: fvcore, antlr4-python3-runtime
Building wheel for fvcore (setup.py) ... - \ done
Created wheel for fvcore: filename=fvcore-0.1.5.post20221221-py3-none-any.whl size=61400 sha256=8ea1836d463f8d84f0285efbd0cb0c116fede1ca159fc66a11d4b027b8820b53
Stored in directory: /root/.cache/pip/wheels/01/c0/af/77c1cf53a1be9e42a52b48e5af2169d40ec2e89f7362489dd0
Building wheel for antlr4-python3-runtime (setup.py) ... - \ done
Created wheel for antlr4-python3-runtime: filename=antlr4_python3_runtime-4.9.3-py3-none-any.whl size=144554 sha256=4e31db68abfbb46b12d171465dcaf79d0a17501595a99d680e66da328c0b8b3e
Stored in directory: /root/.cache/pip/wheels/12/93/dd/1f6a127edc45659556564c5730f6d4e300888f4bca2d4c5a88
Successfully built fvcore antlr4-python3-runtime
Installing collected packages: antlr4-python3-runtime, yacs, portalocker, pathspec, packaging, omegaconf, iopath, hydra-core, black, pycocotools, fvcore
Attempting uninstall: packaging
Found existing installation: packaging 21.3
Uninstalling packaging-21.3:
Successfully uninstalled packaging-21.3
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
cudf 24.8.3 requires cubinlinker, which is not installed.
cudf 24.8.3 requires cupy-cuda11x>=12.0.0, which is not installed.
cudf 24.8.3 requires ptxcompiler, which is not installed.
cuml 24.8.0 requires cupy-cuda11x>=12.0.0, which is not installed.
dask-cudf 24.8.3 requires cupy-cuda11x>=12.0.0, which is not installed.
cudf 24.8.3 requires cuda-python<12.0a0,>=11.7.1, but you have cuda-python 12.6.0 which is incompatible.
distributed 2024.7.1 requires dask==2024.7.1, but you have dask 2024.9.1 which is incompatible.
google-cloud-bigquery 2.34.4 requires packaging<22.0dev,>=14.3, but you have packaging 24.2 which is incompatible.
jupyterlab 4.2.5 requires jupyter-lsp>=2.0.0, but you have jupyter-lsp 1.5.1 which is incompatible.
jupyterlab-lsp 5.1.0 requires jupyter-lsp>=2.0.0, but you have jupyter-lsp 1.5.1 which is incompatible.
libpysal 4.9.2 requires shapely>=2.0.1, but you have shapely 1.8.5.post1 which is incompatible.
rapids-dask-dependency 24.8.0a0 requires dask==2024.7.1, but you have dask 2024.9.1 which is incompatible.
ydata-profiling 4.10.0 requires scipy<1.14,>=1.4.1, but you have scipy 1.14.1 which is incompatible.
Successfully installed antlr4-python3-runtime-4.9.3 black-24.10.0 fvcore-0.1.5.post20221221 hydra-core-1.3.2 iopath-0.1.9 omegaconf-2.3.0 packaging-24.2 pathspec-0.12.1 portalocker-3.1.1 pycocotools-2.0.8 yacs-0.1.8
Je dobré si ověřit výsledek instalace. Takto to vypadá:
import torch, detectron2
!nvcc --version
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1]
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
print("detectron2:", detectron2.__version__)
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed_Nov_22_10:17:15_PST_2023
Cuda compilation tools, release 12.3, V12.3.107
Build cuda_12.3.r12.3/compiler.33567101_0
torch: 2.4 ; cuda: 2.4.0
detectron2: 0.6
Model Faster R-CNN R-50 FPN
Pro své bádání jsem si zvolil jeden za základních modelů pro detekci objektů. O co se jedná:
|
typ modelu: |
Faster R-CNN |
Towards Real-Time Object Detection with Region Proposal Networks |
|
klasifikační páteř: |
ResNet-50 |
|
|
model vlastností: |
FPN |
Co bude mým dalším krokem? Vytvořím si takový model a naplním jej váhami, které byly trénovány na COCO Dataset. Jen pro ověření zopakuji postup z předchozích článků o framework, kdy jsem vyzkoušel detekci medvěda a osob na jednom vzorovém obrázku.
import detectron2 from detectron2.utils.logger import setup_logger setup_logger() import cv2, random import numpy as np import matplotlib.pyplot as plt from detectron2 import model_zoo from detectron2.engine import DefaultPredictor from detectron2.config import get_cfg from detectron2.utils.visualizer import Visualizer from detectron2.data import MetadataCatalog, DatasetCatalog
Stáhnu si vzorový obrázek, který jsem používal již dříve:
!wget http://farm8.staticflickr.com/7422/9543633506_36574fe48f_z.jpg -q -O input.jpg
image = cv2.imread("./input.jpg")
print(image.shape)
(425, 639, 3)
A nyní si připravím konfiguraci pro mnou zamýšlený model:
MODEL_CONFIG = "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml" cfg = get_cfg() cfg.merge_from_file(model_zoo.get_config_file(MODEL_CONFIG)) cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(MODEL_CONFIG)
Následujícím krokem si vytvořím prázdný model dle konfigurace. Můžete si povšimnout také třídy, podle které je model vytvořen (může se vám hodit při bádání ve zdrojových kódech).
from detectron2.modeling import build_model model = build_model(cfg).eval() print(type(model)) <class 'detectron2.modeling.meta_arch.rcnn.GeneralizedRCNN'>
Vytvořený model je zatím iniciován náhodnými čísly. Potřebuji do něj dostat váhy trénované na datové sadě, proto je potřeba udělat následující krok:
from detectron2.checkpoint import DetectionCheckpointer _ = DetectionCheckpointer(model).load(cfg.MODEL.WEIGHTS) [01/08 13:48:38 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl ... model_final_280758.pkl: 167MB [00:00, 180MB/s]
Model mám připraven, co ale jeho vstup? Stáhl jsem si jeden barevný obrázek s rozlišením (šířka x výška) 639×425 bodů. To ale pro model není vhodné rozlišení. Potřebuji jej upravit tak, aby modelu vyhovoval. V konfiguraci modelu jsou dva parametry, INPUT.MIN_SIZE_TEST a INPUT.MAX_SIZE_TEST, které specifikují minimální respektive maximální velikost obrázku. Dále potřebuji zajistit, aby zůstal zachován poměr velikosti stran obrázku. Na to vše je připravena třída ResizeShortestEdge:
from detectron2.data.transforms import ResizeShortestEdge
print(f"MIN SIZE:{cfg.INPUT.MIN_SIZE_TEST}, MAX SIZE:{cfg.INPUT.MAX_SIZE_TEST}")
aug = ResizeShortestEdge([cfg.INPUT.MIN_SIZE_TEST, cfg.INPUT.MIN_SIZE_TEST], cfg.INPUT.MAX_SIZE_TEST)
img = aug.get_transform(image).apply_image(image)
img = torch.as_tensor(img.astype(np.float32).transpose(2, 0, 1))
print(f"IMAGE Shape: {img.shape}")
MIN SIZE:800, MAX SIZE:1333
IMAGE Shape: torch.Size([3, 800, 1203])
Jak vidíte z předchozího výpisu, zdrojový obrázek byl zvětšen do velikosti 1203×800 bodů. Následně jsem z něj vytvořil tensor, ve struktuře CxHxW, tedy C je rozměr pro kódování barvy BGR, H je výška obrázku a W je jeho šířka. Tuto strukturu vstupu požaduje mnou vybraný model.
Abych viděl, že mně model funguje, vyzkouším si vytvořit predikci:
height, width = image.shape[:2]
inputs = {"image": img, "height": height, "width": width}
predicitions = model([inputs])[0]
/opt/conda/lib/python3.10/site-packages/torch/functional.py:513: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /usr/local/src/pytorch/aten/src/ATen/native/TensorShape.cpp:3609.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
A takto vypadá predikce pro nalezené instance objektů. Byl nalezen jeden medvěd a deset osob včetně jejich označujících obdélníků:
instances = predicitions['instances']
print(instances.pred_classes)
print(instances.pred_boxes)
tensor([ 0, 21, 0, 0, 0, 0, 0, 0, 0, 0, 0], device='cuda:0')
Boxes(tensor([[2.9120e+02, 7.8487e+01, 3.4126e+02, 2.3231e+02],
[2.0032e+02, 2.3424e+02, 3.5946e+02, 3.3467e+02],
[1.1226e+02, 1.4690e+00, 1.3525e+02, 7.2142e+01],
[3.5216e+02, 6.2447e+01, 3.9826e+02, 2.1437e+02],
[4.0417e+02, 6.3487e+01, 4.4739e+02, 1.8555e+02],
[4.2800e+02, 6.7188e+01, 4.7999e+02, 2.0303e+02],
[1.2878e+02, 7.7678e+00, 1.5183e+02, 7.0387e+01],
[2.0399e+02, 1.3578e-01, 2.2819e+02, 4.0504e+01],
[2.7686e+02, 8.2188e+01, 3.0489e+02, 1.7347e+02],
[3.3707e+02, 6.9724e+01, 3.6491e+02, 1.9995e+02],
[1.3833e+02, 1.5419e+00, 1.5679e+02, 6.4402e+01]], device='cuda:0',
grad_fn=<IndexBackward0>))
Výsledek si ještě zkusím zobrazit, abych si ověřil pohledem, že to skutečně sedí:
v = Visualizer(image[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(instances.to("cpu"))
fig=plt.figure(figsize=(14, 6))
plt.imshow(out.get_image())
plt.show()

Základní struktura modelu
Konečně se dostávám k vlastnímu tématu tohoto článku. Podívám se hlouběji do vnitřností modelu, který jsem si v předchozích krocích vytvořil.
Pro podporu svého konání použiji obrázky kolegy Hirito Honda z článků „Digging into Detectron 2“. Takto on zobrazuje základní komponenty modelu Faster R-CNN:
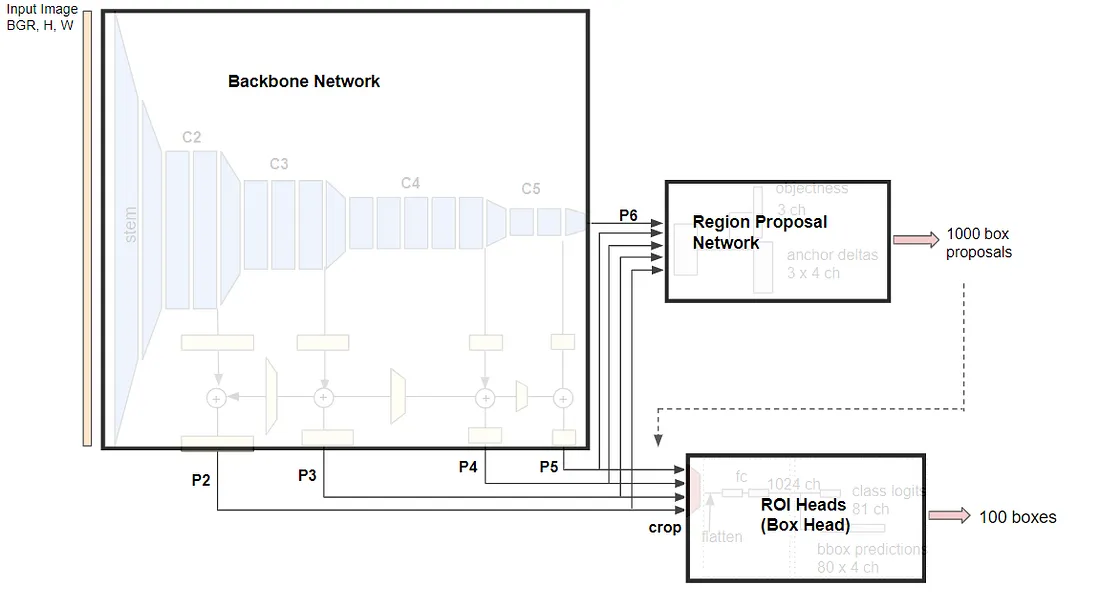
Model se skládá ze tří základních komponent:
-
Backbone Network – v mém případě se jedná o Feature Pyramid Network (FPN). Jejím hlavním úkolem je extrakce vlastností ze zdrojového obrázku, a to v několika úrovních rozlišení.
-
Regional Proposal Network (RPN) – síť navrhuje obdélníky, které by mohly obsahovat objekty. Opět se jedná o návrhy v různých úrovních rozlišení. Dle konfigurace může síť navrhovat až 1000 obdélníků k dalšímu výběru.
-
ROI Heads – síť bere jako vstup vlastnosti z FPN, které jsou ořezány a přizpůsobeny dle obdélníků navržených RPN. Následně jsou tyto sady vlastností klasifikovány podle známých objektů a vybrány ty nejlepší z nich (dle konfigurace 100 obdélníků s nejlepšími klasifikačními výsledky).
Na všechny tři základní komponenty se podívám detailněji v následujících kapitolách.
Feature Pyramid Network (FPN)
Tato komponenta má zajistit extrakci vlastností ze zdrojového obrázku. Pro tento účel se obvykle používá nějaká varianta klasifikační konvoluční sítě, která postupně v několika fázích redukuje prostorové dimenze a vytváří širší sadu vlastností (v tomto případě se ale vypouštějí plně propojené vrstvy MLP, které provádí samotnou klasifikaci na základě extrahovaných vlastností).
Pro tento účel je opět v rámci platformy možné zvolit více variant. Já jsem vyšel z modelu ResNet 50, tedy jednoho z často používaných a citovaných.
Není to ale vše. V klasifikačních modelech obvykle vycházíme z poslední, tedy nejobecnější sady vlastností. Z ní pak provádíme klasifikaci pomocí MLP. V tomto případě ale potřebujeme něco jiného. A to je promítnout zpětně ty nejobecnější vlastnosti (vzešlé z nejmenšího rozlišení) do vlastností s větším rozlišením. Jedná se u nějakou obdobu U-Net, ale ne tak úplně. Cílem tohoto kroku je dostat jednu sadu vlastností, dle konfigurace je to 256, ale v různých úrovních rozlišení.
A proč to vlastně chci? Představte si situaci, která je vidět i na vzorovém obrázku. Několik osob stojí blízko medvěda, a jsou tedy na obrázku větší. No a několik dalších osob stojí v pozadí, na obrázku jsou jejich siluety menší. Potřebuji tedy nalézt objekty, které jsou velké i ty malé. Proto vytvářím „pyramidu“ vlastností s ohledem na velikost rozlišení.
Takto zobrazuje FPN kolega Honda:
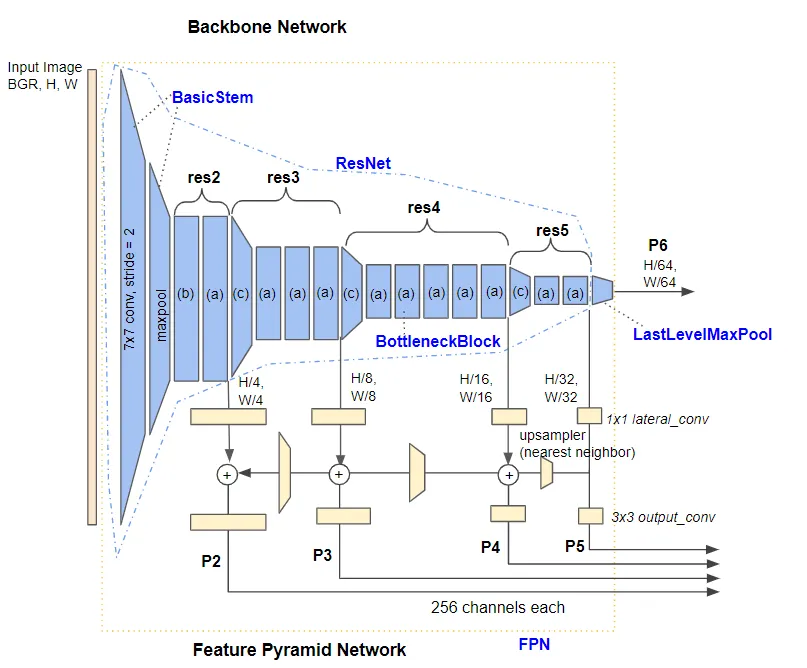
Vstup pro FPN
Vycházím z toho, že budu provádět predikci na jednom obrázku. Ten mám aktuálně načtený do tensoru img ve struktuře CxHxW.
Dříve, než obrázek pošlu do FPN, potřebuji udělat ještě další úpravy. Postupně se obrázek normalizuje s využitím konstant specifikovaných v konfiguraci (získané v průběhu trénování na konkrétní sadě dat). Dále se přidají výplně tak, aby dimenze odpovídaly konkrétnímu modelu. A na závěr se vše zapouzdří do datové struktury ImageList. A to je ten formát dat, který potřebuji pro vstup do komponenty.
images = model.preprocess_image([inputs])
print(f"Type: {type(images)} --> Dimensiopns:{[i.shape for i in images]}")
Type: <class 'detectron2.structures.image_list.ImageList'> --> Dimensiopns:[torch.Size([3, 800, 1203])]
ResNet 50 Backbone
Jedná se o obvyklou podobu modelu ResNet postavenou na konvolučních vrstvách doplněných o „skip connections“. S ohledem na tento fakt nebudu dále rozepisovat detailněji strukturu modelu a význam jednotlivých vrstev, článků na toto téma je napsáno dost (taky jsem jeden skromný příspěvek dříve napsal). Omezím se pouze na konstatování, co se v modelu děje.
backbone = model.backbone
print(f"Type: {type(backbone)}")
Type: <class 'detectron2.modeling.backbone.fpn.FPN'>
Na vstupu modelu je konvoluční vrstva s velikostí kernelu 7 a krokem 2. Ta je následována MaxPooling vrstvou s krokem také 2. Výsledkem je tedy první sada vlastností s redukcí rozměrových dimenzí čtyřikrát (můžeme jí také označit za res1).
Následuje první sada konvolučních bloků, jejichž výsledkem je první sada 256 vlastností s prostorovými dimenzemi redukovanými na čtvrtinu velikosti původního obrázku. V diagramu je tento blok označen jako res2. Je to také první blok, jehož výstup budeme potřebovat pro další zpracování.
Celý postup pokračuje dalšími konvolučními bloky, které postupně redukují prostorové dimenze na polovinu (nastavením kroku 2 na konvoluční vrstvě), a současně navyšují dvojnásobně počet vlastností. Jedná se o bloky res3, res4 a res5. Výstupy těchto vrstev opět budu dále potřebovat.
Na výstup ResNet backbone se můžu podívat:
bottom_up_features = backbone.bottom_up(images.tensor)
print(f"Type: {type(bottom_up_features)} Keys:{bottom_up_features.keys()}")
Type: <class 'dict'> Keys:dict_keys(['res2', 'res3', 'res4', 'res5'])
for k in bottom_up_features:
print(f"Block: {k} --> Dimensions: {bottom_up_features[k].shape}")
Block: res2 --> Dimensions: torch.Size([1, 256, 200, 304])
Block: res3 --> Dimensions: torch.Size([1, 512, 100, 152])
Block: res4 --> Dimensions: torch.Size([1, 1024, 50, 76])
Block: res5 --> Dimensions: torch.Size([1, 2048, 25, 38])
Na výpisu můžete jednoduše vidět, jak jsou v jednotlivých blocích postupně redukovány prostorové dimenze a současně rozšiřovány počty vlastností.
To ještě ale není vše. Potřebuji se dostat k vlastnostem promítnutým do různých úrovní rozlišení původního obrázku. Na to potřebuji ještě expanzní fázi.
Expanzní fáze FPN
Expanzní fáze vychází z toho, co dostala jako vstup z backbone, tedy tensory res2 až res5.
Výsledek Feature Pyramid Network je poskládán z tensorů reprezentujících 256 vlastností v různých úrovních rozlišení, označované dále jako P2 až P6. Vytváří se postupnou zpětnou projekcí vrstev s nižším rozlišením do vrstev z rozlišením větším.
P5 – Základem je výstup res5 z páteře. Nejdříve je aplikována tzv. lateral convolution. Ta má velikost kernelu 1×1, počet výstupních vlastností je 256, čímž byla provedena redukce vlastností res5 z původních 2048 na 256. Následuje tzv. output convolution, což je vrstva s velikostí kernelu 3×3, a počet vlastností zůstává zachován.
P4 – Opět primárně vychází z výstupu res4 páteře, který je v prvním kroku laterální konvolucí projektován do 256 vlastností. V tomto okamžiku se přičítá tensor z laterální konvoluce P5, který byl ještě předtím interpolací rozšířen na dvojnásobnou velikost (pro sečtení tensorů je potřeba, aby měly stejnou prostorovou velikost i stejný počet vlastností). Na závěr je poslán tento součet do output convolution, což je opět velikost kernelu 3×3 se stejným počtem vlastností.
P3 a P2 – tyto výstupy se tvoří obdobně, jako tomu bylo u výstupu P4, jen je potřeba vždy zvolit ty správné vstupní tensory z páteře a vyšších vrstev.
No a ještě chybí jeden výstup:
P6 – ten se tvoří jednoduše tak, že se vezme výstup P5, který je vrstvou MaxPooling prostorově zmenšen na polovinu.
Jak to tedy vypadá, když si vyzkouším zavolat celou komponentu FPN:
features = backbone(images.tensor)
print(f"Type: {type(features)} Keys:{features.keys()}\n")
for k in features:
print(f"Block: {k} --> Dimensions: {features[k].shape}")
Type: <class 'dict'> Keys:dict_keys(['p2', 'p3', 'p4', 'p5', 'p6'])
Block: p2 --> Dimensions: torch.Size([1, 256, 200, 304])
Block: p3 --> Dimensions: torch.Size([1, 256, 100, 152])
Block: p4 --> Dimensions: torch.Size([1, 256, 50, 76])
Block: p5 --> Dimensions: torch.Size([1, 256, 25, 38])
Block: p6 --> Dimensions: torch.Size([1, 256, 13, 19])
Z výpisu je vidět, že mám pyramidu 256 vlastností v rozlišení redukovaném proti původnímu obrázku 4×, 8×, 16×, 32× a 64×.
Letmý náhled na pyramidu vlastností
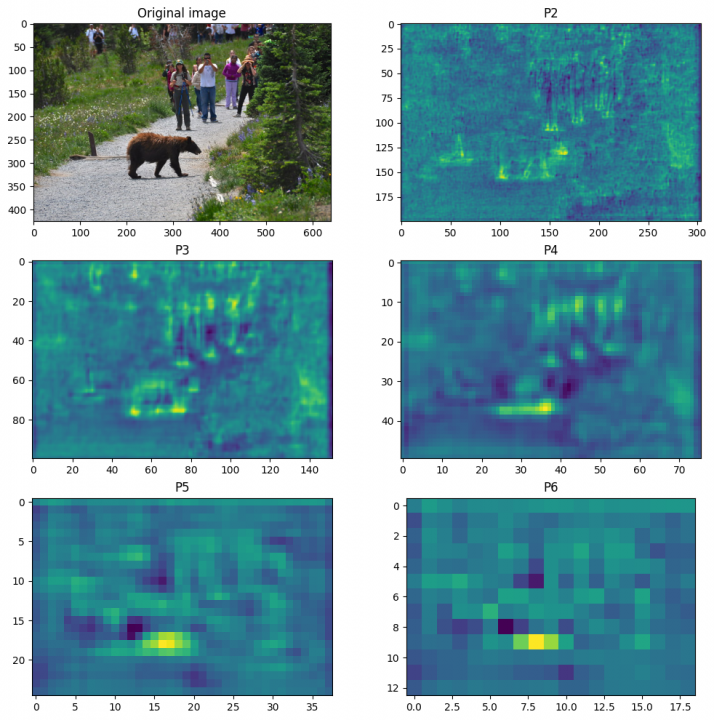
Zkusím se rychle podívat, jak vypadá taková pyramida vlastností. Vzhledem k tomu, že těch vlastností mám 256, budu si muset jednu vybrat, tak například rovnou tu první. No a zkusím si jí zobrazit jako heatmap ve všech vrstvách.
Takto vypadá jedna vlastnost včetně původního obrázku:
rows, cols = 3, 2
fig=plt.figure(figsize=(12, 12))
ax = fig.add_subplot(rows, cols, 1)
ax.title.set_text("Original image")
plt.imshow(image[:, :, ::-1])
for i, p in enumerate(['p2', 'p3', 'p4', 'p5', 'p6'], start=2):
ax = fig.add_subplot(rows, cols, i)
ax.title.set_text(p.upper())
f = np.expand_dims(np.squeeze(features[p].cpu().detach().numpy())[0, :], axis=-1)
f = f - f.min()
f = f / f.max() * 255.0
plt.imshow(f)
plt.show()
Regional Proposal Network (RPN)
Druhou komponentou v rámci celého modelu je Regional Proposal Network. Jedná se o zásadní komponentu pro fungování celého modelu. Úkolem RPN je navrhnout různě veliké obdélníky a k nim přiřadit pravděpodobnost, že obsahují nějaký objekt.
Takto zobrazuje RPN kolega Honda:
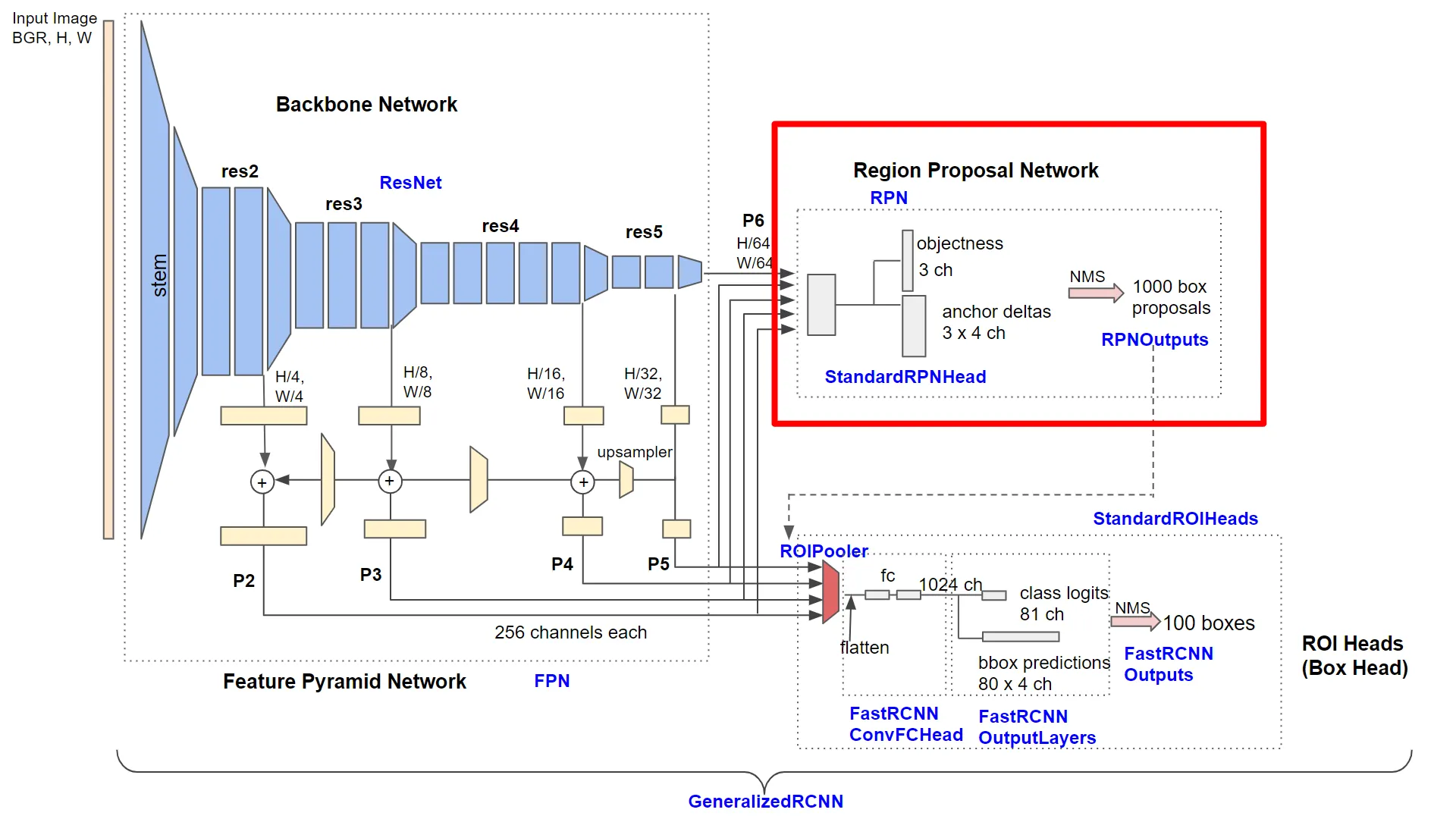
RPN se skládá ze dvou částí. Tou první je neuronová síť označovaná jako „RPN Head“, druhá část je již pouze výpočetní (neobsahuje tedy žádné parametry pro učení) označena jako „RPN Outputs“.
rpn = model.proposal_generator
print(f"Type: {type(rpn)}\n\n{rpn}")
Type: <class 'detectron2.modeling.proposal_generator.rpn.RPN'>
RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(objectness_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
Kotevní body (anchors) – obdélníky vymezující objekty
Kotevní body (anchors) jsou klíčovým prvkem v architektuře RPN. Slouží jako předem definované referenční boxy, které umožňují modelu efektivně navrhnout regiony obsahující objekty různých velikostí a poměrů stran. Každý pixel ve výstupu RPN mapy odpovídá jedné sadě kotev s různými velikostmi a poměry, což zajišťuje pokrytí různorodých tvarů objektů. Model pak pro každou kotvu predikuje dvě hodnoty: skóre, které vyjadřuje pravděpodobnost přítomnosti objektu, a regresní hodnoty, které upravují kotvu, aby lépe odpovídala skutečnému obrysu objektu.
Při jejich návrhu se musí RPN vypořádat hned s několika problémy.
Zaprvé, objekty mohou mít různou velikost (osoba stojí v popředí snímku nebo někde zastrčená vzadu). Pro řešení tohoto problému jsme si již dříve vytvořili pyramidu vlastností. Proto budeme dále navrhovat velikost obdélníků s ohledem na vrstvu, ke které se ten daný vztahuje.
Druhým problémem je poměr stran obdélníků pro vymezení objektu. Například osoba je významně vyšší než širší objekt (obvykle). Proto potřebujeme navrhnout obdélník, který tuto vlastnost bude reflektovat.
Pro návrh kotevních bodu jsou v rámci konfigurace modelu definovány dva základní parametry:
-
MODEL.ANCHOR_GENERATOR.SIZES – specifikuje velikost referenčního boxu v pixelech, a to pro každou vrstvu zvláště (proto máme v konfiguraci pět velikostí).
-
MODEL.ANCHOR_GENERATOR.ASPECT_RATIOS – definuje poměry stran obdélníků při modifikaci výchozího referenčního boxu (máme definovány tři modifikace).
print(cfg.MODEL.ANCHOR_GENERATOR.SIZES) print(cfg.MODEL.ANCHOR_GENERATOR.ASPECT_RATIOS) [[32], [64], [128], [256], [512]] [[0.5, 1.0, 2.0]]
Jednodušší pro pochopení bude asi obrázek od p. Hondy:

RPN Head
RPN head je tvořen třemi částmi:
-
Sdílená konvoluční vrstva:
Typicky jde o 3×3 konvoluci, která slouží k redukci výpočetní složitosti a sdílení parametrů mezi následnými větvemi. Tato vrstva zpracovává vstupní feature mapu a extrahuje relevantní informace pro další predikce. -
Klasifikační větev (classification branch): Tato větev obsahuje další konvoluční vrstvu (např. 1×1 konvoluce), která predikuje skóre pro každou kotvu. Skóre určuje, zda kotva obsahuje objekt (foreground) nebo je součástí pozadí (background). Výstupem je tensor s rozměry odpovídajícími počtu kotev a jejich skóre.
-
Regresní větev (regression branch): Podobně jako klasifikační větev využívá 1×1 konvoluci, ale jejím úkolem je predikovat čtyři regresní parametry (dx, dy, dw, dh) pro každou kotvu. Tyto parametry definují posun a škálování kotvy tak, aby lépe odpovídala skutečnému objektu.
Kombinovaný výstup z obou větví zahrnuje skóre klasifikace a regresní parametry pro každou kotvu. Tento výstup je dále využit k filtrování a zjemnění region proposals pomocí procesů, jako je Non-Maximum Suppression (NMS).
print(f"{type(rpn.rpn_head)}\n\n{rpn.rpn_head}")
<class 'detectron2.modeling.proposal_generator.rpn.StandardRPNHead'>
StandardRPNHead(
(conv): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(objectness_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
RPN Head má v konfiguraci definovány vrstvy vlastností, které očekává na svém vstupu. V mém případě se jedná o všechny vrstvy vytvořené FPN komponentou:
print(rpn.in_features) ['p2', 'p3', 'p4', 'p5', 'p6']
Pro vstup do RPN Head ale potřebuji poněkud jiné uspořádání, a to do seznamu v pořadí od nejdetailnější po nejobecnější:
rpn_features = [features[f] for f in rpn.in_features]
A nyní si již můžu vyzkoušet zavolat RPN Head pro můj testovací obrázek:
pred_objectness_logits, pred_anchor_deltas = rpn.rpn_head(rpn_features)
print(f"Objectness Logits: type={type(pred_objectness_logits)}, length={len(pred_objectness_logits)}\n Shapes:")
for i, v in enumerate(pred_objectness_logits):
print(f" {rpn.in_features[i]}: {pred_objectness_logits[i].shape}")
print()
print(f"Anchor Deltas: type={type(pred_anchor_deltas)}, length={len(pred_anchor_deltas)}\n Shapes:")
for i, v in enumerate(pred_anchor_deltas):
print(f" {rpn.in_features[i]}: {pred_anchor_deltas[i].shape}")
Objectness Logits: type=<class 'list'>, length=5
Shapes:
p2: torch.Size([1, 3, 200, 304])
p3: torch.Size([1, 3, 100, 152])
p4: torch.Size([1, 3, 50, 76])
p5: torch.Size([1, 3, 25, 38])
p6: torch.Size([1, 3, 13, 19])
Anchor Deltas: type=<class 'list'>, length=5
Shapes:
p2: torch.Size([1, 12, 200, 304])
p3: torch.Size([1, 12, 100, 152])
p4: torch.Size([1, 12, 50, 76])
p5: torch.Size([1, 12, 25, 38])
p6: torch.Size([1, 12, 13, 19])
Výstupy z RPN Head jsou hned dva. V obou případech se jedná o seznam pěti tensorů (pět tensorů proto, že mám pět vrstev vlastností z FPN).
Prvním výstupem jsou tzv. „Objectness Logits“, tedy skóre, které vyjadřuje pravděpodobnost existence objektu v daném bodě. Všechny tensory mají stejnou strukturu dimenzí BxLxHxW, kde B je velikost dávky (v mém případě je to 1 pro jeden testovací obrázek), H je počet bodů na výšku obrázku v dané vrstvě, W je počet bodů na šířku obrázku v dané vrstvě, a nakonec je to kýžené L, což značí počet variant (poměrů stran) kotevních bodů.
Druhým výstupem jsou tzv. „Anchor Deltas“, tedy regresní parametry pro úpravu kotevních bodů. Opět se jedná o tenzory se stejnou strukturou BxDxHxW. Význam dimenzí B, H a W je stejný jako tomu bylo v předchozím odstavci. Rozdílná je dimenze D. Jedná se o čtyři regresní parametry (dx, dy, dw, dh) pro každou variantu kotvy. No a mám tři varianty, tak těch parametrů musí být celkově 12.
Zkusím se dále podívat, jak takové objectness logits v mém případě vypadají:
rows, cols = 3, 2
fig=plt.figure(figsize=(12, 12))
ax = fig.add_subplot(rows, cols, 1)
ax.title.set_text("Original image")
plt.imshow(image[:, :, ::-1])
image_shape = image.shape[:2][::-1]
for i, l in enumerate(pred_objectness_logits, start=2):
ax = fig.add_subplot(rows, cols, i)
ax.title.set_text(f"p{i}".upper())
plt.imshow(image[:, :, ::-1])
logits = np.squeeze(l.cpu().detach().numpy())
logits = np.sum(logits, axis=0)
logits = logits - logits.min()
logits = logits / logits.max() * 255.0
logits = cv2.resize(logits, image_shape, fx=0, fy=0, interpolation = cv2.INTER_NEAREST)
plt.imshow(logits, alpha=0.7)
plt.show()

Na předchozích obrázcích je pěkně vidět, jak se model v různých vrstvách zaměřuje na objekty odpovídající velikosti. Vrstvy P2 a P3 detekují spíše objekty malé, v mém případě jsou to postavy v pozadí případně jejich části. Vyšší vrstvy modelu, jako je P4, P5 a P6 se pak zaměřují na objekty větší, což je především medvěd a některé postavy jemu nejbližší.
RPN Outputs
Dostávám se ke druhé části RPN komponenty, a tou je tzv. RPN Outputs. Zde již žádné parametry pro učení nenajdete, jedná se o čistě výpočetní část a příprava výstupu pro použití v poslední komponentě Faster R-CNN modelu.
Jen pro shrnutí, co mám aktuálně k dispozici. V první části jsem si vytvořil dvě sady tensorů reflektující strukturu vrstev z FPN. Tou první sadou tensorů je skóre, pred_objectness_logits, vyjadřující pravděpodobnost, že v daném bodě existuje nějaký objekt. Druhou sadou tensorů jsou regresní parametry, pred_anchor_deltas, pro úpravu velikosti a umístění kotvy objektu v daném bodě.
Mým cílem je vybrat ty kotvy a k nim patřičným způsobem upravené obdélníky, které jsou nejnadějnější pro lokalizaci objektů. Počet obdélníků, které do svého výběru zahrnu, je dán konfigurací modelu. V mém případě to bude 1000 nejlepších.
Pro další postup budu potřebovat ještě něco připravit. Budou to všechny obdélníky odpovídající kotvám ve všech vrstvách. Velikost obdélníků je dána parametry konfigurace MODEL.ANCHOR_GENERATOR.SIZES a MODEL.ANCHOR_GENERATOR.ASPECT_RATIOS (ty jsem již zmiňoval dříve).
anchors = rpn.anchor_generator(rpn_features)
print(f"Type: {type(anchors)} Length:{len(anchors)}")
Type: <class 'list'> Length:5
import matplotlib.patches as patches
fig = plt.figure(figsize=(8, 8))
ax = plt.gca()
plt.imshow(cv2.resize(image[:, :, ::-1], (img.shape[-1], img.shape[-2])))
def draw_boxes(level, reference):
x1, y1, x2, y2 = anchors[level][reference].tensor.cpu().numpy()[-1]
ax.add_patch(patches.Rectangle((x1, y1), x2 -x1, y2-y1, linewidth=3, edgecolor='r', facecolor='none'))
x1, y1, x2, y2 = anchors[level][reference-1].tensor.cpu().numpy()[-1]
ax.add_patch(patches.Rectangle((x1, y1), x2 -x1, y2-y1, linewidth=3, edgecolor='g', facecolor='none'))
x1, y1, x2, y2 = anchors[level][reference+1].tensor.cpu().numpy()[-1]
ax.add_patch(patches.Rectangle((x1, y1), x2 -x1, y2-y1, linewidth=3, edgecolor='b', facecolor='none'))
draw_boxes(0, 10999)
draw_boxes(1, 2800)
draw_boxes(2, 1432)
draw_boxes(3, 1501)
draw_boxes(4, 439)
plt.show()
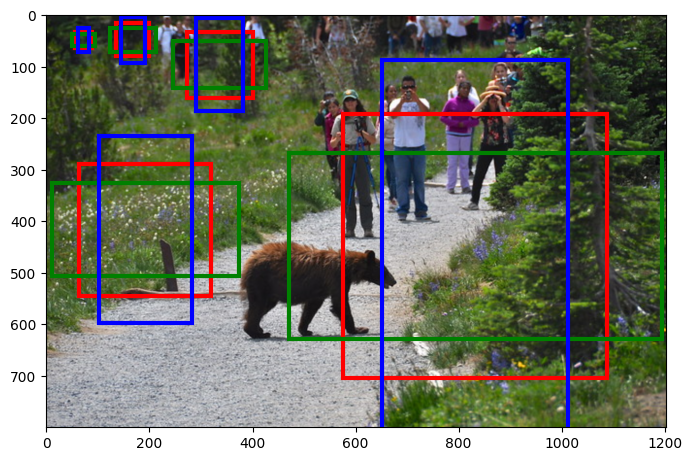
Jen pro lepší představu jsem nakreslil do obrázku velikosti kotev pro každou vrstvu jednu. Vždy je zobrazena trojice obdélníků pro jeden bod ve vrstvě s různými poměry stran. Nejmenší trojice platí pro vrstvu P2, a pokračuje to dále až po trojici největších obdélníků pro vrstvu P6.
Dříve než přistoupím ke generování návrhů pravděpodobných obdélníků s objekty, potřebuji poněkud změnit strukturu vstupních tensorů a dalších parametrů:
from detectron2.structures.image_list import ImageList
pred_objectness_logits_reshaped = [
# (N, A, Hi, Wi) -> (N, Hi, Wi, A) -> (N, Hi*Wi*A)
score.permute(0, 2, 3, 1).flatten(1)
for score in pred_objectness_logits
]
pred_anchor_deltas_reshaped = [
# (N, A*B, Hi, Wi) -> (N, A, B, Hi, Wi) -> (N, Hi, Wi, A, B) -> (N, Hi*Wi*A, B)
x.view(x.shape[0], -1, rpn.anchor_generator.box_dim, x.shape[-2], x.shape[-1])
.permute(0, 3, 4, 1, 2)
.flatten(1, -2)
for x in pred_anchor_deltas
]
image_list = ImageList.from_tensors([img])
Následujícím krokem vytvořím návrhy obdélníků, které budou výstupem RPN komponenty:
proposals = rpn.predict_proposals(anchors, pred_objectness_logits_reshaped, pred_anchor_deltas_reshaped, image_list.image_sizes)
proposal = proposals[0]
print(f"Type: {type(proposal)} Length: {len(proposal)}")
Type: <class 'detectron2.structures.instances.Instances'> Length: 1000
A co jsem to vlastně dostal v proměnné proposals? Jedná se o 1000 instancí návrhů obdélníků, ve kterých by se měl hledat a klasifikovat objekt.
Pokud se podívám poněkud hlouběji na proposals, pak obsahuje dvě sady atributů:
proposal.get_fields().keys()
Out[30]:
dict_keys(['proposal_boxes', 'objectness_logits'])
První sadou atributů jsou kýžené obdélníky:
proposal.get('proposal_boxes')
Out[31]:
Boxes(tensor([[2.4261e+02, 1.3814e+01, 2.8574e+02, 1.3351e+02],
[3.8566e+02, 4.4442e-01, 4.3168e+02, 7.3388e+01],
[2.1174e+02, 3.1352e+00, 2.5404e+02, 1.2908e+02],
...,
[5.9737e+02, 1.6910e+02, 7.9986e+02, 2.4745e+02],
[3.6904e+02, 4.1300e+02, 5.4700e+02, 6.7371e+02],
[6.6941e+02, 1.1006e+02, 1.1501e+03, 3.8892e+02]], device='cuda:0'))
Druhou sadou atributů jsou skóre, které každý vybraný obdélník obdržel v průběhu RPN Head:
torch.set_printoptions(threshold=100)
print(proposal.get('objectness_logits'))
torch.set_printoptions(profile="default")
tensor([11.2125, 10.2710, 9.6941, ..., -1.9790, -2.0036, -2.0121],
device='cuda:0')
A jak se k tomuto návrhu vlastně došlo? Základem postupu je algoritmus označovaný jako „Non-maximum Supression“. Na něj se v krátkosti ještě podívám.
Non-maximum Supression algoritmus
Celý postup by se dal shrnout do několika bodů:
-
Na všechny návrhy obdélníků v proměnné anchors byly aplikovány posuny a změny velikosti predikované v RPN Head jako pred_anchor_deltas.
-
Pro každou vrstvu jsou obdélníky seřazeny dle jejich skóre a následně je vybráno prvních 2000 návrhu. Počet vybraných návrhů pro každou vrstvu je stanoven v konfiguraci, parametr PRE_NMS_TOPK_TRAIN.
-
V předchozím kroku bylo vybráno 8 780 návrhů obdélníků ze všech vrstev (proč to není 5*2000? je to proto, že v poslední vrstvě P6 těch návrhů tolik není). Na všechny návrhy společně je aplikován algoritmus Non-maximum Supression, který vybere těch kýžených 1000 nejnadějnějších obdélníků.
Non-Maximum Suppression (NMS) je algoritmus používaný k odstranění redundantních detekcí při určování objektů na základě predikovaných bounding boxů. Pracuje tak, že seřadí všechny boxy podle jejich skóre a iterativně vybere box s nejvyšším skóre jako platnou detekci. Poté odstraní všechny ostatní boxy, které mají s vybraným boxem příliš vysoký překryv, měřený metrikou Intersection over Union (dáno parametrem v konfiguraci). Tento proces se opakuje, dokud nezůstávají žádné boxy s dostatečným skóre.
Celý postup je pěkně znázorněn následujícím diagramem od p. Hondy:

ROI Heads
Dostávám se k poslední komponentě tvořící základ Faster R-CNN modelu, a tou je tzv. ROI Heads.
Co mám na vstupu této komponenty:
-
vlastnosti specifikované v FPN. Jedná se o sadu vlastností v různých úrovních detailu označovaných P2 až P6. Vstupem do komponenty ROI Head jsou ale pouze vrstvy vlastností P2 až P5. P6 se z dalšího postupu vynechává.
-
návrhu obdélníků s nejpravděpodobnějším výskytem objektů (RoI) tak, jak byly vytvořeny komponentou RPN. Jedná se o návrh 1000 obdélníků včetně skóre vyjadřující pravděpodobnost výskytu objektu. Nicméně do dalšího zpracování postupuje pouze návrh obdélníků, jejich skóre je dále ignorováno.
Výsledkem činnosti komponenty by měla být predikce objektů na obrázku, jejich zařazení do třídy včetně vymezujícího obdélníku.
Takto zobrazuje komponentu p. Honda v zasazení do celého modelu:
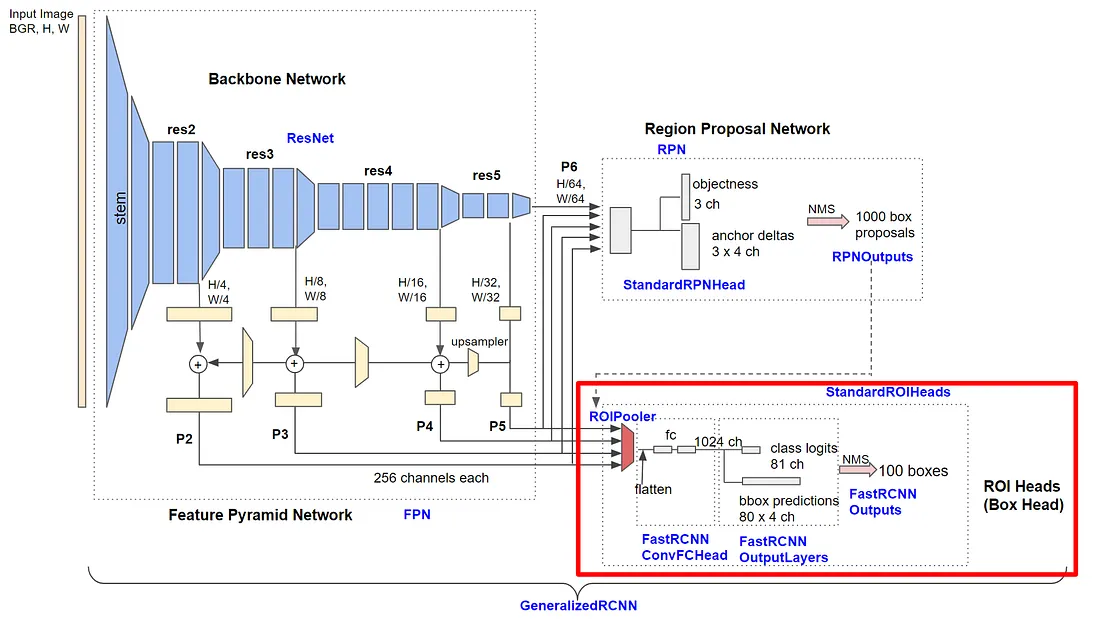
Na obrázku jsou vyznačeny tři hlavní části komponenty ROI Heads. První částí je tzv. „ROI Pooler“, jejímž úkolem je propojit návrhy RoI s vrstvami vlastností (jedná se o výpočetní část bez parametrů k učení). Další dvě části jsou již neuronové plně propojené vrstvy, které jsou určeny pro klasifikaci objektů do známých tříd a regrese ohraničujících obdélníků. Na všechny tři části se podívám blíže.
roi_heads = model.roi_heads
print(f"{type(roi_heads)}\n\n{roi_heads}")
<class 'detectron2.modeling.roi_heads.roi_heads.StandardROIHeads'>
StandardROIHeads(
(box_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(box_head): FastRCNNConvFCHead(
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=12544, out_features=1024, bias=True)
(fc_relu1): ReLU()
(fc2): Linear(in_features=1024, out_features=1024, bias=True)
(fc_relu2): ReLU()
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=1024, out_features=81, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=320, bias=True)
)
)
ROI Pooler
Aby bylo více zřejmé, o co v tomto bodě jde, zkusím ještě připomenout vstupy do komponenty.
Zaprvé je to pyramida vlastností tak, jak jí vytvořila komponenty FPN (s dovětkem, že poslední vrstvu P6 nebudu používat):
for p in roi_heads.box_in_features:
print(f"{p} : {features[p].shape}")
p2 : torch.Size([1, 256, 200, 304])
p3 : torch.Size([1, 256, 100, 152])
p4 : torch.Size([1, 256, 50, 76])
p5 : torch.Size([1, 256, 25, 38])
Ve vrstvách P2 až P5 mám pro jeden obrázek 256 vlastností s prostorovým rozlišením 200×304 až 25×38 bodů.
Zadruhé mám z komponenty RPN návrh obdélníků ROI, které s největší pravděpodobností obsahují nějaký známý objekt:
proposals[0].proposal_boxes.tensor.shape
Out[35]:
torch.Size([1000, 4])
A nyní bych potřeboval napasovat každý obdélník z návrhu na pyramidu vlastností tak, abych vybral jen jejich podmnožinu obdélníkem vymezenou. Navíc bych potřeboval, aby výstup měl vždy stejné dimenze bez ohledu na to, jak je obdélník velký. Tím vším se zabývá část ROI Pooler. V podstatě svůj úkol dělá ve dvou krocích.
V prvém kroku se nejdříve vybere z pyramidy vlastností ta vrstva, která nejlépe odpovídá ploše daného obdélníka.
Je na to docela komplikovaný vzoreček: floor(4 + log2(sqrt(box_area) / 224))
Nemá asi příliš cenu bádat nad jeho významem, můžu si použití vzorečku vyzkoušet rovnou v reálu (ve výpisu jsou vrstvy označeny indexem v poli, stále se jedná o P2 až P5):
from detectron2.modeling.poolers import assign_boxes_to_levels
for v, c in zip(*np.unique(assign_boxes_to_levels([x.proposal_boxes for x in proposals], 2, 5, 224, 4).cpu().numpy(), return_counts=True)):
print(f"Level: {v} Count: {c}")
Level: 0 Count: 757
Level: 1 Count: 169
Level: 2 Count: 47
Level: 3 Count: 27
Nyní již tedy vím, kterou vrstvu vlastností mám pro daný obdélník použít.
Dostávám se ke druhému kroku, a tím je výběr těch správných vlastností z dané vrstvy.
Proces začíná rozdělením každého ROI, definovaného jako bounding box, do pravidelné mřížky s předem definovaným počtem buněk (v mém případě je to konfiguračně 7×7). Poté algoritmus pro každou buňku provede operaci max-poolingu na odpovídající části feature mapy, což znamená, že vybere maximální hodnotu z každé podmnožiny pixelů. Tento postup zachovává dominantní aktivace a zajistí, že výsledná výstupní mapa má konzistentní velikost, nezávisle na původní velikosti ROI.
A takto vypadá výsledek:
roi_features = [features[f] for f in roi_heads.box_in_features] box_features = roi_heads.box_pooler(roi_features, [x.proposal_boxes for x in proposals]) print(box_features.shape) torch.Size([1000, 256, 7, 7])
Povšimněte si hned několika podstatných věcí:
-
mám stále těch svých 1000 návrhů obdélníků ROI
-
pro každý z obdélníků mám posbíráno 256 vlastností
-
všechny vlastnosti mám ve stejném rozlišení 7×7 bez ohledu na to, jak je obdélník velký
Box Head
V diagramu komponenty je tato část označena jako FastRCNNConvFCHead. Jedná se o dvě plně propojené vrstvy, kterým předchází ještě Flatten pro srovnání všech vlastností do jednoho vektoru. Obě plně propojené vrstvy mají 1024 vlastností doplněné o ReLU nelinearitu.
Na výsledek se můžeme podívat:
box_heads = roi_heads.box_head(box_features) print(box_heads.shape) torch.Size([1000, 1024])
Box Predictor
Označeno také jako FastRCNNOutputLayers. Jedná se o dvě plně propojené vrstvy. Ta první zajišťuje klasifikaci objektů do známých tříd, druhá pak dodává regresní parametry pro úpravu velikosti a polohy obdélníků ohraničujících jednotlivé objekty.
Takto to vypadá v reálu:
box_predictions = roi_heads.box_predictor(box_heads)
print(f"Type: {type(box_predictions)} Length:{len(box_predictions)}")
print(f" classification: {box_predictions[0].shape} min .. max: {box_predictions[0].min()} .. {box_predictions[0].max()}")
print(f" box regression: {box_predictions[1].shape}")
Type: <class 'tuple'> Length:2
classification: torch.Size([1000, 81]) min .. max: -5.91356086730957 .. 19.088598251342773
box regression: torch.Size([1000, 320])
Stále mám těch 1000 navržených obdélníků.
Na závěr se již jen provede několik dílčích kroků vedoucích k cílové predikci modelu:
-
na všechny obdélníky se aplikují odpovídající regresní parametry získané v předchozím kroku
-
dále se seřadí obdélníky dle jejich skóre a znovu se aplikuje algoritmus Non-maximum Supression, aby se potlačily ty obdélníky, které se významně překrývají
-
nakonec se vybere pouze K nejlepších obdélníků, kde K je definováno konfigurací (v mém případě je to max. 100)
A takto vypadá finální predikce:
roi_heads.box_predictor.inference(box_predictions, proposals)
Out[40]:
([Instances(num_instances=11, image_height=800, image_width=1203, fields=[pred_boxes: Boxes(tensor([[5.4823e+02, 1.4774e+02, 6.4247e+02, 4.3728e+02],
[3.7713e+02, 4.4092e+02, 6.7672e+02, 6.2996e+02],
[2.1135e+02, 2.7652e+00, 2.5463e+02, 1.3580e+02],
[6.6298e+02, 1.1755e+02, 7.4977e+02, 4.0352e+02],
[7.6090e+02, 1.1950e+02, 8.4227e+02, 3.4927e+02],
[8.0576e+02, 1.2647e+02, 9.0364e+02, 3.8218e+02],
[2.4244e+02, 1.4622e+01, 2.8585e+02, 1.3249e+02],
[3.8404e+02, 2.5559e-01, 4.2960e+02, 7.6243e+01],
[5.2123e+02, 1.5471e+02, 5.7399e+02, 3.2654e+02],
[6.3457e+02, 1.3125e+02, 6.8698e+02, 3.7638e+02],
[2.6042e+02, 2.9024e+00, 2.9517e+02, 1.2123e+02]], device='cuda:0',
grad_fn=<IndexBackward0>)), scores: tensor([0.9981, 0.9956, 0.9927, 0.9903, 0.9901, 0.9863, 0.9757, 0.9554, 0.9423,
0.9235, 0.7190], device='cuda:0', grad_fn=<IndexBackward0>), pred_classes: tensor([ 0, 21, 0, 0, 0, 0, 0, 0, 0, 0, 0], device='cuda:0')])],
[tensor([ 7, 6, 2, 8, 3, 181, 0, 26, 16, 12, 126],
device='cuda:0')])
Žádné názory
