Detectron2 – hra na špióny
V předchozích dvou článcích jsem z knihovny Detectron2 využíval modely trénované na konkrétní datové sadě, což byla v mém případě Common Objects in Context. To vám může postačovat v těch případech, kdy chcete vyhledávat objekty, které tato datová sada zná. Co když ale chci hledat něco, co v té datové sadě není? Můžu existující modely naučit „novým kouskům“? Na to se zkusím podívat dnes.
Tak jako dříve budu potřebovat dostat knihovnu Detectron2 do svého prostředí, tak jen rychle:
!git clone 'https://github.com/facebookresearch/detectron2' import sys, os, distutils.core dist = distutils.core.run_setup("./detectron2/setup.py") !python -m pip install {' '.join([f"'{x}'" for x in dist.install_requires])} sys.path.insert(0, os.path.abspath('./detectron2')) import torch, detectron2 !nvcc --version TORCH_VERSION = ".".join(torch.__version__.split(".")[:2]) CUDA_VERSION = torch.__version__.split("+")[-1] print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION) print("detectron2:", detectron2.__version__) nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2023 NVIDIA Corporation Built on Wed_Nov_22_10:17:15_PST_2023 Cuda compilation tools, release 12.3, V12.3.107 Build cuda_12.3.r12.3/compiler.33567101_0 torch: 2.4 ; cuda: 2.4.0 detectron2: 0.6
Datová sada – Satellite Small Objects Computer Vision Project
Pro dnešní pokusy jsem si vybral datovou sadu Satellite Small Objects Computer Vision Project. Jedná se o sadu leteckých snímků s lokalizovanými objekty jako jsou auta, nákladní vozy, letadla, lodě a podobně. Níže je uvedeno několik příkladů, takže si můžete udělat představu, co v těch obrázcích asi je.
Tuto datovou sadu jsem si vybral také proto, že jí autoři poskytují také ve formátu COCO JSON. To mně výrazně ušetří práci, neboť takovou sadu mohu jednoduše zaregistrovat v knihovně Detectron2 a rovnou s ní pracovat. Pokud bych takto formátovanou a anotovanou datovou sadu neměl, pak bych si musel napsat vlastní funkci podle návodu Use Custom Datasets.
Nejdříve několik potřebných závislostí:
import detectron2 from detectron2.utils.logger import setup_logger setup_logger() import numpy as np import cv2 import matplotlib.pyplot as plt from detectron2 import model_zoo from detectron2.engine import DefaultPredictor from detectron2.config import get_cfg from detectron2.utils.visualizer import Visualizer from detectron2.data import MetadataCatalog, DatasetCatalog
Takto vypadá cesta k mé datové sadě:
DATASET_BASE = '/kaggle/input/satellite-small-objects-dataset-coco-json-format'
Díky tomu, že mám datovou sadu v COCO JSON formátu, mohu jí rovnou zaregistrovat pod názvem ‚satellite_train‘, ‚satellite_valid‘ a ‚satellite_test‘:
detectron2.data.datasets.register_coco_instances('satellite_train', {}, os.path.join(DATASET_BASE, 'train', '_annotations.coco.json'), os.path.join(DATASET_BASE, 'train'))
detectron2.data.datasets.register_coco_instances('satellite_valid', {}, os.path.join(DATASET_BASE, 'valid', '_annotations.coco.json'), os.path.join(DATASET_BASE, 'valid'))
detectron2.data.datasets.register_coco_instances('satellite_test', {}, os.path.join(DATASET_BASE, 'test', '_annotations.coco.json'), os.path.join(DATASET_BASE, 'test'))
Jak jsem slíbil dříve, zde je ukázka několika obrázků společně s jejich anotací (v tomto případě z datové množiny určené pro trénování):
import random metadata = detectron2.data.MetadataCatalog.get('satellite_train') dataset = detectron2.data.DatasetCatalog.get('satellite_train') rows, cols = 2, 2 for row in range(rows): fig=plt.figure(figsize=(16, 8)) for i, d in enumerate(random.sample(dataset, cols), start=1): fig.add_subplot(1, cols, i) image = cv2.imread(d['file_name']) visualizer = Visualizer(image, metadata, scale=1.0) out = visualizer.draw_dataset_dict(d) plt.imshow(out.get_image()[:,:,::-1]) plt.show() WARNING [10/28 15:38:29 d2.data.datasets.coco]: Category ids in annotations are not in [1, #categories]! We'll apply a mapping for you. [10/28 15:38:29 d2.data.datasets.coco]: Loaded 4414 images in COCO format from /kaggle/input/satellite-small-objects-dataset-coco-json-format/train/_annotations.coco.json


cfg = get_cfg() cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml")) cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml") cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 cfg.MODEL.ANCHOR_GENERATOR.SIZES = [[8, 16, 32, 64, 128]] cfg.MODEL.ANCHOR_GENERATOR.ASPECT_RATIOS = [[0.25, 0.5, 1.0, 2.0]] cfg.MODEL.RPN.IN_FEATURES = ['p2', 'p3', 'p4', 'p5', 'p6'] cfg.INPUT.MIN_SIZE_TRAIN = 0 cfg.INPUT.MAX_SIZE_TRAIN = 99999 cfg.INPUT.RANDOM_FLIP = "horizontal" cfg.DATASETS.TRAIN = ("satellite_train",) cfg.DATASETS.TEST = ("satellite_valid",) cfg.DATALOADER.NUM_WORKERS = 2 cfg.SOLVER.IMS_PER_BATCH = 2 cfg.SOLVER.BASE_LR = 0.00125 cfg.SOLVER.MAX_ITER = 1000 os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
Takže v tomto okamžiku již konfigurační objekt mám. Na jeho základě musím vytvořit objekt DefaultTrainer a s jeho pomocí spustit proces trénování:
from detectron2.engine import DefaultTrainer trainer = DefaultTrainer(cfg) trainer.resume_or_load(resume=False) trainer.train() [10/28 15:38:33 d2.engine.defaults]: Model: GeneralizedRCNN( (backbone): FPN( (fpn_lateral2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1)) (fpn_output2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1)) (fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1)) (fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1)) (fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (top_block): LastLevelMaxPool() (bottom_up): ResNet( (stem): BasicStem( (conv1): Conv2d( 3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) ) (res2): Sequential( (0): BottleneckBlock( (shortcut): Conv2d( 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv1): Conv2d( 64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) (conv2): Conv2d( 64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) (conv3): Conv2d( 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) ) (1): BottleneckBlock( (conv1): Conv2d( 256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) (conv2): Conv2d( 64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) (conv3): Conv2d( 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) ) (2): BottleneckBlock( (conv1): Conv2d( 256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) (conv2): Conv2d( 64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=64, eps=1e-05) ) (conv3): Conv2d( 64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) ) ) (res3): Sequential( (0): BottleneckBlock( (shortcut): Conv2d( 256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv1): Conv2d( 256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv2): Conv2d( 128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv3): Conv2d( 128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) ) (1): BottleneckBlock( (conv1): Conv2d( 512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv2): Conv2d( 128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv3): Conv2d( 128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) ) (2): BottleneckBlock( (conv1): Conv2d( 512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv2): Conv2d( 128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv3): Conv2d( 128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) ) (3): BottleneckBlock( (conv1): Conv2d( 512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv2): Conv2d( 128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=128, eps=1e-05) ) (conv3): Conv2d( 128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) ) ) (res4): Sequential( (0): BottleneckBlock( (shortcut): Conv2d( 512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) (conv1): Conv2d( 512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (1): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (2): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (3): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (4): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (5): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (6): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (7): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (8): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (9): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (10): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (11): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (12): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (13): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (14): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (15): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (16): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (17): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (18): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (19): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (20): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (21): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) (22): BottleneckBlock( (conv1): Conv2d( 1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv2): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=256, eps=1e-05) ) (conv3): Conv2d( 256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05) ) ) ) (res5): Sequential( (0): BottleneckBlock( (shortcut): Conv2d( 1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False (norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05) ) (conv1): Conv2d( 1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv2): Conv2d( 512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv3): Conv2d( 512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05) ) ) (1): BottleneckBlock( (conv1): Conv2d( 2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv2): Conv2d( 512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv3): Conv2d( 512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05) ) ) (2): BottleneckBlock( (conv1): Conv2d( 2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv2): Conv2d( 512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05) ) (conv3): Conv2d( 512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False (norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05) ) ) ) ) ) (proposal_generator): RPN( (rpn_head): StandardRPNHead( (conv): Conv2d( 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1) (activation): ReLU() ) (objectness_logits): Conv2d(256, 20, kernel_size=(1, 1), stride=(1, 1)) (anchor_deltas): Conv2d(256, 80, kernel_size=(1, 1), stride=(1, 1)) ) (anchor_generator): DefaultAnchorGenerator( (cell_anchors): BufferList() ) ) (roi_heads): StandardROIHeads( (box_pooler): ROIPooler( (level_poolers): ModuleList( (0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=0, aligned=True) (1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, aligned=True) (2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, aligned=True) (3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, aligned=True) ) ) (box_head): FastRCNNConvFCHead( (flatten): Flatten(start_dim=1, end_dim=-1) (fc1): Linear(in_features=12544, out_features=1024, bias=True) (fc_relu1): ReLU() (fc2): Linear(in_features=1024, out_features=1024, bias=True) (fc_relu2): ReLU() ) (box_predictor): FastRCNNOutputLayers( (cls_score): Linear(in_features=1024, out_features=81, bias=True) (bbox_pred): Linear(in_features=1024, out_features=320, bias=True) ) ) ) WARNING [10/28 15:38:33 d2.data.datasets.coco]: Category ids in annotations are not in [1, #categories]! We'll apply a mapping for you. [10/28 15:38:33 d2.data.datasets.coco]: Loaded 4414 images in COCO format from /kaggle/input/satellite-small-objects-dataset-coco-json-format/train/_annotations.coco.json [10/28 15:38:34 d2.data.build]: Removed 3 images with no usable annotations. 4411 images left. [10/28 15:38:34 d2.data.build]: Distribution of instances among all 12 categories: | category | #instances | category | #instances | category | #instances | |:-------------:|:-------------|:----------:|:-------------|:-------------:|:-------------| | car-plane-b.. | 0 | airplane | 2207 | boat | 7043 | | car | 19151 | cargo ship | 396 | fighter jet | 2090 | | helicopter | 1559 | jet | 2788 | military ai.. | 684 | | propeller p.. | 2616 | truck | 6271 | yacht | 468 | | | | | | | | | total | 45273 | | | | | [10/28 15:38:34 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in training: [ResizeShortestEdge(short_edge_length=(0, 0), max_size=99999, sample_style='choice'), RandomFlip()] [10/28 15:38:34 d2.data.build]: Using training sampler TrainingSampler [10/28 15:38:34 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'> [10/28 15:38:34 d2.data.common]: Serializing 4411 elements to byte tensors and concatenating them all ... [10/28 15:38:34 d2.data.common]: Serialized dataset takes 2.64 MiB [10/28 15:38:34 d2.data.build]: Making batched data loader with batch_size=2 WARNING [10/28 15:38:34 d2.solver.build]: SOLVER.STEPS contains values larger than SOLVER.MAX_ITER. These values will be ignored. [10/28 15:38:34 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_FPN_3x/137851257/model_final_f6e8b1.pkl ... model_final_f6e8b1.pkl: 243MB [00:02, 105MB/s] [10/28 15:38:36 d2.engine.train_loop]: Starting training from iteration 0 /opt/conda/lib/python3.10/site-packages/torch/functional.py:513: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /usr/local/src/pytorch/aten/src/ATen/native/TensorShape.cpp:3609.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] [10/28 15:38:43 d2.utils.events]: eta: 0:02:37 iter: 19 total_loss: 1.825 loss_cls: 0.7122 loss_box_reg: 0.09764 loss_rpn_cls: 0.6996 loss_rpn_loc: 0.2088 time: 0.1660 last_time: 0.1597 data_time: 0.0112 last_data_time: 0.0050 lr: 2.4976e-05 max_mem: 1866M [10/28 15:38:59 d2.utils.events]: eta: 0:02:37 iter: 39 total_loss: 1.721 loss_cls: 0.7451 loss_box_reg: 0.1015 loss_rpn_cls: 0.6872 loss_rpn_loc: 0.1941 time: 0.1669 last_time: 0.1666 data_time: 0.0058 last_data_time: 0.0056 lr: 4.9951e-05 max_mem: 1866M [10/28 15:39:03 d2.utils.events]: eta: 0:02:32 iter: 59 total_loss: 1.472 loss_cls: 0.5056 loss_box_reg: 0.09716 loss_rpn_cls: 0.6772 loss_rpn_loc: 0.2121 time: 0.1654 last_time: 0.1566 data_time: 0.0058 last_data_time: 0.0054 lr: 7.4926e-05 max_mem: 1866M [10/28 15:39:06 d2.utils.events]: eta: 0:02:28 iter: 79 total_loss: 1.204 loss_cls: 0.3156 loss_box_reg: 0.0735 loss_rpn_cls: 0.6643 loss_rpn_loc: 0.1577 time: 0.1642 last_time: 0.1593 data_time: 0.0058 last_data_time: 0.0055 lr: 9.9901e-05 max_mem: 1925M [10/28 15:39:09 d2.utils.events]: eta: 0:02:24 iter: 99 total_loss: 1.254 loss_cls: 0.2477 loss_box_reg: 0.06834 loss_rpn_cls: 0.6454 loss_rpn_loc: 0.1483 time: 0.1634 last_time: 0.1634 data_time: 0.0056 last_data_time: 0.0058 lr: 0.00012488 max_mem: 1925M [10/28 15:39:12 d2.utils.events]: eta: 0:02:21 iter: 119 total_loss: 1.106 loss_cls: 0.2737 loss_box_reg: 0.05979 loss_rpn_cls: 0.6255 loss_rpn_loc: 0.1491 time: 0.1631 last_time: 0.1580 data_time: 0.0057 last_data_time: 0.0050 lr: 0.00014985 max_mem: 1925M [10/28 15:39:16 d2.utils.events]: eta: 0:02:18 iter: 139 total_loss: 1.153 loss_cls: 0.2629 loss_box_reg: 0.0927 loss_rpn_cls: 0.5686 loss_rpn_loc: 0.1345 time: 0.1628 last_time: 0.1574 data_time: 0.0051 last_data_time: 0.0044 lr: 0.00017483 max_mem: 1925M [10/28 15:39:19 d2.utils.events]: eta: 0:02:15 iter: 159 total_loss: 1.251 loss_cls: 0.388 loss_box_reg: 0.1793 loss_rpn_cls: 0.5367 loss_rpn_loc: 0.1631 time: 0.1628 last_time: 0.1673 data_time: 0.0053 last_data_time: 0.0046 lr: 0.0001998 max_mem: 1956M [10/28 15:39:22 d2.utils.events]: eta: 0:02:12 iter: 179 total_loss: 1.502 loss_cls: 0.5512 loss_box_reg: 0.31 loss_rpn_cls: 0.4673 loss_rpn_loc: 0.1734 time: 0.1628 last_time: 0.1609 data_time: 0.0049 last_data_time: 0.0049 lr: 0.00022478 max_mem: 2086M [10/28 15:39:25 d2.utils.events]: eta: 0:02:08 iter: 199 total_loss: 1.605 loss_cls: 0.6488 loss_box_reg: 0.355 loss_rpn_cls: 0.3793 loss_rpn_loc: 0.1327 time: 0.1626 last_time: 0.1589 data_time: 0.0050 last_data_time: 0.0046 lr: 0.00024975 max_mem: 2086M [10/28 15:39:29 d2.utils.events]: eta: 0:02:05 iter: 219 total_loss: 1.531 loss_cls: 0.643 loss_box_reg: 0.3996 loss_rpn_cls: 0.3507 loss_rpn_loc: 0.1723 time: 0.1625 last_time: 0.1636 data_time: 0.0053 last_data_time: 0.0055 lr: 0.00027473 max_mem: 2086M [10/28 15:39:32 d2.utils.events]: eta: 0:02:02 iter: 239 total_loss: 1.6 loss_cls: 0.5032 loss_box_reg: 0.3765 loss_rpn_cls: 0.2588 loss_rpn_loc: 0.1068 time: 0.1627 last_time: 0.1607 data_time: 0.0053 last_data_time: 0.0045 lr: 0.0002997 max_mem: 2086M [10/28 15:39:35 d2.utils.events]: eta: 0:01:59 iter: 259 total_loss: 1.322 loss_cls: 0.5066 loss_box_reg: 0.3371 loss_rpn_cls: 0.2791 loss_rpn_loc: 0.1465 time: 0.1625 last_time: 0.1600 data_time: 0.0049 last_data_time: 0.0047 lr: 0.00032468 max_mem: 2086M [10/28 15:39:38 d2.utils.events]: eta: 0:01:55 iter: 279 total_loss: 1.115 loss_cls: 0.4296 loss_box_reg: 0.3921 loss_rpn_cls: 0.2088 loss_rpn_loc: 0.07798 time: 0.1623 last_time: 0.1560 data_time: 0.0049 last_data_time: 0.0047 lr: 0.00034965 max_mem: 2086M [10/28 15:39:42 d2.utils.events]: eta: 0:01:52 iter: 299 total_loss: 1.451 loss_cls: 0.4969 loss_box_reg: 0.4802 loss_rpn_cls: 0.2417 loss_rpn_loc: 0.1484 time: 0.1622 last_time: 0.1589 data_time: 0.0051 last_data_time: 0.0047 lr: 0.00037463 max_mem: 2086M [10/28 15:39:45 d2.utils.events]: eta: 0:01:49 iter: 319 total_loss: 1.529 loss_cls: 0.6149 loss_box_reg: 0.4817 loss_rpn_cls: 0.2397 loss_rpn_loc: 0.1353 time: 0.1622 last_time: 0.1617 data_time: 0.0053 last_data_time: 0.0061 lr: 0.0003996 max_mem: 2086M [10/28 15:39:48 d2.utils.events]: eta: 0:01:46 iter: 339 total_loss: 1.314 loss_cls: 0.5094 loss_box_reg: 0.3127 loss_rpn_cls: 0.2408 loss_rpn_loc: 0.1668 time: 0.1622 last_time: 0.1646 data_time: 0.0054 last_data_time: 0.0056 lr: 0.00042458 max_mem: 2086M [10/28 15:39:51 d2.utils.events]: eta: 0:01:42 iter: 359 total_loss: 1.264 loss_cls: 0.4988 loss_box_reg: 0.4391 loss_rpn_cls: 0.212 loss_rpn_loc: 0.1118 time: 0.1622 last_time: 0.1619 data_time: 0.0054 last_data_time: 0.0054 lr: 0.00044955 max_mem: 2086M [10/28 15:39:55 d2.utils.events]: eta: 0:01:39 iter: 379 total_loss: 1.273 loss_cls: 0.4243 loss_box_reg: 0.4456 loss_rpn_cls: 0.1561 loss_rpn_loc: 0.1081 time: 0.1622 last_time: 0.1565 data_time: 0.0052 last_data_time: 0.0050 lr: 0.00047453 max_mem: 2086M [10/28 15:39:58 d2.utils.events]: eta: 0:01:36 iter: 399 total_loss: 1.378 loss_cls: 0.5405 loss_box_reg: 0.4047 loss_rpn_cls: 0.1609 loss_rpn_loc: 0.1498 time: 0.1621 last_time: 0.1574 data_time: 0.0051 last_data_time: 0.0046 lr: 0.0004995 max_mem: 2086M [10/28 15:40:01 d2.utils.events]: eta: 0:01:33 iter: 419 total_loss: 1.282 loss_cls: 0.526 loss_box_reg: 0.424 loss_rpn_cls: 0.196 loss_rpn_loc: 0.1336 time: 0.1623 last_time: 0.1944 data_time: 0.0057 last_data_time: 0.0060 lr: 0.00052448 max_mem: 2086M [10/28 15:40:04 d2.utils.events]: eta: 0:01:30 iter: 439 total_loss: 1.035 loss_cls: 0.3585 loss_box_reg: 0.4496 loss_rpn_cls: 0.1151 loss_rpn_loc: 0.09004 time: 0.1624 last_time: 0.1592 data_time: 0.0054 last_data_time: 0.0046 lr: 0.00054945 max_mem: 2086M [10/28 15:40:08 d2.utils.events]: eta: 0:01:26 iter: 459 total_loss: 1.464 loss_cls: 0.5679 loss_box_reg: 0.5142 loss_rpn_cls: 0.1452 loss_rpn_loc: 0.1443 time: 0.1623 last_time: 0.1730 data_time: 0.0051 last_data_time: 0.0052 lr: 0.00057443 max_mem: 2086M [10/28 15:40:11 d2.utils.events]: eta: 0:01:23 iter: 479 total_loss: 1.309 loss_cls: 0.4826 loss_box_reg: 0.4617 loss_rpn_cls: 0.1588 loss_rpn_loc: 0.1444 time: 0.1623 last_time: 0.1648 data_time: 0.0056 last_data_time: 0.0056 lr: 0.0005994 max_mem: 2086M [10/28 15:40:14 d2.utils.events]: eta: 0:01:20 iter: 499 total_loss: 1.148 loss_cls: 0.4078 loss_box_reg: 0.4352 loss_rpn_cls: 0.1354 loss_rpn_loc: 0.1462 time: 0.1623 last_time: 0.1558 data_time: 0.0054 last_data_time: 0.0047 lr: 0.00062438 max_mem: 2123M [10/28 15:40:17 d2.utils.events]: eta: 0:01:17 iter: 519 total_loss: 1.164 loss_cls: 0.4361 loss_box_reg: 0.4807 loss_rpn_cls: 0.1038 loss_rpn_loc: 0.1119 time: 0.1622 last_time: 0.1608 data_time: 0.0052 last_data_time: 0.0049 lr: 0.00064935 max_mem: 2123M [10/28 15:40:21 d2.utils.events]: eta: 0:01:13 iter: 539 total_loss: 1.286 loss_cls: 0.418 loss_box_reg: 0.566 loss_rpn_cls: 0.1381 loss_rpn_loc: 0.1263 time: 0.1621 last_time: 0.1613 data_time: 0.0050 last_data_time: 0.0056 lr: 0.00067433 max_mem: 2123M [10/28 15:40:24 d2.utils.events]: eta: 0:01:10 iter: 559 total_loss: 1.287 loss_cls: 0.4525 loss_box_reg: 0.5101 loss_rpn_cls: 0.1441 loss_rpn_loc: 0.1599 time: 0.1622 last_time: 0.1578 data_time: 0.0056 last_data_time: 0.0055 lr: 0.0006993 max_mem: 2123M [10/28 15:40:27 d2.utils.events]: eta: 0:01:07 iter: 579 total_loss: 1.219 loss_cls: 0.4701 loss_box_reg: 0.4964 loss_rpn_cls: 0.1535 loss_rpn_loc: 0.1094 time: 0.1622 last_time: 0.1700 data_time: 0.0054 last_data_time: 0.0056 lr: 0.00072428 max_mem: 2123M [10/28 15:40:30 d2.utils.events]: eta: 0:01:04 iter: 599 total_loss: 1.412 loss_cls: 0.4726 loss_box_reg: 0.4421 loss_rpn_cls: 0.1535 loss_rpn_loc: 0.16 time: 0.1622 last_time: 0.1614 data_time: 0.0055 last_data_time: 0.0053 lr: 0.00074925 max_mem: 2123M [10/28 15:40:34 d2.utils.events]: eta: 0:01:01 iter: 619 total_loss: 1.179 loss_cls: 0.4391 loss_box_reg: 0.4381 loss_rpn_cls: 0.1475 loss_rpn_loc: 0.1388 time: 0.1624 last_time: 0.1759 data_time: 0.0062 last_data_time: 0.0072 lr: 0.00077423 max_mem: 2123M [10/28 15:40:37 d2.utils.events]: eta: 0:00:57 iter: 639 total_loss: 1.246 loss_cls: 0.5142 loss_box_reg: 0.4569 loss_rpn_cls: 0.146 loss_rpn_loc: 0.1369 time: 0.1624 last_time: 0.1584 data_time: 0.0053 last_data_time: 0.0054 lr: 0.0007992 max_mem: 2123M [10/28 15:40:40 d2.utils.events]: eta: 0:00:54 iter: 659 total_loss: 1.251 loss_cls: 0.4604 loss_box_reg: 0.4832 loss_rpn_cls: 0.1025 loss_rpn_loc: 0.09686 time: 0.1623 last_time: 0.1597 data_time: 0.0053 last_data_time: 0.0053 lr: 0.00082418 max_mem: 2123M [10/28 15:40:44 d2.utils.events]: eta: 0:00:51 iter: 679 total_loss: 1.446 loss_cls: 0.5317 loss_box_reg: 0.5111 loss_rpn_cls: 0.1562 loss_rpn_loc: 0.1607 time: 0.1623 last_time: 0.1577 data_time: 0.0052 last_data_time: 0.0049 lr: 0.00084915 max_mem: 2123M [10/28 15:40:47 d2.utils.events]: eta: 0:00:48 iter: 699 total_loss: 1.299 loss_cls: 0.4848 loss_box_reg: 0.5071 loss_rpn_cls: 0.1127 loss_rpn_loc: 0.1603 time: 0.1623 last_time: 0.1588 data_time: 0.0050 last_data_time: 0.0052 lr: 0.00087413 max_mem: 2123M [10/28 15:40:50 d2.utils.events]: eta: 0:00:45 iter: 719 total_loss: 1.192 loss_cls: 0.493 loss_box_reg: 0.4684 loss_rpn_cls: 0.1286 loss_rpn_loc: 0.172 time: 0.1622 last_time: 0.1589 data_time: 0.0052 last_data_time: 0.0055 lr: 0.0008991 max_mem: 2123M [10/28 15:40:53 d2.utils.events]: eta: 0:00:41 iter: 739 total_loss: 1.123 loss_cls: 0.4149 loss_box_reg: 0.4803 loss_rpn_cls: 0.1217 loss_rpn_loc: 0.1482 time: 0.1622 last_time: 0.1583 data_time: 0.0053 last_data_time: 0.0059 lr: 0.00092408 max_mem: 2123M [10/28 15:40:56 d2.utils.events]: eta: 0:00:38 iter: 759 total_loss: 1.068 loss_cls: 0.3793 loss_box_reg: 0.4372 loss_rpn_cls: 0.1 loss_rpn_loc: 0.1231 time: 0.1621 last_time: 0.1550 data_time: 0.0055 last_data_time: 0.0044 lr: 0.00094905 max_mem: 2123M [10/28 15:41:00 d2.utils.events]: eta: 0:00:35 iter: 779 total_loss: 1.191 loss_cls: 0.3968 loss_box_reg: 0.4612 loss_rpn_cls: 0.1292 loss_rpn_loc: 0.1381 time: 0.1620 last_time: 0.1595 data_time: 0.0048 last_data_time: 0.0047 lr: 0.00097403 max_mem: 2123M [10/28 15:41:03 d2.utils.events]: eta: 0:00:32 iter: 799 total_loss: 1.227 loss_cls: 0.4524 loss_box_reg: 0.4939 loss_rpn_cls: 0.1087 loss_rpn_loc: 0.1238 time: 0.1620 last_time: 0.1556 data_time: 0.0055 last_data_time: 0.0051 lr: 0.000999 max_mem: 2123M [10/28 15:41:06 d2.utils.events]: eta: 0:00:28 iter: 819 total_loss: 1.228 loss_cls: 0.4673 loss_box_reg: 0.503 loss_rpn_cls: 0.09038 loss_rpn_loc: 0.1221 time: 0.1620 last_time: 0.1580 data_time: 0.0060 last_data_time: 0.0052 lr: 0.001024 max_mem: 2123M [10/28 15:41:09 d2.utils.events]: eta: 0:00:25 iter: 839 total_loss: 1.257 loss_cls: 0.4763 loss_box_reg: 0.5219 loss_rpn_cls: 0.1317 loss_rpn_loc: 0.1374 time: 0.1620 last_time: 0.1568 data_time: 0.0053 last_data_time: 0.0060 lr: 0.001049 max_mem: 2123M [10/28 15:41:13 d2.utils.events]: eta: 0:00:22 iter: 859 total_loss: 1.251 loss_cls: 0.4692 loss_box_reg: 0.4617 loss_rpn_cls: 0.09215 loss_rpn_loc: 0.1187 time: 0.1620 last_time: 0.1581 data_time: 0.0047 last_data_time: 0.0047 lr: 0.0010739 max_mem: 2123M [10/28 15:41:16 d2.utils.events]: eta: 0:00:19 iter: 879 total_loss: 1.212 loss_cls: 0.4833 loss_box_reg: 0.4908 loss_rpn_cls: 0.09467 loss_rpn_loc: 0.1313 time: 0.1619 last_time: 0.1583 data_time: 0.0050 last_data_time: 0.0048 lr: 0.0010989 max_mem: 2125M [10/28 15:41:19 d2.utils.events]: eta: 0:00:16 iter: 899 total_loss: 1.213 loss_cls: 0.4254 loss_box_reg: 0.4659 loss_rpn_cls: 0.09542 loss_rpn_loc: 0.107 time: 0.1619 last_time: 0.1677 data_time: 0.0050 last_data_time: 0.0060 lr: 0.0011239 max_mem: 2125M [10/28 15:41:22 d2.utils.events]: eta: 0:00:12 iter: 919 total_loss: 1.105 loss_cls: 0.3572 loss_box_reg: 0.4378 loss_rpn_cls: 0.07979 loss_rpn_loc: 0.1088 time: 0.1619 last_time: 0.1618 data_time: 0.0052 last_data_time: 0.0045 lr: 0.0011489 max_mem: 2125M [10/28 15:41:26 d2.utils.events]: eta: 0:00:09 iter: 939 total_loss: 1.282 loss_cls: 0.4933 loss_box_reg: 0.5322 loss_rpn_cls: 0.1185 loss_rpn_loc: 0.1234 time: 0.1619 last_time: 0.1608 data_time: 0.0051 last_data_time: 0.0045 lr: 0.0011738 max_mem: 2125M [10/28 15:41:29 d2.utils.events]: eta: 0:00:06 iter: 959 total_loss: 1.159 loss_cls: 0.4409 loss_box_reg: 0.5294 loss_rpn_cls: 0.08599 loss_rpn_loc: 0.1322 time: 0.1619 last_time: 0.1596 data_time: 0.0049 last_data_time: 0.0046 lr: 0.0011988 max_mem: 2125M [10/28 15:41:32 d2.utils.events]: eta: 0:00:03 iter: 979 total_loss: 1.227 loss_cls: 0.4864 loss_box_reg: 0.5101 loss_rpn_cls: 0.07952 loss_rpn_loc: 0.1065 time: 0.1619 last_time: 0.1614 data_time: 0.0058 last_data_time: 0.0060 lr: 0.0012238 max_mem: 2125M [10/28 15:41:36 d2.utils.events]: eta: 0:00:00 iter: 999 total_loss: 1.234 loss_cls: 0.4387 loss_box_reg: 0.5025 loss_rpn_cls: 0.09562 loss_rpn_loc: 0.1306 time: 0.1619 last_time: 0.1593 data_time: 0.0055 last_data_time: 0.0054 lr: 0.0012488 max_mem: 2125M [10/28 15:41:36 d2.engine.hooks]: Overall training speed: 998 iterations in 0:02:41 (0.1619 s / it) [10/28 15:41:36 d2.engine.hooks]: Total training time: 0:02:56 (0:00:14 on hooks) WARNING [10/28 15:41:36 d2.data.datasets.coco]: Category ids in annotations are not in [1, #categories]! We'll apply a mapping for you. [10/28 15:41:36 d2.data.datasets.coco]: Loaded 420 images in COCO format from /kaggle/input/satellite-small-objects-dataset-coco-json-format/valid/_annotations.coco.json [10/28 15:41:36 d2.data.build]: Distribution of instances among all 12 categories: | category | #instances | category | #instances | category | #instances | |:-------------:|:-------------|:----------:|:-------------|:-------------:|:-------------| | car-plane-b.. | 0 | airplane | 176 | boat | 719 | | car | 1731 | cargo ship | 46 | fighter jet | 242 | | helicopter | 125 | jet | 198 | military ai.. | 82 | | propeller p.. | 129 | truck | 545 | yacht | 31 | | | | | | | | | total | 4024 | | | | | [10/28 15:41:36 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in inference: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')] [10/28 15:41:36 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'> [10/28 15:41:36 d2.data.common]: Serializing 420 elements to byte tensors and concatenating them all ... [10/28 15:41:36 d2.data.common]: Serialized dataset takes 0.26 MiB WARNING [10/28 15:41:36 d2.engine.defaults]: No evaluator found. Use `DefaultTrainer.test(evaluators=)`, or implement its `build_evaluator` method.
Na trénování jsem měl vyhrazeno 1000 iterací. Výsledkem je model zapsaný do souboru model_final.pth.
Ověření výsledků modelu
A nyní se zkusím podívat, jak jsem byl při trénování modelu úspěšný.
Pro predikci na testovací sadě budu potřebovat vytvořit objekt DefaultPredictor. Na jeho vytvoření potřebuji konfiguraci. Tu ale již mám, vytvořil jsem si jí předtím, než jsem začal s trénováním. Pouze potřebuji nastavit nové váhy modelu, proto ta změna parametru cfg.MODEL.WEIGHTS.
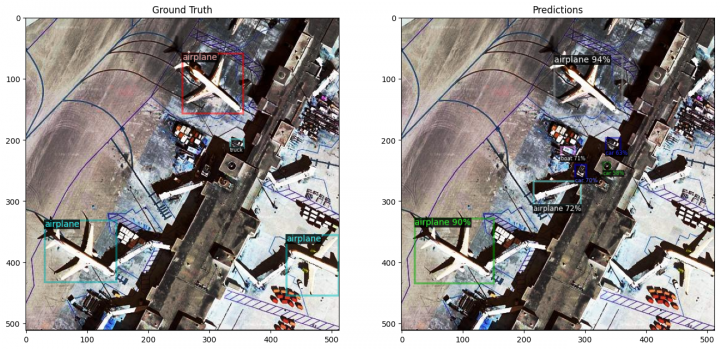
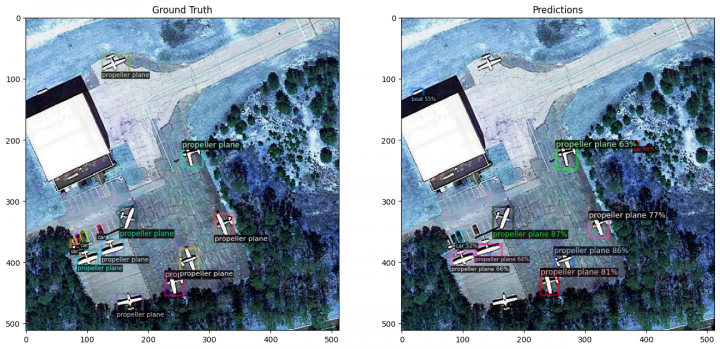
Dále si z testovací sady vyberu náhodně několik vzorků – satelitních obrázků. Každý takový satelitní obrázek si zobrazím dvakrát vedle sebe. Na levé straně je snímek včetně anotací definovaných v datové sadě (tedy to je dle autorů datové sady pravda). Na pravé straně je pak tento snímek s anotacemi predikovanými modelem (to je tedy to, co vidí můj model).
A zde je výsledek:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") predictor = DefaultPredictor(cfg) metadata = detectron2.data.MetadataCatalog.get('satellite_test') dataset = detectron2.data.DatasetCatalog.get('satellite_test') for sample in random.sample(dataset, 5): image = cv2.imread(sample["file_name"]) outputs = predictor(image) v_gt = Visualizer(image, metadata=metadata, scale=1.0) gt_vis = v_gt.draw_dataset_dict(sample) v_pred = Visualizer(image, metadata=metadata, scale=1.0) pred_vis = v_pred.draw_instance_predictions(outputs["instances"].to("cpu")) plt.figure(figsize=(16, 8)) plt.subplot(1, 2, 1) plt.imshow(gt_vis.get_image()[:,:,::-1]) plt.title("Ground Truth") plt.subplot(1, 2, 2) plt.imshow(pred_vis.get_image()[:,:,::-1]) plt.title("Predictions") plt.show() [10/28 15:41:37 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from ./output/model_final.pth ... Category ids in annotations are not in [1, #categories]! We'll apply a mapping for you. [10/28 15:41:38 d2.data.datasets.coco]: Loaded 208 images in COCO format from /kaggle/input/satellite-small-objects-dataset-coco-json-format/test/_annotations.coco.json

























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU