Apify: taháme data z webu (aneb jak na kalendář ČLK)
Znáte to… chodíte na web, který sice obsahuje užitečné informace, ale ty se nedají rozumně filtrovat a procházet. Žádné API nemají (nebo jej neznáte) a rádi byste si usnadnili práci s jejich daty.
Takový problém jsem měl třeba s kalendářem akreditovaných vzdělávacích akcí pro lékaře na webu České lékařské komory. Obsahuje hromady akcí, ale filtrovat se dají jen podle data, čísla akce (???) a fulltextu. Pokud si chcete najít akci, která se zabývá konkrétním tématem a bude se konat na konkrétním místě (a třeba ještě hledáte konkrétního garanta), tak jste v háji. Pokud teda selže fulltext. Navíc aktuálně tam jsou k dispozici akce jen na listopad a prosinec, nikoli minulé akce nebo akce na příští rok (přestože úpravou URL parametrů se k nim lze dostat). Nemluvě o tom, když si chcete akci vyexportovat do svého kalendáře.
Což takhle mít akce v přehledném formátu (CSV, JSON apod.) a moci si je zpracovat podle svého uvážení? Třeba vlastním skriptem, kalendářem nebo, probůh, klidně i excelem? :-)
Odpovědí může být web scraping. Už dříve jsem se chtěl naučit se službou Apify, která taková kouzla dokáže. Koneckonců jsem to veřejně napsal i tady na blogu. A snaha o získání kalendáře mě přiměla, abych se k Apify dostal doopravdy.
Úvod do Apify
Apify je (aspoň jak to jako laik chápu) služba, která uživateli usnadní procházení většího počtu webových stránek a vytahování užitečných informací z nich. Tedy pomůže tam, kde chybí rozumné API, kde potřebujete specifickou funkci, kterou web nenabízí, nebo chcete prostě získat data nějakým způsobem, který se hrozně moc opakuje a z ručního kopírování by vás trefil šlak.
Po registraci si můžu vytvořit crawler, což je vlastně robot, který za mne prochází zadané webové stránky podle předem daného algoritmu, získává z nich odkazy na další stránky a ukládá obsah, který mě zajímá. Na každé stránce si můžu spustit nějaký JavaScriptový kód, který mi žádaná data vytáhne. Něco podobného, jako byste si na každé stránce ručně spustili vlastní kód přes konzoli prohlížeče. Zároveň se dá rozlišit, kde chcete jen získat odkazy na další stránky k procházení a kde chcete procházet a ukládat obsah.
Dále je tam možnost vytvořit actor, což je pokročilejší služba, která může provádět automatizaci na webu nebo extrakci dat. Můžete pak třeba i poslat maily, exportovat výsledky do jiných služeb (třeba Google Spreadsheets i jinam) a tak. Ale upřímně, tak daleko jsem se zatím nedostal. Nějaké skripty mají v knihovně.
Všechno si můžete zautomatizovat, naplánovat na určitou dobu či interval, nebo dokonce spustit a ovládat přes API nějakým svým vlastním skriptem (a přes API taky následně získat informace o průběhu a výsledek).
Apify použil třeba Michal Bláha na analýzu filmových recenzí Mirky Spáčilové nebo Jakub Balada na porovnání hodnocení filmů mezi Františkem Fukou a Mirkou Spáčilovou. Hezké. :-)
Ale konec dřystů, pojďme na ten kalendář České lékařské komory.
Začínáme: prozkoumáme kalendář
Nejsem moc dobrý v psaní tutoriálů, ale zkusím popsat, jak jsem postupoval.
Kalendář akreditovaných vzdělávacích akcí ČLK najdu na jejich webu. Nejprve se zobrazí formulář pro vyhledávání. Já budu chtít procházet data z určitého měsíce, takže si přes konzoli prohlížeče najdu, které proměnné se o to starají, a ty pak použiju v URL jako požadavek GET. Zde se jedná o proměnné filterRok a filterMesic a mohou být předány pomocí POST i GET. Ve svém skriptu využiju GET.
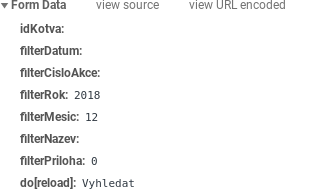
Pak se podívám na stránkování výsledků. Vždycky se inkrementuje proměnná paging.pageNo v URL adrese.
https://www.lkcr.cz/vzdelavaci-akce-akreditovane-clk-204.html?paging.pageNo=1
Takže víme, kde chceme začít získávat data, jak vypadají proměnné pro vyhledávání a jak vypadá stránkování. Stránkovací odkazy se nacházejí přímo ve formuláři s id form ( #form a).
Stránky rozdělíme podle účelu a také si je pojmenuji. V rámci kontextu pak můžu rozlišit, kde chci jen projít odkazy na další stránky, a kde chci uložit data z webu do tabulky. URL na dané skupiny můžu zapsat ve formě regulárního výrazu (vlastně pseudo-URL).
- start - startovací stránka, na které si zjistím nakonfigurovaný měsíc a rok, nic jiného nedělám;
- search - první stránka, na které projdu stránkovací odkazy, ale ještě její obsah neukládám (dojdu k němu ještě jednou z ostatních stránek, protože na druhé stránce se objeví odkaz na tuto první…);
- list – na téhle stránce chci jednak projít stránkovací odkazy (a pokud některý z nich crawler ještě nenavštívil, tak jej zařadí do fronty) a jednak chci projít a uložit i obsah.

Všimněte si, že mám stránky rozdělené podle URL a pojmenované na zmiňované tři skupiny. To pak využiju v kódu.
Dali jsme tedy skriptu informace, kde budeme začínat a kde pokračovat. Teď je potřeba říct, co na stránkách chceme dělat.
Procházení obsahu stránek
To už bude záležitost jednoduchého JavaScriptu. Protože si můžu na každou stránku nechat načíst jQuery nebo Underscore.js, tak je procházení ještě jednodušší.
Kód, který chci spustit na každé stránce, je uzavřen ve funkci pageFunction(context). Pomocí vlastností contextu můžu rozlišit, na stránce ze které skupiny se nacházím a jestli ji chci jen prolétnout a uložit odkazy (a výstup zahodit pomocí funkce context.skipOutput()), nebo chci procrawlovat a uložit i obsah. A také si mohu nechat načíst kód z kolonky Custom data, kde můžu mít uloženu nějakou měnitelnou konfiguraci pro běh skriptu.
![]()
Všechno, co funkce pageFunction() vrátí, se uloží do výsledkové tabulky.
Kód crawleru
function pageFunction(context) {
var $ = context.jQuery; // nacteme jQuery
var result = []; // pole s vysledky za danou stranku
/**
* dalsi postup podle labelu (viz nastaveni - start urls, pseudourls):
*
* - start url - slouzi jen k ziskani data z Custom data, neni crawlovano
* - search url - prvni stranka s vysledky, jeste nejsou crawlovany (duplicita)
* - list url - vysledky ke crawlovani
*/
switch(context.request.label) {
/* start url: ziskame nastaveni z policka "Custom data" (JSON) */
case "start":
var customData = JSON.parse(context.customData);
var year = customData.rok;
var month = customData.mesic;
var startUrl = "https://www.lkcr.cz/vzdelavaci-akce-akreditovane-clk-204.html?filterRok=" + encodeURI(year) + "&filterMesic=" + encodeURI(month);
context.enqueuePage({
url: startUrl,
queuePosition: "FIRST"
});
context.skipOutput();
break;
/* search url: ziskame jen vypis stranek, necrawlujeme obsah, jen linky */
case "search":
context.skipOutput();
break;
/* crawler na CLK kalendar */
case "list":
$("table.seznam").each(function(){
/* najit pole tabulky s uzitecnymi daty */
var clk_values = $(this).find("tr td:last-child");
/* popis udalosti */
var clk_event = {
akreditace: clk_values.eq(0).text().trim(),
cislo_akce: clk_values.eq(1).text().trim(),
nazev_akce: clk_values.eq(4).text().trim(),
zacatek_akce: clk_values.eq(5).text().trim(),
konec_akce: clk_values.eq(6).text().trim(),
pocet_hodin: parseInt(clk_values.eq(7).text().trim()),
misto_konani: clk_values.eq(8).text().trim(),
poradatel: clk_values.eq(9).text().trim(),
garant: clk_values.eq(10).text().trim(),
kredity: parseInt(clk_values.eq(11).text().trim())
};
/* ulozit udalost do seznamu */
result.push(clk_event);
});
break;
}
/* ulozit seznam vysledku */
return result;
}
A je to. Myslím, že samotný kód už je jasný, obsahuje nekomplikovaný JavaScript, který odliší již popsaný kontext do tří skupin (start, search a list) a podle toho jen projde odkazy nebo i obsah. Z výsledkové tabulky kalendáře načte všechny dostupné události, rozdělí data do sloupců a pak načte další stránku z fronty.
Výsledkem je hezká tabulka, CSV, JSON nebo XML, které si mohu dále zpracovávat. Není zveřejněna, každý si musí spustit vlastní běh, pokud má o kalendář zájem. :-) Viz stránka crawleru.

Pro nýmanda jako jsem já takový základ úplně stačí. Prý se na takové službě dá založit i byznys (prohledávání výsledků vyhledávačů, SEO analýzy, bůhvíco). Lidi tam mají i crawlery na analýzu cen v rámci Black Friday a podobné nástroje… Mrkněte sami; myslím, že jde o docela šikovný nástroj na hraní i na užitečnou práci.
Zajímavé odkazy
- Apify dokumentace
- Michal Bláha: Filmová kritička Mirka Spáčilová v číslech
- Jakub Balada: Jak je sladěná Mirka Spáčilová s Františkem Fukou, ČSFD a IMDB?
- Jakub Balada: Black Friday po česku — kouzla se slevami
Aktualizace 27.11.2018 v 13:55 – aktualizovány zajímavé odkazy.
-
Jakub Balada (neregistrovaný)
Diky za feedback.
ad 1) nizsi uroven abstrakce znamena take vyssi flexibilitu
ad 2) v Apify neni nutne nastavit vystup do souboru, ten je automaticky dostupny v json, csv, xlsx, xml, jsonl a rss, viz link v clanku: https://www.apify.com/petrkajzar/SujpE-api-lkcr-cz -
Jakub Balada (neregistrovaný)
Apify ma open-source SDK (https://sdk.apify.com) uplne stejne jako ScrapingHub ma Scrapy. Tzn., ze si crawlery muzete vyvijet a provozovat lokalne, pripadne na vlastni infrastrukture, stejne jako se Scrapy...
-

Myslím, že to chápete špatně. Scrapy není primárně k tomu, aby běželo někde v cloudu. Scrapy je framework, v kterém si pouštíte vaši scrapovací aplikaci a co běží na vašem počítači. Není to tak, že se pouští lokálně z důvodu vývoje, lokálně se běžně pouští i produkčně. Scraping cloud a podobné služby běžně vůbec nepotřebujete.
-
Zima (neregistrovaný)
Ja bych pétreboval neco takoveho na Download List v PlayStation Store. Ten je naprosto tragicky, mam tam 1800 polozek, zobrazuji se po 24 na stranku, nacita se to pomalu, takze to nejde rychle projit, nejde to tridit, filtrovat vubec nic. Jenze jsem vzdycky pohorel na jejich autentizaci. Kdyby nekdo znal reseni, bylo by to parada.
-
Jakub Balada (neregistrovaný)
Pokud tam nemate dvoufaktorovou autentizaci, tak by to nemel byt problem automatizovat. Tady je treba priklad, jak se pred samotnym stahovanim dat prihlasit na Facebook. Pokud s tim chcete pomoct, dejte vedet na support@apify.com
-
I některá dvoufaktorová ověření lze obejít. Například Google Authenticator lze v Pythonu nahradit tímto: https://github.com/pyauth/pyotp





















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU