Jak na databáze : 3.NF - paskvil zavaný široká tabullka
"Velké, šíré, rodné lany, zežloutly jste na všechny strany! Od souvratě ku souvrati bude nás ta žlutá sráti" (Jiří C. Wavrovský)
A kdyby len barva, ale i ta šíře. Klasický případ, víš mi máme takový a takový produkt a k tomu bychom potřebovali evidovat ještě tenhle atribut a tenhle a tenhle … Super. Výsledek tabulka 30 sloupců. Pak realizuj select. 2 000 000 záznamů a scan v selectu ne a ne skončit. Pak si vzpomeneš, že v PostgreSQL existuje ještě něco jako SET enable_seqscan = OFF. Ale záchrana jen dočasná. Nutná superindexace, která pomůže pouze do chvíle než potřebuješ updatovat. Pak si vzpomeneš že existuje něco takového jako 3. normální forma.
Abstrakce: 3. normální forma
Tabulka ja v 3. NF když :
- Je v 2.NF
- Tabulka neobsahuje sloupce, které lze přenést do jiné tabulky.
Poznámka :
Jedná se o takzvanou tranzitivní závislost. Česky řečeno míchat jablka s hruškami. Nebo ze všech sloupců tabulky lze separovat dvě a více nezávislých entit.
Příklad : Dodržíme syntax
Hledal jsem na internetu nějaký seznam knih u které jsou uvedeny i biografické údaje o autorovi, ale nenašel jsem jej. Ale našel jsem tam tento příklad:
| číslo | příjmeni | jméno | název | místo | nakladatelství | rok | datum | cena |
|---|---|---|---|---|---|---|---|---|
| 26 | Čech | Svatopluk | Hanuman | Praha | MF | 1957 | 27.9.1978 | 8,30 |
| 27 | Čech | Svatopluk | Jestřáb contra Hrdlička a jiné po. | Praha | MF | 1952 | 2.9.1978 | 15,00 |
| 29 | Čech | Svatopluk | Písně otroka | Praha | SPN | 1956 | 29.9.1978 | 3,80 |
| 30 | Čech | Svatopluk | Písně otroka | Praha | SPN | 1956 | 29.9.1978 | 3,80 |
| 31 | Čech | Svatopluk | Písně otroka | Praha | SPN | 1956 | 29.9.1978 | 3,80 |
| 32 | Čech | Svatopluk | Písně otroka | Praha | SPN | 1956 | 29.9.1978 | 3,80 |
| 35 | Čech | Svatopluk | Ve stínu lípy | Praha | Topič | 1935 | 29.9.1978 | 1,10 |
| 36 | Čech | Svatopluk | Výbor poezie | Praha | MF | 1951 | 29.9.1978 | 13,50 |
| 37 | Čech | Svatopluk | Výlety pana Broučka | Praha | Melantrich | 1952 | 29.9.1978 | 18,80 |
Když se podíváme pozorně na seznam, tak tam vidíme, že tato tabulka obsahuje sloupce, které lze seskupit do nezávislých entit (tabulek). Já tam vidím kniha titul (abstraktum), kniha (konkrétní vydání),kniha evidence,autor a nakladatelství. Z toho můžeme zkonstrulovat takovýto entitno-relační diagram (ERD).
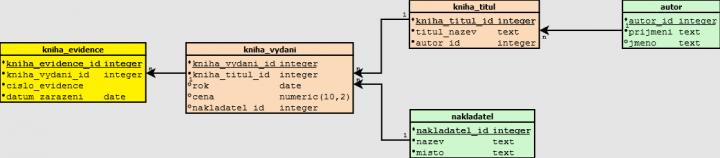
Nutno podotknout, že na to aby Jste viděli vztah, že tabulka lze rozdělit na další entity, musíte se rozumět datům. Vědet o jaká data se jedná – poznat sémantiku dat. Kdybychom přistupovali čistě mechanicky, pak bychom mohli mohli příjmení, jméno a místo sloučit do jedné tabulky.
Připadá Vám to příliš složité ? Nemusí. Jedným vstupem můžete pomocí funkce odeslat do databáze data např. pomocí json formátu. Ve funkci je pak můžete rozpársrovat a uložit do příslušných tabulek tak, že budete kontrolovat duplicitu. V případě, že se vyskytne ji automaticky ošetříte. Ve výsledku, ale budete mít data lehce dostupná a navíc v 3.NF.
A co sémantika ?
V případě 3. NF jak jsem se zmínil sémantika, porozumění datům hraje klíčovou roly. Bez ní nedokážete rozlišit entity v tabulce a strukturovat data.
Chcete vědet jak to dopadlo s tabulkou s 30 sloupci ? Ukázalo se, že je možné rozdělit takúto tabulku na několik subtabulek a s vazbou 1:1 na hlavní tabulku. Úspora nebyla jen místa, ale i v rychlosti přístupu k datům.
A všichni žily spokojeně a šťastlivě do doby než se objevila 4. normální forma, ale o té příští týden.
Poznámka:
Může vzniknout falešná iluze, že v 3.NF jde hlavně o redukci širokých tabulek. Tak tomu není. Hlavní věcí je redukce duplicitních dat v tabulce. Tak abychom nedostávali nad stejnými daty různé výsledky. Široké tabulky hlavně souvisí s výkonem. Ale vždy když jsem se setkal s širokými tabulkami, tak to bylo jako přímí důsledek buďto lenosti architektů, nebo tlačením vývojářů na zkrácení času pro vývoj, nebo neschopností více strukturovt data – poznat jejich sémantiku.
Jak říkal Geothe „jádro pudla“ spočívá možná taky v neznalosti možností DDL SQL (data definition language) jazyka a schopností té které databáze. Jinak musíme přistupovat k datům v MS Access databázi, kde se širokým tabulkám někdy nevyhneme a jinak v PostreSQL nebo v Oracle, SQL Serveru kde máme možnosti mnohem šiřší.
-
Ivan Nový (neregistrovaný)
Nic proti normalizaci tabulek, ale je třeba si uvědomit, že duplicita dat nese i dodatečnou informaci, která je uchována v souvislostech mezi údaji, nikoliv explicitně v záznamu tabulky.
Například v datech lze hledat další souvislosti podle toho, kdy byly duplicitní věty přidány, zachovává se historie, aniž by se předem muselo vědět, jaký druh informace budeme v budoucnosti potřebovat.
Pokud entity uložíte do číselníku, tak o tuto informaci přijdete, díky unikátnímu klíči.
-

Děkuji za názor.
Myslím, že normální formy slouží pouze jako návod jak by si mněla modelovat struktúra databáze, aby byla efektivní. V realitě, je to ovšem někdy odlišné a když člověk pak dělá datový model, tak musí často sáhnout ke kompromisům, nebo jít někdy úplně proti principům datového modelování.
Přesto všechno se domnívám, že když je znalost normálních forem, tak pak člověk ví, že když má možnost, může strukutu navrhnout tak, aby byla efektivní.
V mích příspěvcích chci hlavně popularizovat relační databázovou teorii. Proto se snažím vytáhnout špatné a dobré příklady fornu hesel jako "Paskvil zvaný široká tabulka" , nebo "Číselníky", "Nesouvisející relace", aby pak každého trklo, že když něco dělá pak si vzpomene na : A tady mám nesouvisející relace, ty nějak souvisí 4.NF jak na to -
Zdá se, že v uvedeném příkladu jsou záznamy 29 až 32 zcela duplicitní? Možná chyba příkladu?
Taky mi nepřijde úplně šťastná formulace "je možné rozdělit takúto tabulku na několik subtabulek a s vazbou 1:1 na hlavní tabulku". Pokud se ošklivě nepletu, tak se jedná o vazbu m:1. Zdůrazňuji to proto, že v případě vazby 1:1 bych ponechal paskvil zvaný široká tabulká. Protože semantika. Rozděloval bych to jen v případě, kdy by mě k tomu donutili technické (výkon) důvody.
