Pár postřehů o architektúře databáze
neboli “Kdy dva dělají totéž, nidky to není totéž”
Většina začínajících databázových architektů se domnívá, že nakreslením obdélníků s názvem tabulky, definici sloupců a čar spojujících tabulky, jejich práce končí. V praxi pak potkávám fyzické datové modely, které obsahují v tabulce pouze primární klíč a indexy, které tam vygeneroval databázový engine při tvorbě cizích klíčů (foreign key). Výběr dat je pak pomalý a importovaná nebo zadávána data jsou v pořádku pouze tehdy, než lidská chyba data ‘nepokazí’.
Relační databáze toho nabízí ovšem mnohem více a často dokáže chybám v datech předejít.
Slabá a silná databáze
Když jsem začínal s relačními databázemi, tak jsem mněl tu výhodu, že bylo nutné vytvořit silnou databázi, z které se odvozovali pravidla pro zadávání dat ve formulářích GUI. Bylo to na bázi jazyka 4. generace (4GL). To nás nutilo udělat databázi co nejsilnější, která využívala veškeré dostupné databázové prvky.
Dnešní databázový vývoj v mém okolí spíše směruje k slabým databázím, které nevyužívají plnou kapacitu nástrojů, kterou má databáze k dispozici. Datová integrita je zabezpečená procesem zpracování dat a nástroji zpracování. Databáze pak, když získává data z jiných zdrojů, není schopna zabezpečit datovou integritu a data mohou být chybná. Na druhé straně je extrém, kdy fyzický datový model je navržený dle obecných pravidel a silné databáze, která hlídá veškerá přibývající, nebo změněná data, není schopna rychlé odezvy.
Uvedu jeden příklad z praxe. Firmy zabývající se energetikou mají desítky typů různých zařízení představujících tabulky a statisíce fyzických zařízení, u kterých se evidují různé technické parametry. Jedním z parametrů je evidence uživatele, který na daném konkrétním zařízení provádí revize. Vše funguje v pořádku do doby, než se má změnit osobní číslo osob provádějících revizi. Neboli databázově řečeno změní se primární klíč v tabulce Zaměstnanec. Tehdy silná databáze, u které je zapojena referenční integrita začne ověřovat u desítek tabulek a v každé se statisíce záznamů referenční integritu, čím spolehlivě vyřadí databází na několik hodin z činnosti. A je otázkou jestli je databáze dost robustní a dimenzovaná tak, aby obrovské množství dat v transakci zvládla.

Řešení vypnout referenční integritu pomůže, ale ohrozí integritu dat. Dalším řešením je v tabulce údržby vytvořit vedle starého záznamu i nový záznam s identifikací a ním v menších transakcích nahrazovat v jednotlivých tabulkách zařízení původní osobní číslo.

Nebo použít v tabulce údržby jako primární klíč abstraktní identifikátor zaměstnance a osobní číslo použít pouze v tabulce zaměstnanců a i to pouze jako jedinečný klíč (unique key), na kterém neexistuje pověšena žádná referenční integrita. Toto řešení provede změnu osobního čísla v zlomku vteřiny, protože se ověřuje pouze jeho jedinečnost v tabulce zaměstnanců.

Zdravý skeptik neznalý SQL ale namítne. To mám pokaždé, když natahuji data o údržbě nějakého zařízení, taky natahovat osobní číslo zaměstnance? Odpověď zní ano. Ale nemusíš u všech záznamů, pouze u těch, které si aktuálně zobrazí ve formuláři. Řečeno jazykem SQL udělá se nejdříve subselect zařízení a na výsledku se udělá spojení s tabulkou zaměstnanců.
select zar.<zarizeni>, zam.os_cislo
from (select <zarizeni> from zarizeni where <podminka>) zar
inner join zamestnanec zam on zam.os_id = zar.revize_id
Nadějný začínající databázový architekt si ale povzdechne, jak mám navrhnout optimální databázi, když nevím, jak se bude používat?
Odpověď je opět jednoduchá. Důležité je zmapovat veškeré požadované procesy, které se budou nad databázi provádět a dle nich navrhnout design databáze. V jazyku UML je to USE CASE. Jinde procesy.
Vzorové SQL dotazy
Udělat optimální databázi znamená často hodně zkomplikovat SQL dotazy pro výběr dat z databáze pro jednotlivé pohledy ve formulářích a přehledech. Velice se mi osvědčila praxe, kdy po návrhu databáze připravím pro frontend programátory dle zadání vzorové SQL, nebo databázové view. Úplně ideálním řešením je přistupovat k datům přes uložené procedury a funkce. Umožňuje to vevnitř procedury připravit logiku, která umožňuje data editovat dle jednotlivých tabulkách bez toho, aby byl frontend programátor zatížen databázovým rozmístěním dat.
Vyvinit se
Slovo, které jsem před 15 lety neznal. Často řeším problémy v datech je, že na formuláři nejsou vidět data, která tam mají být viděny, nebo jsou jiná, než mají. Odpověď frontend programátorů je typická „Za to může databáze.“. Přehodí břímě důkazů na databázi, neboli snaží se vyvinit. Velice mi tehdy pomáhají servisní data, které připojuji k tabulkám. Jako je kdo, kdy zadal dané data do databáze, nebo jakým procesem se dostali do databáze, nebo jakým procesem byla zpracována. U kritických dat je hodně někdy důležité logovat veškerou činnost nad daty do logovacích tabulek.
Stalo se mi, že architektura frondend a backend aplikací byla tak špatně zrealizována, že umožnila, aby v tom stejném čase uživateli a backendovému procesu vydat dva protichůdné odporující si příkazy, které data vrátili o krok zpátky, ale současně i o krok dopředu. Pak ve výsledku se objevili duplictní data na výstupu. Řeknete si, že je to málo pravděpodobné, aby se to stalo, ale stalo se. Až výpisem z logu jsem mohl dokázat, že tento případ nastal. Aplikace zde v jedné transakci provedli sérií SQL příkazů nad jedním stavem záznamu. Jedna tam a druhá zpátky. Přičemž ani jedna nemněla v sobě zabudovaný mechanizmus check-in,check-out. Znamená to, že v jedné transakci testuji, jestli můžu z jednoho stavu přejít do druhého a zablokuji si tento stav pro sebe (check-in). V druhé transakci provedu změny, ale pouze v případě, že mám blokaci na sebe a současně provedu odblokovaní svého stavu (check out). Takhle je zabezpečeno, že i když jiná aplikace ve stejném okamžiku provede check in, tak 1. aplikace v druhé transakci se neprovede, protože detekuje, že databáze není blokována na 1. aplikaci.
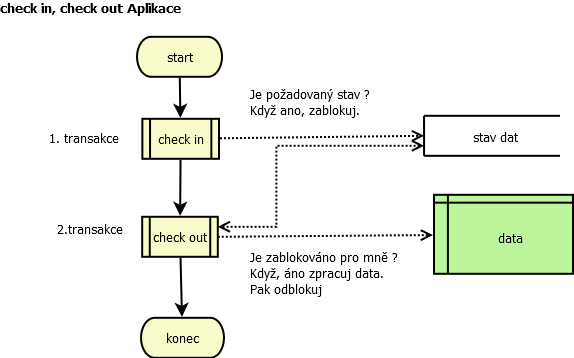

Závěrem :
Rád když můžu, tak tvořím silnou databázi, která je nezávislá na aplikacích dodávajících data. Pokud je to možné, tak databáze si hlídá datovou integritu sama. Návrh databáze není poplatné pouze entitám a relací mezi nimi, ale i hlavně procesům, které pracují s daty. Proto tak je nezbytné zmapovat procesy. Když dva dělají totéž, tak nikdy to není totéž.
-
vp (neregistrovaný)
Nerozumím vyřazení DB na několik hodin z provozu. V tabulce zaměstnanec přepnu starého zaměstnance jako logicky smazaného (něco jako flag_deleted = Y) a vložím nového zaměstnance. Nyní mohu v tabulce zařízení změnit odkazy na nového zaměstnance. Update statisíců záznamů je v řádu sekund. OK, pokud bych čistě teoreticky měl nějaký ostrý OLTP systém s masivním provozem, tak napíšu proceduru, která bude updatovat po menších porcích, v extrému i po jednom záznamu, a pokud by došlo ke konkurenci o jeden záznam s jinou transakcí, budu muset řešit čekání anebo opakování pokusu o update. Pochybuji ale, že se zde jedná o takový systém :-)
