Porovnání gzip, bz2, xz a zstd ve všech stupních komprese
Zajímalo mě, jak se chová zstd v porovnání s dalšími běžně používanými kompresory. Udělal jsem si skript a ten provedl „pár“ testů, a když jsem si uvědomil, kolik to sežralo elektřiny, tak jsem se rozhodl, že to alespoň publikuji :-)
- byly použity tyto verze kompresorů: gzip 1.6, bzip2 1.0.6, xz 5.2.2, zstd 1.3.3
- Intel Core i7–6700 @ 3.40GHz (4×2 jádra, komprese na jednom jádře), 16 GB RAM
- komprese připraveného tar souboru uloženého na SSD byla prováděna přímo kompresorem do souboru na klasickém disku
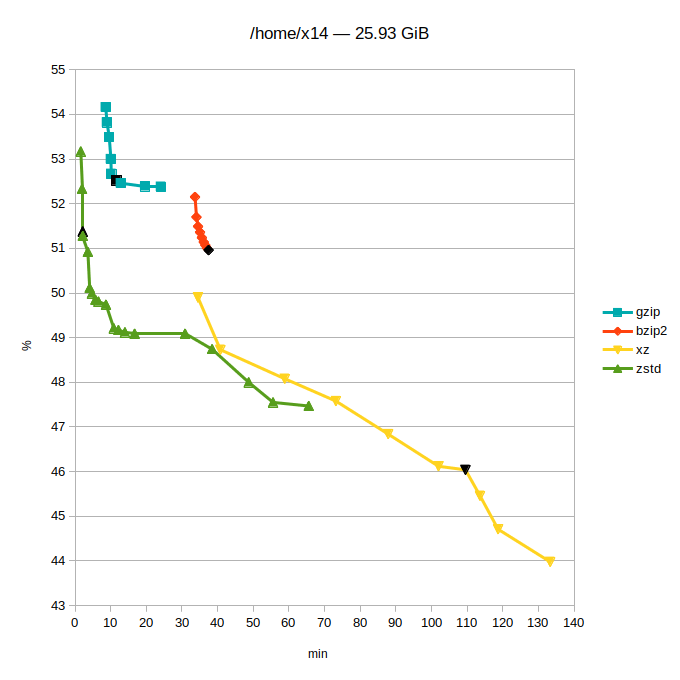
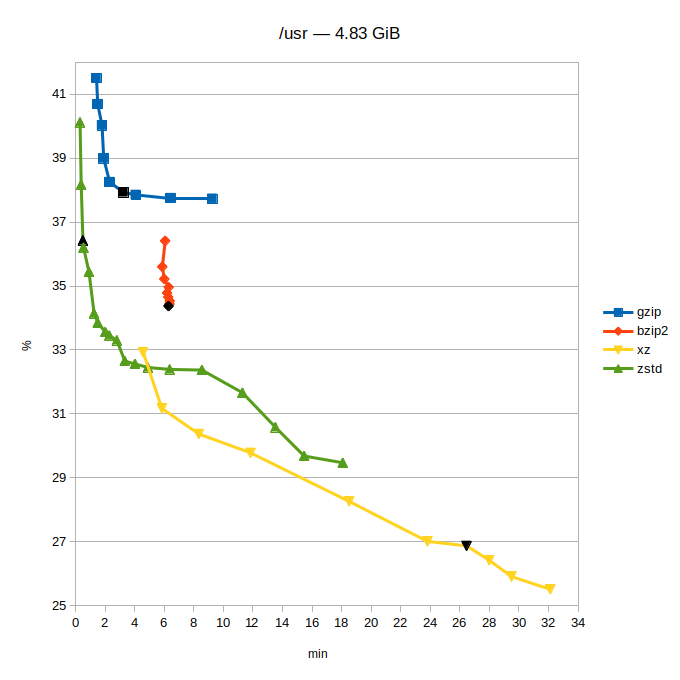
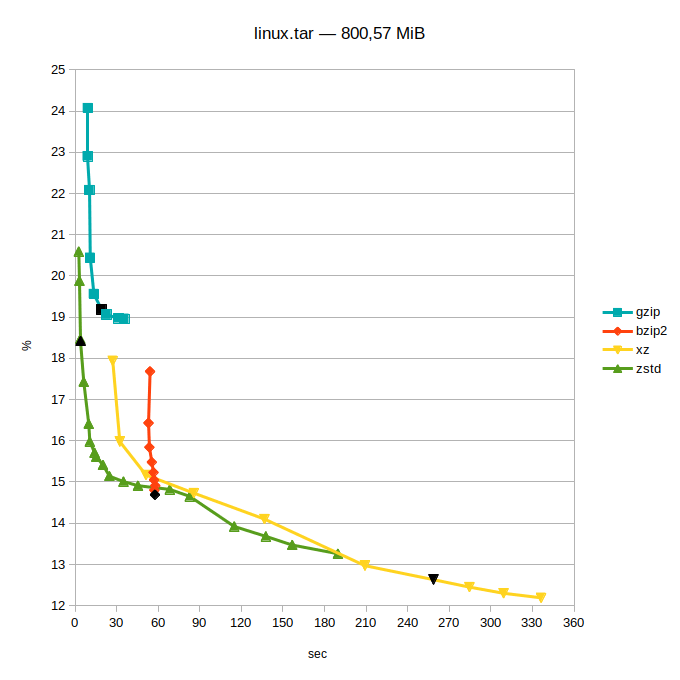
- tři sady dat: můj home (plný nekomprimovatelných věcí, programů, zdrojáků – prostě bordel), aktuální /usr a zdrojáky jádra Linuxu stažené z kernel.org
- svislá osa grafů: uspořené místo v procentech původní velikosti (méně je lépe)
- vodorovná osa grafů: potřebný čas (méně je lépe)
Parametry komprese
Při testu byl použit pouze číselný parametr síly komprese -#. U každého programu byl použit celý rozsah (toto doma nezkoušejte :-). Číslo uprostřed intervalu je výchozí hodnota, tuto nejspíš automaticky použije naprostá většina lidí. V grafu je označena jako černý bod.
- gzip: 1–6–9 (výborně vybraná výchozí hodnota, pěkně „za kopcem“ :-)
- bzip2: 1–9–9 (zde tato hodnota téměř neovlivňuje dobu komprese, jen použitou paměť)
- xz: 0–6–9 (zajímavost: hodnota 0 byla programátory nastavena tak, aby vždy fungovala lépe než ‚gzip –9‘)
- zstd: 1–3–19 (s tou trojkou mohli možná trochu přitlačit…; existuje parametr –ultra, který povolí hodnoty až 22)
Poznámka na konec
Doporučuji jednoznačně používat standardní přípony. Pak bude v GNU tar fungovat automatika a stačí psát: tar cavf, tar xavf
- gzip: .tar.gz, .tgz,
- bzip2: .tar.bz2, .tz2, .tbz2, .tbz
- xz: .tar.xz, .txz
- zstd: .tar.zst, .tzst (automatika funguje až od verze GNU taru 1.31, jinak je potřeba psát tar -I zstd -cvf )
Závěr
Pokud jde o kvalitu komprese, tak gzip a bzip2 jsou téměř mimo hru. Doporučuji povšimnout si, v jakém čase zstd vygeneruje podobně velký archiv. Pro bzip2 bude toto v budoucnosti nejspíše konečná. (Možno doporučit snad jen ke studiu BWT, to je velice fikaný nápad.) Kompresor gzip je na tom určitě o dost lépe, ten tu bude ještě hodně dlouho – hraje pro něj zpětná kompatibilita (je úplně všude) a vystačí si minimem paměti.
Další dva moderní kompresory se rozcházejí v záměrech: zstd cílí na maximální rychlost, xz na maximální kompresi (to ostatně naznačují už výchozí hodnoty komprese: zstd 1-3-19, xz 0-6-9). Tam, kde se tyto dva kompresory potkávají, jde o moc pěkný souboj. Teď už si musí každý zvážit, jestli mu ty jednotky ušetřených procent (které ale zase mohou dělat několik klíčových giga) u xz stojí za ten čas. Upozorňuji, že první dva grafy mají čas v minutách! Snad se to může vyplatit u distribuce velkých dat, ukládání „věčných“ archivů nebo limitních situací…
Pro takové to domácí pakování je pro mě vítězem jednoznačně zstd.
-

Nechapem naco by tar pouzival paralelizmus, ved je to len catovanie suborov za sebou.
a multi cpu xz kompresia je v pixz https://github.com/vasi/pixz -

Xz má přepínč -T na paralelizaci. Sám autor pixz se k němu kladně vyjadřuje, viz https://superuser.com/a/897325/205301.
-
Ono je to vždy o datech, ani teď se bzip2 neztratí. Na můj use-case (textová data z osciloskopu) mi udělá z 2.1GB 318MB.
Xz na výchozí uspoří proti bzip2 jen 2.8% (z komprimované, ne celkové velikosti), což mi za to nestojí, - místo pár minut to chroustá půl hodiny. Pokud ho dám na časově srovnatelné -2, tak je zas +22% proti bz2...
Gzip je o 50% větší a s -9 je změna minimální.
Zstd s výchozí kompresí je na úrovni gzipu (!) s +47%, ale je opravdu pekelně rychlý. Při -13 s proti bzipu o něco pomalejším časem pořád +23%.
Jinak zstd vypadá zajímavě, ale na mnoha místech asi nebude pro mě k dispozici. Každopádně na tato data bzip2 nemá moc konkurenci, marginálně lepší je jen xz za rapidně pomalejší kompresi.
-
 Adam KaliszStříbrný podporovatel
Adam KaliszStříbrný podporovatelZkoušel jste si udělat zstd slovník (dictionary) a hlavně tzv. long mode (--long)? Je možné, že by to potom bylo výrazně lepší?
-
X-Lorrien (neregistrovaný)
Ve výsledku stejně záleží na tom, co se komprimuji. Když jsem testoval kompresní metody pro ansu (beta cae) a srovnával proměnné čas a kompresní poměr, případně zapojení multithreadingu, vyšel nejlépe - téměř s dvojnásobným odstupem - bz2. Mimochodem, proč jste netestovali 7z?
-
 peci1Stříbrný podporovatel
peci1Stříbrný podporovatel> svislá osa grafů: uspořené místo v procentech původní velikosti (méně je lépe)
no nevim, mene usporeneho mista je lepe? neslo by to preformulovat?
-
peci1Stříbrný podporovatel
souhlasim s tim, ze by osy u komprese mely zacinat na nule
slo by prosim pridat jeste grafy pro dekompresi? pak by to bylo uz ultimatne uzitecne :)
-
Na moje data (spousta namerenych cisel) nejlepe vychazel 7z. Ale nedelal jsem takovou analyzu jako tady v clanku.
Taky jsem zjistil, ze cas od casu potrebuju z komprimovanych dat extrahovat jeden soubor. A jelikoz pouzivam Krusader, styl prace je ze v krusaderu vlezu do adresare a dekomprimuju prave jeden soubor. xz ma tu nevyhodu, ze pouhy vypis seznamu komprimovanych souboru trva neprijemne dlouho (desitky vterin u ~10 GB komprimovanych dat s ~10^4 komprimovanych souboru).
-

Škoda že jsi nepoužil pro porovnání i 7z. Přidávám pár testů 7z, je zajímavý tím, že má možnost volit kompresní algoritmus. 7z nepotřebuje tar, spojí si to sám.
balík: p7zip-16.02_1
procák: i5-6360U@2GHz 2c/4htBalil jsem node_modules adresář, vesměs zdrojáky, obrázky a pár binárek.
3271 folders, 22183 files, 297182602 bytes (284 MiB)LZMA2:
# 7z a -t7z -m0=lzma2 -mmt=2 -mx=9 -mfb=273 -md=1024m -ms=on pokus.lzma2.7z node_modules/
Archive size: 22440841 bytes (22 MiB)
140 secPPMd:
# 7z a -t7z -m0=PPMd -mmt=2 -mx=9 -ms=on pokus.ppmd.7z node_modules/
Archive size: 44635838 bytes (43 MiB)
53 secLZMA:
# 7z a -t7z -m0=lzma -mmt=2 -mx=9 -mfb=273 -md=1024m -ms=on pokus.lzma.7z node_modules/
Archive size: 22458720 bytes (22 MiB)
141 sec(t)GZ:
# tar czf pokus.tar.gz node_modules/
Archive size: 67293726 bytes (64MB)
12 sec(t)BZip2:
# tar cjf pokus.tar.bz2 node_modules/
Archive size: 58137871 bytes (55MB)
33 secTakže až je požadavek na velikost archivu a nezajímá vás čas tak jednoznačně 7z s lzma2.
-
Hezký test, ještě mi tam chybí brotli, který už je dokonce podporován jako content-encoding v HTTP. Zstd podalo návrh myslím někdy na podzim minulý rok. Brotli má navíc slovník, který by měl iniciálně zvýhodňovat HTML dokumenty, takže srovnání je trochu nefér.
Gzip si stále ponechává výhodu v malé paměťové spotřebě. Pokud budu mít server s 10000 konexema, tak se zstd nebo brotli můžou docela prodražit. Gzip musel běžet v Dos na PC s 500kB reálně využitelné paměti.
Bzip2 je prakticky mrtvý už dlouho. Nejen kvůli pomalosti komprese vs poměru komprese, ale hlavně kvůli extrémní pomalosti dekomprese. Tím značně ztrácí u typického použití, kdy se jednou zabalí a potom mnohokrát rozbaluje. Ten výrazně lepší poměr u textových dat z osciloskopu mě docela překvapuje, viz dále.
Nebylo by od věci rozšířit vzorek dat, home a /usr budou předpokládám obsahovat množství binárních dat. Zstd i Brotli exceluje hlavně na textových datech. Matně si pamatuju svůj test na JSON (stovky MB), kde se Zstd dostal na 60% oproti Gzip a 110% oproti Xz. Bzip2 byl na 97% oproti Xz. Samozřejmě nesrovnatelné časy, i když Zstd nad cca 13 taky začně velmi zpomalovat.
Zajímavosti Zstd je, že nebyl brán ohled pouze na efektivitu algoritmu, ale i na jeho implementaci v současných CPU. Umožňuje tak snad paralelizovat instrukce v různých ALU. To možná vysvětluje jeho pomalejší běh na ARM, které nemusí mít tak dobrou schopnost paralelizace jako x86_64 (ale nejspíš bude záležet na generaci a orientaci).
-
Musím se omluvit všem čtenářům za zmatení. Hned v úvodu článku chybí zcela klíčová věc, která by odpověděla minimálně na polovinu zdejších námitek.
Snažil jsem se o co nejobyčejnější použití programu tar.
To použití mělo být bez frikulínských komandlajn s tunou parametrů, které z rukávu jen tak někdo nevysype, a bez programů, které nejsou nainstalovány, nebo dokonce ani nejsou v dosahu apt-get install. Zkrátka a prostě – když přijdu na jiný počítač, tak chci napsat:
tar cavf /back/home.tar.[gz|xz|bz2|zstd] *Je mi jasné, že existuje spousta kombinací, co se dá testovat – více jader, rychlost dekomprese, obsazená paměť, různé alternativy programů... Nic z tohoto jsem ale testovat nechtěl. Nešlo mi o závody pakovačů, ale spíše o porovnání těch nejdostupnějších technologií.
Pokud jde o zde zmiňovaný 7zip, tak ten je super, na woknech nic jiného nepoužívám. Ještě doplňuji, že v xz je použita LZMA2 – výchozí komprese 7zip.
Brotli? Ani nevím, proč jsem ho nezařadil. Mrknu na to a něco připravím ;-)
-

Nenašel jsem zmínku o pár věcech, které mohou zamíchat s výsledky. Dva ze tří vzorků se vlezou do RAM. To může znamenat, že se při prvním testu data nacacheují do RAM a pak se budou číst odtud. Což dělá nerovné podmínky – v prvním testu se může více projevit I/O. Správně by IMHO bylo před každým případě (i prvním) testem flushnout všechny cache ( https://www.tecmint.com/clear-ram-memory-cache-buffer-and-swap-space-on-linux/ ), aby podmínky byly rovné. Nebo naopak by šlo udělat každý test dvakrát a vzít druhý výsledek. Jinak může mít na výsledky vliv pořadí provádění testů, jestli se mezi testy restartuje počítač atd.
-
Tak určitě :-)
Máte pocit, že je to na 'gzip -c1' poznat? Není. To proto, že vzorek byl těsně předtím připraven, takže už v keši byl. A i kdyby ne - vadí tak moc, že je jedno ze skoro padesáti měření nějak ovlivněné? :-)
Programy šly po sobě gzip -c1, gzip -c2, gzip -c3 ..... bzip2 -c0, bzip2 -c1 – nic zajímavého, počítač běžel v tahu několik dní.Pokud jde o dvě měření - ring je volný :-) :-)
-
Jak už někteří psali, implementace používající paralelní kompresi jsou výrazně rychlejší. Můj výběr pro různé situace na základě vlastních testů:
- pokud je potreba rychlost: pzstd (deb balik zstdc)
- pokud je potreba gzip standard a rychlost: pigz
- pokud je potreba velka komprese: lbzip2
- pokud je potreba hodne velka komprese: pixzDobré srovnání je taky tady: https://hannuhartikainen.fi/blog/everyday-compression-tool/
A nakonec jedno smutné oznámení. Toto je můj poslední příspěvek na root.cz, dokud tu bude Google reCaptcha. Asi 7 obrázků a pak Verification expired (začal jsem psát příspěvek až po testu captcha, protože se mi nechtělo věřit, že jste sem tu zrůdnost fakt dali pro přihlášené uživatele).
-
Multi-thread implementace jsou super, ale já jsem rád, že benchmark testuje pouze single thread. S výjimkou laptopu dedikovaného na jeden úkol v daném čase (což je pravda zrovna případ tohoto článku) se komprese používá pro mnoho jiných účelů, které už paralelizované jsou (HTTP server, různé proudové zpracování dat atd). Tam by další paralelizace byla kontraproduktivní.
Prakticky každý dnešní kompresor má paralelní alternativu, která zrychluje téměř lineárně a přidává zhruba procento navíc. S tou lineárností je to pravda trochu diskutabilní, Xz třeba v závislosti na úrovni komprese potřebuje mnoho dat, aby naplnil buffery pro jednotlivé thready, poslední blok zpracovává pouze jeden thread.
-
Adam KaliszStříbrný podporovatel
Díky moc za tento článek. Zrovna se mi hodil při hledání iniciálních hodnot pro testování komprese pro backupy OrgPadu.com, které chceme dělat efektivněji, jak nám přibývají uživatelé.
Dosud jsme dělali poměrně stupidně backupy v principu pomocí pg_dump | gzip a backup server si to tahal z produkce, kde se udržovala kopie. Teď se zajímáme o Borg Backup, který nám efektivitu backupu zvýši více než 10x co se týče náročnosti na úložný prostor. Budeme asi používat zstd na úrovni 11, což je rychlé a poměrně efektivní, zdá se. Mám několik dní archivů vždy po 15 minutách zkomprimované pomocí defaultního gzipu. To dá dohromady ca. 16 GB dat. Když to celé nasypu do borg backupu (pomocí zcat | borg), tak se standardním nastavením tvrdí:
Original size Compressed size Deduplicated size All archives: 97.85 GB 27.60 GB 2.14 GB Unique chunks Total chunks Chunk index: 2513 39499Test ještě není hotový, ale podle dosavadních dat to vypadá, že zstd na úrovni 11 uspoří ca. 50% místa oproti lz4. Upřímně nepozoruji výrazné zpomalení (zhruba 10-15%), rozhodně ne takové, aby mě to trápilo a měl jsem potřebu to hlouběji studovat.























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU