Ujorm3: nový lehký ORM pro JavaBeans a Records
Udělej tu nejjednodušší věc, která může fungovat.
—Kent Beck, tvůrce extrémního programování a průkopník vývoje řízeného testy.
Domnívám se, že architekti jazyka Java neměli zrovna šťastnou ruku při návrhu API původní knihovny JDBC pro práci s databází. V důsledku toho v ekosystému Javy vyrostlo značné množství nejrůznějších knihoven a frameworků, které se liší svým přístupem, mírou složitosti a kvalitou. Rád bych vám tady představil zcela novou lehkou ORM knihovnu Ujorm3, o které se domnívám, že poráží své konkurenty svojí jednoduchostí, transparentním chováním a nízkou režií. Cílem tohoto projektu je nabídnout spolehlivý, bezpečný, efektivní a snadno pochopitelný nástroj pro práci s relačními databázemi bez skryté magie a složitých abstrakcí, které často komplikují ladění i výkon. V centrálním repozitáři Maven je nyní k dispozici první release candidate (RC1), uvolněný pod svobodnou licencí Apache License 2.0.
Knihovna staví na známých principech JDBC, ale přidává nad ně tenkou vrstvu přívětivého API. Pracuje s čistými, bezstavovými objekty a nativním SQL, takže vývojář má plnou kontrolu nad tím, co se v databázi skutečně provádí. Ujorm3 se záměrně vyhýbá implementaci dialektů a používá raději nativní SQL doplněné o typově bezpečné nástroje pro mapování databázových výsledků na Java objekty. Do mezipaměti si neukládá výsledky žádných uživatelských dotazů. Pro dosažení maximální rychlosti si však Ujorm3 uchovává některá metadata.
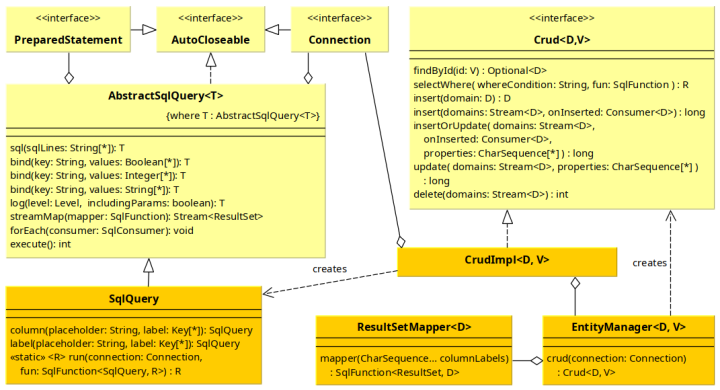
Třídy aplikačního rozhraní
Základní třídou pro práci s databází je SqlQuery (původní název SqlParamBuilder), která funguje jako fasáda nad PreparedStatement. Objekt podporuje pojmenované parametry SQL příkazů, eliminuje kontrolované výjimky a výsledek operace SELECT poskytuje jako efektivní Stream. Mapování dat z ResultSet do doménových objektů pak zajišťuje samostatná třída zvaná ResultSetMapper. Její instance si při prvním použití připraví mapovací model a následně jej opakovaně využívá, což výrazně snižuje režii při zpracování velkého množství dotazů.
Mapování atributů třídy na databázové sloupce lze upřesnit anotacemi z balíčku jakarta.persistence ( @Table, @Column, @Id), knihovna si však dokáže některé vlastnosti odvodit i bez nich. Plně podporovány jsou jak mutable objekty typu JavaBeans, tak immutable Records. Ujorm3 pracuje pouze s relacemi typu M:1 – kolekce 1:M záměrně chybí, aby se předešlo generování skrytých dotazů a problémům typu N+1. Relační sloupce příkazu SELECT lze mapovat pomocí jejich jmenovek ve formátu "city.name", které obsahují tečkou řetězený seznam Java atributů doménových objektů. Lepší je však použít typově bezpečný metamodel.
Automaticky generované třídy Meta* umožňují bezpečné mapování sloupců bez použití textových řetězců náchylných k překlepům. Použití příkazu SELECT pak může vypadat například takto:
static final ResultSetMapper<Employee> EMPLOYEE_MAPPER =
ResultSetMapper.of(Employee.class); void select() { var sql = """ SELECT ${COLUMNS} FROM employee e JOIN city c ON c.id = e.city_id LEFT JOIN employee b ON b.id = e.boss_id WHERE e.id > :employeeId """; var employees = SqlQuery.run(connection(), query -> query .sql(sql) .column("e.id", MetaEmployee.id) .column("e.name", MetaEmployee.name) .column("c.name", MetaEmployee.city, MetaCity.name) .column("c.country_code", MetaEmployee.city, MetaCity.countryCode) .column("b.name", MetaEmployee.boss, MetaEmployee.name) .bind("employeeId", 0L) .streamMap(EMPLOYEE_MAPPER.mapper()) .toList()); }
Všimněte si, prosím, že doménovou třídu není třeba předem nikde registrovat. Pro efektivní práci však doporučuji vytvořit si statický mapper, jehož implementace je připravena na vícevláknový přístup. Metoda column() doplňuje do SQL šablony databázový sloupec se jmenovkou na pozici zástupné značky ${COLUMNS}. Podporována je také alternativní metoda label(), která umožňuje explicitně deklarovat pouze jmenovky sloupců a tím zachovat SQL dotaz v Java kódu blíže nativnímu zápisu. Oba přístupy však nelze kombinovat v jednom dotazu.
Pro práci s entitami slouží EntityManager, který prostřednictvím objektu typu Crud poskytuje jednoduché CRUD operace – včetně dávkových příkazů. Zajímavostí je možnost částečných aktualizací – vývojář může určit výčet sloupců, které se mají aktualizovat, nebo knihovně předat původní objekt, ze kterého si změny odvodí sama.
Zmíněné třídy znázorňuje zjednodušený diagram tříd. Všechny uvedené metody jsou veřejné:
Výkon
Ujorm3 dosahuje velmi dobrých výsledků v benchmarkových testech, kde je srovnáván s některými populárními ORM knihovnami. K dobrému skóre přispívá také mechanismus zápisu hodnot do doménových objektů. Namísto tradičního přístupu pomocí Java reflexe si knihovna za běhu generuje a kompiluje vlastní třídy. Takový přístup obecně snižuje paměťové nároky, minimalizuje režii a šetří práci Garbage Collectoru. Knihovna nemá žádné závislosti na externích knihovnách a zkompilovaný modul s benchmarky (včetně samotné knihovny Ujorm3) má méně než 3 MB, což je výhodné pro mikroslužby i embedded prostředí. Je však dobré mít na paměti, že v produkčním prostředí, ve spojení s pomalejšími databázemi, se rozdíly ve výkonu mohou částečně stírat.
Jak začít
Pro vyzkoušení knihovny ve vašem projektu s Javou 17+ stačí přidat závislost do konfigurace Mavenu:
<dependency> <groupId>org.ujorm</groupId> <artifactId>ujorm-orm</artifactId> <version>3.0.0-RC1</version> </dependency>
Pro automatické generování tříd metamodelu přidejte do elementubuild nepovinnou APT konfiguraci:
<plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.14.1</version> <configuration> <annotationProcessorPaths> <path> <groupId>org.ujorm</groupId> <artifactId>ujorm-meta-processor</artifactId> <version>3.0.0-RC1</version> </path> </annotationProcessorPaths> </configuration> </plugin> </plugins>
Jako předlohu pro vzorovou implementaci lze využít modul Ujorm z projektu Benchmark.
Kód knihovny je aktuálně pokrytý JUnit testy, které využívají (kromě mockovaných objektů) databázi H2 v režimu in-memory. Před vydáním finální verze plánuji doplnit ještě integrační testy pro databáze PostgreSQL, MySQL, Oracle a MS SQL Server.
Kdy zvolit knihovnu Ujorm3?
Pokud pracujete pro korporátního zákazníka očekávajícího standardy nebo přenositelnost abstrakcí mezi databázemi, použijte raději JPA/Hibernate. Pokud jste již našli ORM framework, který naplňuje vaše očekávání a potřeby, zůstaňte u něj. Pokud však hledáte rychlou a transparentní alternativu bez skrytých mechanismů pro váš nový projekt, knihovna Ujorm3 rozhodně stojí za vyzkoušení.
Internetové odkazy:
Doplněno dne 2026–03–24: v centrálním repozitáři Maven je dostupná verze 3.0.0-RC2 s integračními testy pro 5 databází: PostgreSQL, MySQL, MariaDB, Oracle, MS SQLServer.
-

Bolo by nejaké porovnanie s JOOQ, či QueryDSL poruke? To mi príde viac porovnateľné, ako s JPA implementáciami... Alebo spring-data. Ten má imho používanie rovnako jednoduché ako táto knižnica.
Vrámci porovnania sú (pre mňa, ako programátora) dôležité aj jednoduchosť, nielen výkon
Prípadne do squirrel-sql existoval plugin, ktorý z DB tabuliek vedel generovať pekné POJO s metódou, ktorá vedela parsovať dáta z resultsetu z jdbc... To bolo ale ešte menej, ako táto knižica. Teda, asi porovnanie s tímto by nemalo zmysel.
V každom prípade pekné a použiteľne vypadajúce. Ďakujem za info.
-

Je pravda, že QueryDSL SQL je architektonicky frameworku Ujorm3 podobný. Obě knihovny obcházejí komplexní standard JPA, operují těsně nad úrovní JDBC a využívají silnou typovou kontrolu nad databázovým schématem. Rozdíl spočívá v jejich primárním zaměření. QueryDSL SQL exceluje v typové bezpečnosti a umožňuje sestavování složitých dotazů čistě přes Java API. Ujorm3 naproti tomu maximalizuje propustnost a minimalizuje paměťovou alokaci (tlak na Garbage Collector), čehož dosahuje (mimo jiné) delegováním složitějších relačních dotazů s JOINy na nativní SQL.
Zvolená architektura se odráží v naměřeném výkonu. Jak ukazují výsledky doplněného benchmarku, Ujorm3 je při hromadném zápisu (Batch Insert) téměř čtyřikrát rychlejší a generuje zhruba čtvrtinovou zátěž na paměť ve srovnání s QueryDSL. Výrazný náskok Ujorm3 se potvrzuje i při dynamické aktualizaci dat (Random Update), kde QueryDSL vyžaduje více než dvojnásobný čas i paměťovou alokaci. Při čtení dat s relacemi (Read With Relations) dosahují obě knihovny srovnatelných výsledků, přičemž Ujorm3 zůstává mírně rychlejší a úspornější.
Z pohledu programátorské ergonomie Ujorm3 zásadně redukuje množství opakujícího se rutinního kódu. Na rozdíl od QueryDSL SQL, kde se každý příkaz musí explicitně sestavit (včetně ručního výběru sloupců pro částečný UPDATE), poskytuje Ujorm3 vestavěné CRUD operace a automatickou detekci změn (dirty checking) pomocí snapshotů entit. Zatímco QueryDSL SQL nabízí vývojáři stoprocentní kontrolu nad strukturou dotazu přímo v Javě bez psaní textových řetězců, Ujorm3 přináší vyšší produktivitu a hardwarovou efektivitu při běžných databázových operacích.





















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU