Orchestrace ETL pipeline v Pythonu
Jako konzultant v oblasti datového inženýrství a datové integrace jsem měl možnost pracovat na mnoha projektech pro rozličné klienty. Zadání velmi často spočívalo ve vytvoření tzv. datové pipeliny, která extrahuje data ze zdrojových systémů a následně je nahrává do cílové databáze. Samozřejmou součástí zpracování dat je transformace a čištění dat, případně obohacování o další zdroje. Zpracovaná data se mohou využívat pro reporting nebo slouží jako základ pro práci data scientistů. Až na pár vyjímek jsem využíval Python v kombinaci s SQL. Hotový kód jsem zabalil do Dockeru a o vše ostatní se postarali kolegové z DevOps oddělení.
Takové řešení funguje skvěle pokud má klient dostatečně zkušené zaměstannce, kteří jsou schopni provozovat Docker images a řešit nasazování nových verzí. Prakticky tak přechází velká část odpovědnosti za údržbu a provoz dodaného pipeliny na stranu klienta. Dodané ETL řešení si žije vlastním životem. V případě, že nastane nějaký problém, je dost složité od klienta získat dostatek informací pro opravu. Řešil jsem, jak tomu předejít.
Jako první se nabízel produkt Apache Airflow, se kterým jsem se již za svou kariéru setkal. Výborně řeší orchestraci ETL, ale pro mé účely nebyl ideální. Nedávno jsem narazil na open source projekt Prefect, který splnil veškeré mé požadavky nástroje na orchestraci, plánování, ruční spouštění, logování a alerting datových pipeline. Nabízí i možnost zpřístupnění informací o průběhu skriptů klientovi přes webové rozhraní. Společné pro oba nástroje je používání DAG (Directed Acyclic Graph) pro vizualizaci jednotlivých částí ETL porcesu. Oproti Apache Aiflow je nasazení Prefect o dost jednodušší a účící křivka práce s tímto nástrojem je mnohem strmější.
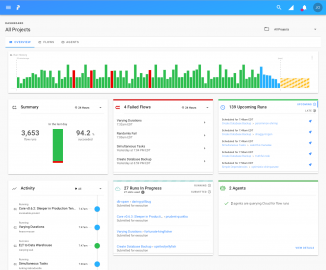
Rozhraní služby Prefect, kde je možné vidět informace o průbězích ETL pipeline
Pro implementaci Prefect do stávajících pipeline stačí importovat baliček do Python skriptu a přidat pár řádků kódu. Tento článek má sloužit pouze jako představení, samotné příklady kódu někdy příště. Další výhodou je, že rozhraní, ve kterém máte přehled o všech bězích pipeline, je na webu samotné služby. Je však možné si ho nainstalovat i na svou infrastrukturu.
To nejlepší jsem si nechal na závěr. Prefect je stavěný na heterogenní prostředí. ETL skripty, které orchestruje, mohou běžet na klientově nebo vlastní infrastruktuře, případně někde v cloudu. Všechno je možné zkombinovat. Python skripty se ani memusí zabalit do Docker image, ale nic tomu nebrání. Prefect je možné provozovat i v kombinaci s Kubernetes. Možností je spousta, stačí sepřesvědčit na webu služby.
Žádné názory
