Routování? Ano, ale jinak
Vítám vás u dalšího článku, tentokrát téměř čistě textováho. Video bude, ale jen krátké – pro názornost.
V textu bych rád rozebral problematiku takzvaného routování a důvody, proč to PHP Jet dělá zcela odlišně než ostatní frameworky. Původně jsem chtěl porovnávat s frameworkem Laravel, ale v našich končinách je známé Nette, tak použiji jako příklad tento framework. Ostatně základní koncepce je u ostatních frameworků stejná. Ano, někde routy pojmenováváte, jinde ne. Někde je definujete na jednom místě, jinde v anotacích kontrolerů (což má své pro, ale i proti). Někde jsou různé grupy rout a tak dále. Ostatní frameworky dělají různě věc která je ve své podstatě ale stejná, tedy sestavení velké sady pravidel pro řízení požadavku.
PHP Jet to dělá jinak a dnes na konkrétních faktech ukážu proč jde jinou cestou a jaké jsou k tomu objektivně dobré a měřitelné důvody.
Co požadujeme od webové aplikace? Zejména od té v PHP?
Nejprve malý obecný úvod a obecné technické předpoklady.
Od webové aplikace požadujeme (mimo jiné) rychlost a výkonnost – hodně obsloužených požadavků za minimální čas a spotřebu prostředků serveru. Je to jeden ze základních klíčových požadavků.
PHP (nejen PHP – samozřejmě) funguje tak, že pro každý HTTP požadavek vše “nabíhá”. Nebudu teď řešit odlišnosti PHP samotného když běží jako CGI, Fast-CGI (FPM), modul Apache a tak dále. Jde o tom, že každý HTTP požadavek znamená spuštění řady věcí a především inicializaci naší aplikace v PHP napsané vždy takřka z bodu 0.
Neřešme teď zda je to dobře nebo špatně. Má to své výhody i nevýhody. O tom by se dalo dlouze diskutovat. Ale prostě to tak je. A pro nás to znamená, že samotný náběh aplikace nesmí být brzda.
Ovšem drtivá většina frameworků (alespoň ty které znám) dělají to, že hned při inicializaci provádí spoustu relativně složitých věcí a routování je jednou z nich. A to si teď rozebereme.
Routování v Nette
Budu vycházet z aktuální dokumentace routování frameworku Nette:
https://doc.nette.org/cs/application/routing
A budu na jednotlivých aspektech ukazovat co je špatně již na samotné koncepci routování.
Nebudu zde suplovat dokumentaci, vysvětlovat to o čem bylo již mnohé napsáno a jakkoliv nosit dříví do lesa. Ale pro pořádek musím uvést, že tato koncepce routování je o kolekci různých pravidel, které konkrétní HTTP požadavek nasměrují na určitý kód, který požadavek obslouží. Ať už je to kontroler, presenter, nebo spousta jiných možností (Laravel). Ta nutnost sestavit sadu pravidel, které je nutné vyhodnotit je společná a je to jádro věci.
Koncepce je to funkční a na určité úlohy určitě dostačující a používána. Ale má řadu úskalí.
Ta úskalí jsou patrná hlavně u velkých projektů v reálné praxi.
Na prezentační web asi může být, ale co dál?
Zkusil jsem si otevřít jeden z projektů a zkusmo určit kolik bych asi tak potřeboval rout. Mluvím o projektu, který zahrnuje desítky různých nástrojů, stovky a stovky uživatelských funkcí … Prostě takový naprosto běžný projekt (bez nadsázky).
Když jsem si spočítal jen akce kontrolerů na které bych musel něco routovat, tak jsem došel řádově ke stovkám. Vyšším stovkám rout … Dokážu si představit i projekt, který se přiblíží k tisícovce, protože tenhle k tomu nemá daleko. Opravdu nic zvláštního.
Ostatně i ta hloupá základní ukázková aplikace, která však zahrnuje vše, včetně administrace, včetně REST API serveru i klienta, včetně testovacích modulů, … se kterou je PHP Jet distribuován – tu si můžete prohlédnou sami. Zkuste si pro ni sestavit kolekci rout. Nebude malá a na vlastní kůži by člověk poznal další podstatná úskalí.
A to je problém … Respektive řada problémů. Pojďme si je rozebrat.
Výkonnost, výkonnost, výkonnost, ….
Tím prostě musím začít a později také skončit. Ať už jsou u routování různé keše a tak dále, tak výkonnost je problém.
Ostatně zde je přesná citace z oné dokumentace Nette:
Výkonnost
Počet rout má vliv na rychlost routeru. Jejich počet by rozhodně neměl přesáhnout několik desítek. Pokud má váš web příliš komplikovanou strukturu URL, můžete si napsat na míru vlastní router.
No a já tu píšu o stovkách rout, ne-li tisícovce …
Při vší úctě k autorům ostatních frameworků (nejen Nette), určitě to jsou inteligentní lidé, ale přece není možné udělat základ webových aplikací takový, který webovou aplikaci od samého začátku a ze samotné podstaty principu brzdí a limituje. Už to samo o sobě je prostě problém a ne varování, ale jasný signál, že se samotnou architekturou je něco špatně.
Psát si vlastní router? Pardon, ale fakt? Taková rada hned na začátku? OK, napíšu si raději rovnou vlastní framework …
TCO – náklady na “učení se”
Systém routování je velice zajímavý, ne že ne. Ale má velmi mnoho aspektů a nuancí a to má vliv na to za jak dlouho si pracovník danou problematiku osvojí a jak efektivně to bude používat.
A jsme opět u toho. Vývoj SW není o psaní kódu, to je jen a pouze jedna část. Vývoj SW je o manažerských rozhodnutích a o neustálém porovnávání nákladů a výnosů. Psát nějaký kód umí i dítě či tak zvaná umělá inteligence. Toto budu opakovat neustále. Kód který píšeme musí dávat celkově smysl, stejně jako celá naše práce.
Tedy: Routování je třeba se naučit, jako všechno. Ale zde se dá předpokládat jistá náročnost … Mám tu něco co se musí člověk učit a s čím může tak trochu zápasit. Co na to křivka učení? Kolik ta legrace bude stát a hlavně co to přinese?
A když budu opět citovat přímo z dokumentace:
Nebudeme před vámi tajit, že správné sestavení rout vyžaduje jistou dovednost. Než do ní proniknete, bude vám užitečným pomocníkemroutovací panel.”
Tak je jasné, že to žádná legrace nebude, bude to drahé. A když na druhou misku vah dám ten fakt, že bude lepší vyvíjet vlastní router, tak mi to nákladově fakt nesedí.
TCO – chybovost, problémy a problémy …
Spousta věcí na jednom místě = spousta problémů …
Vlastně je to středobod aplikace. Ve výchozí situaci na jednom místě (ano, dá se to řešit – ale zde řešíme základní architekturu). Tedy mám tyto otázky:
- A co když na té aplikaci bude pracovat X lidí?
- Jasně že se dají řešit kolize, ale chceme je řešit? Proč si přidělávat problémy?
- Dá se najít vlastní řešení pro separaci. Ale proč už to nemá framework?
- A co deployment pokud kolize nějak nevyřešíme? Co když půlku nových (či upravených) rout chceme poslat do produkce a další ještě ne?
- A co ty absolutní URL v routách (pokud je někdo použije)? Co když ty potřebuji, ale jisto jistě budu mít jiné URL u sebe, jiné na některé z testovacích instancí a jiné na produkci? A to si piště že to tak naprosto běžně je. Ale vlastně nejen ty absolutní URL. Z různých důvodů prostě můžu mít jakékoliv URL jiné na localhostu a jiné na produkci …
Prostě další várka argumentů na misky vah. Věci o kterých vývojář musí přemýšlet, protože … není to jen o psaní kódu, ale o všemožných konsekvencích :-)
Jak takové routy malé aplikace vypadají v praxi? Omlouvám se, ale teď zabloudím k tomu Laravelu, pro něj se mi podařilo nalézt malý příklad.
A to je aplikace velice malého rozsahu. V praxi by toho bylo tak 50× až 100× tolik.
Separace komponent aplikace a přirozená modularita?
Ve své podstatě veškerá žádná. Už samotná koncepce mi nenabízí žádnou možnost jak přirozeně projekt rozdělit na malé samostatné a do značné míry zapouzdřené celky … Musím si to nějak pořešit … A to nemluvím o tom, že mám kontrolery na jednom místě, view na jedné hromadě a tak dále. Separovat z aplikace nějakou funkcionalitu například pro opětovné použití? Práce pro Ferdu Mravence.
Mezinárodní prostředí?
Jasně že i na Nette jdou nějak řešit jazyky a podobně. Například zde kolega ukazuje řešení pomocí persistetních parametrů a také to, jak to vylepšili:
https://www.youtube.com/watch?v=4RydHZRkCl8
Fajn, jenže v době kdy je planeta malá a vše je za rohem se fakt hodí nějaká přirozená řešení, integrovaná do samotné architektury a přímočará, plně funkční. Rovnou s generování URL, možností deaktivace a tak dále. To je problematika sama o sobě, která by měla být vyřešena koncepčně v základu a ne dodatečně.
Prostě a jednoduše …
Tato myšlenka, používaná již hodně dlouho a řadou FW. Jednotlivé implementace se liší v mnoha věcech, ale princip je stále stejný a ten objektivně má řadu úskalí:
- Je to technicky náročné a to již ze své podstaty a při vší snaze to technicky náročné bude. Což je přesně to co na tomto druhu aplikací potřebujeme ze všeho nejméně – přesněji právě to co nechceme.
- Kumuluje to velice důležitou logiku aplikace na jedno místo (Nette, Laravel, …). Velice to znesnadňuje například vývoj v týmu, deployment a tak dále.
- Je to náročné na naučení se a lidskou pozornost. Je to už z principu nepřehledné na projektu normálního rozsahu.
- Už samotná architektura nemyslí na aspekty webu v 21. století – tedy v mezinárodním prostředí.
- Přirozené členění projektu na samostatné celky se nekoná.
Prostě a jednoduše: tudy cesta nevede. Ne ze subjektivních důvodů (ty v technice nejsou rozhodující), ale čistě z důvodů objektivních a měřitelných.
A protože rada zněla udělat si vlastní router, tak jsme si udělal vlastní framework, který na to jde úplně jinak, dalo by se říct z opačného konce.
Routování v PHP Jet
Tak co s tím? Udělat framework možná trochu jinak, ale využívající stejný princip v situaci, kdy je naprosto zřejmé, že problém není ve frameworcích, ale již v samotném návrhu a koncepci? To by nikam nevedlo.
Řešení: Úplně jiný návrh využívající dosavadní pozitivní i negativní zkušenosti ze všemožných projektů.
Hlavní myšlenka: Pojďme to rozkouzkovat! Ostatně třeba takové binární vyhledávání / půlení je bezva algoritmus, tak proč se jím neinspirovat? Myšlenka je taková, že se celé seznamy neprochází od prvního do posledního prvku, ale dělí se na stále menší kousky. Pak je algoritmus daleko efektivnější.
(Poznámka: toto není přesná implementace daného algoritmu, ale pouze využití základní myšlenky že vše velké je dobré dělit na co nejmenší kousky.)
A důležitá věc: Použít Dependency Injection, ale v jeho správné roli a použití.Aplikace potřebuje na jedné straně jasně dané kontejnery na které se může spolehnout (jasně dané rozhraní na jasně daném místě) a na straně druhé během inicializace MVC (tedy aplikace již běží, ale je v mezistavu) je nutné do těchto kontejnerů vložit poskytovatele služeb.
Pokud náhodou ještě nechápete co doopravdy DI je a k čemu je to doopravdy dobré, tak teď už v tom budete mít jasno.
Základ myšlenky
Žádný projekt není jedna aplikace, ale soustava mnoha aplikací.
Pro různé frameworky existují různé ukázkové jednoúčelové aplikace. Například jsem zde porovnával vývoj TODO listu. Jenže v reálném světě žádná webová aplikace není jen ta jedna dílčí část, jen jedna aplikace. Kdyby tomu tak bylo, tak uvedený systém routování bohatě postačuje a byl by i vhodný.
Ovšem ono tomu tak není. Pokud neděláme prostý statický prezentační web, ještě lépe řečeno nějakou micro site či landing page s jepičím životem (na tom není nic špatného a je to také profi práce, kde záleží na grafické vymazlenosti a tak dále, ale u takových projektů možná není třeba ani to PHP), tak potřebujeme minimálně administraci. Ta administrace se skládá z mnoha samostatných aplikací. Dále potřebujeme dynamické stránky (tedy další aplikace) pro všemožné, potřebujeme API, potřebujeme servisní skripty, potřebujeme … no prostě stovky (doslova) věcí.
A co je legrace, tak každá ta část projektu má jiné potřeby. Už přihlašování a autorizace uživatelů bude úplně jiná v zákaznické sekci, v administraci, v REST (či jiném) API a tak dále. Bude jiné UI, bude jiná navigace, bude se jinak operovat s případnými chybami a tak dále … Prostě X různých aplikací s různými nároky a různým chováním v jednom projektu, ale vzájemně propojených.
Ale tam to rozdělení nekončí. I jedna stránka kterou vidí třeba běžný návštěvník je hromada malých aplikací. Stránka sama o sobě tvoří nějaký celek. Ale vždy se skládá z nějakých komponent umístěných na určitých pozicích a různě se chovajících a fakticky jsou to samostatné malinkaté aplikace (jakkoliv spolu mohou / musí vzájemně interagovat a kooperovat).
A každá ta malinká aplikace má svoji logiku, každá má své routování:
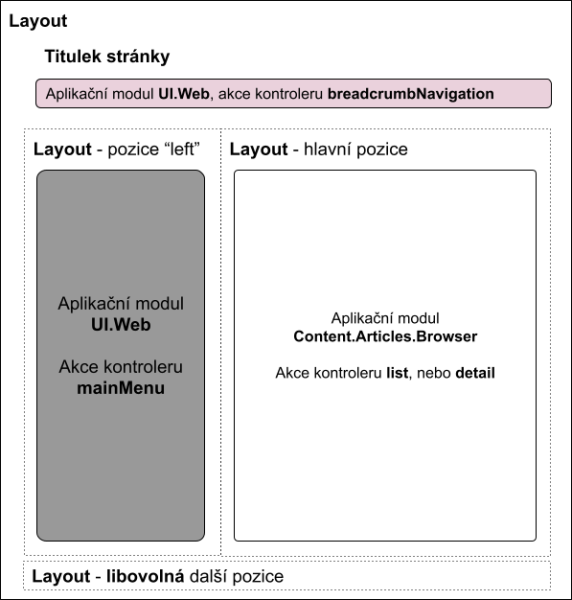
A pochopitelně to vše může mít různé jazykové mutace a celkově vzato nějaké národní prostředí …
Tedy ještě jednou si lze s klidným svědomím zopakovat že tohle vše opravdu nemůže být na jedné hromadě a ani různé skupiny rout tomu prostě nepomůžou. Ale to už bych se opakoval.
Bude lepší to celé rovnou rozkouskovat a rozdělit.
Pozor! Možná se nabízí myšlenka vyvíjet jednotlivé části samostatně. Extra administraci, extra web, extra API a tak dále. Rozdělit to až takto zásadně na jednotlivé subprojekty. Taky jsem si to myslel a mám projekty, kde to tak je. A to také není úplně správná cesta. Proč? Protože můžete mít X modulů, které ale potřebují jednu společnou entitu. Pamatujete na e-shop? Tam byla kategorie a zboží jako společná entita a s tou pak operovalo hned několik modulů v administraci i na webu. Tedy určitě rozdělit. Ale rozhodně nestavět zdi a příkopy. To je značně nepraktické …
Rozdělit … Ale kde? V bázích!
Úplně základní rozdělení je to do jaké hlavní části projektu uživatel “leze”. Chce se přihlásit do administrace? Je to klient API? Je to běžný návštěvník? Je to B2B partner co potřebuje do B2B sekce? Je to pan ředitel firmy, kterého nezajímá komplexní administrace, ale chce si jednoduše prohlížet reporty a má tedy svou mini-administraci? Nebo je to cokoliv dalšího?
Právě zde začíná základní rozdělení! A zde se hned dostaneme k Dependency Injection ;-)
Ale nejprve začneme u slova báze (base). Roky jsem váhal jak to pojmenovat až mě napadlo tohle.
Báze je základní bod aplikace a tedy i routování. Je to základní bod administrace, základní bod veřejného webu, základní bod API, základní bod čehokoliv.
Báze je entita, která má svůj model a dá se s ní pracovat. Báze má své unikátní ID, své jazykové mutace, ty mutace mají své URL (klidně více, jedna je vždy výchozí), parametry a tak dále. A pochopitelně i generuje základní URL.
Báze se neukládá do databáze (i když díky flexibilitě Jetu lze pochopitelně i to zařídit, bylo by to kontraproduktivní – nejlepší SQL dotaz je žádný dotaz). Báze má svůj adresář a svou definici v souboru.
To znamená, že veškeré nastavení je mimo aplikační logiku – mimo aplikační skripty. A tak to má být. To na jaké doméně a URL co poběží je pouze a jen věc nastavení. V PHP skriptech společně s logikou to nemá co dělat. Protože pak to vše tak akorát komplikuje.
Router v PHP Jet jako první udělá to, že si sestaví mapu bází, což je optimalizovaný proces. Zde je rychlost zásadní faktor. Ty mapy mohou být pochopitelně ukládány do keše. Ale zprvu jsou to pouze mapy bází a ne čehokoliv jiného. Seznamy a mapy jsou vždy co nejmenší – to je důležité.
Po sestavení této základní mapy router určí třeba: Ok, tak tohle (tento HTTP požadavek) bude administrace v té a té jazykové mutaci.
A pak systém udělá důležitý krok. Zavolá inicializátor báze. V tento moment dojde k donastavení systému za běhu. Do kontejnerů využívaných aplikací jsou vloženy poskytovatelé služeb. Co je poskytovatel služeb? To je například konkrétní instance konkrétního auth kontroleru. Od tohoto momentu autentizační a autorizační subsystém ví co konkrétně je poskytovatelem služby a co (jaká instance jaké třídy) bude skutečně řídit celou logiku autentizace a autorizace. S tím, že kontejner má pro aplikaci jasně dané rozhraní, ale až do tohoto momentu je prázdný. A pochopitelně každý subsystém má svůj k tomu určený kontejner. Nemotáme přece hrušky a jablka, stejně tak jako nechceme tvořit mísy špaget … To je celé kouzlo a podstata DI, bez kterého by Jet nefungoval.
Onen inicializátor báze (prostě nějaká k tomu určená metoda) pochopitelně není součástí frameworku, ale aplikačního prostoru – skriptů v kompetenci vývojáře. Definice báze zahrnuje určení co má za inicializátor považovat (jakou metodu jaké třídy – to je čistě na programátorovi). Tedy jak přesně si programátor připraví prostředí pro danou část projektu je už čistě a jen na něm. V ukázkové aplikaci jsou pochopitelně i ukázkové inicializátory a to hned 3.
Bází může být tolik kolik potřebujete. Tedy projekt může mít klidně ony dvě administrace, každou s jiným UI, ale sdílející aplikační moduly (respektive třeba pouze jejich část – pouze některé). Nebo můžete mít víc API, více webů (třeba jeden pro B2B, druhý pro B2C a podobně) v rámci jednoho projektu, prostě cokoliv. A vše stále může sdílet kód a uživatelské funkce. To je velice důležité. Co modul / mikro aplikaci můžete použít třeba 100× na jednom projektu, na různých místech. Nehledě na to, že ji snadno separujete a přenesete na další projekt. Ale to jsem moc odbočil od bází. Zpět k tématu.
Tedy zde již máme hotové první rozdělení … Jasně že pak router bude muset “makat” dál, ale už je jasné, že množina informací které bude muset zpracovat se omezí na nutné minimum. V tento moment je jasné, že routy pro web, či REST API, či cokoliv dalšího již router vůbec nemusí zajímat, protože ví, že relevantní jsou například pouze routy pro administraci.
A teď stránky …
Router teď musí zjistit na jakou stránku uživatel kouká. Pochopitelně na základě nějaké “hezké URL”. Ovšem router už ví, že nemusí prohledávat vše, ale pouze stránky z báze XY (třeba webu) v mutaci např. cs_CZ.
Stránka je stejně jako báze entita. Logicky spadá pod bázi a její jazykovou mutaci a stejně jako báze i stránka má nejen ID a URL, ale celou řadu dalších užitečných informací, které její definice může obsahovat a může tak sloužit například pro navigaci a další užitečné věci.
Stejně jako báze je i stránka uložena jako definice ve svém adresáři. Co adresář a podadresář a další podadresář (a tak dále), to stránka. S adresáři lze jednoduše manipulovat a tím měnit strukturu webu – naprosto jednoduše a přirozeně, bez zásahu do aplikace.
Stejně jako báze i stránky mohou být upraveny pro ukládání do databáze (architektura Jetu ničemu nebrání) bez jakýchkoliv úprav aplikací samotných. Pomocí dědičnosti, přetěžování a továren si můžete vyměnit i stránky. Proč ne …
Zpět k tomu co dělá router. Ten si opět sestaví jednoduchou mapu stránek. Opět realizováno tak, aby proces byl co nejrychlejší i bez keše a bleskový s použitím keše.
Ostatně v závěru článku si ukážeme web, který má více jak tisíc stránek.
Když router zjistí o jakou stránku se jedná tak má takřka hotovo a přijde ke slovu něco, co připomíná routování z frameworků starší generace.
Tedy stránka je známá a …
Teď přichází na řadu aplikační moduly
Pro jednoduchost teď nechám stranou fakt, že stránka může být třeba celá statická a není třeba už nic řešit a lze rovnou ven poslat obsah a další možnosti stránek (ve skutečnosti je několik metod jak stránku “obsloužit”). V praxi takto můžete poskládat takřka plně statický web pouze s pár dynamickými prvky. Ale to je námět na další článek :-) Teď zpět k tématu.
Nejčastější situace je ta, že stránku generuje několik aplikačních modulů – což jsou fakticky mikro aplikace.
Seznam těchto mikro aplikací je buď dán definicí stránky samotné (již jste několikrát viděli jak to klikám v Jet Studiu, ale jde to dělat i ručně, stejně tak jako přes API entity stránka), nebo je možné pověsit tyto mikro aplikace to layoutu stránky (také jste viděli ve videích).
Mimochodem layout stránky je také view skript, ale postará se i to, aby byl vystup ze všech těch mikro aplikaci / aplikačních modulů poskládán do finálního výstupu.
Fajn, ale pokud jste pozorně sledovali videa o tvorbě e-shopu, nebo studovali ukázkovou aplikaci, tak víte, že třeba detail produktu na e-shopu může mít svou vlastní URL, to samé článek a tak dále. Nebo je třeba vyhodnocovat GET parametry. Či požadavky REST (tedy i HTTP metody jako je DELETE, PUT a tak dále). Nelze modul prostě jen plácnout na stránku, modul musí měnit své chování na základě okolností.
Tyto mikro aplikace již musí umět routovat. To je jasná věc!
Routování v rámci modulů
Ještě než PHP Jet začne “spouštět” jednotlivé aplikační moduly, tak je požádá ať si “zaroutují”. Ať si každá z těch mikro aplikací vyhodnotí celkový stav a sama si určí jaká akce jakého kontroleru bude ve skutečnosti volána (pochopitelně pokud modul něco takového vůbec potřebuje dělat – což není pravidlem).
Poznámka: Při tomto procesu může nastat i to, že URL je vyhodnocena jako neplatná, nebo že je nutné přihlášení uživatele, nebo že uživatel leze kam nemá … S tím Jet hodně pomáhá, ale teď to nekomplikujme.
Tedy systém udělá to, že připraví instance kontrolerů aplikačních modulů a požádá je o vyřešení situace: zavolá metodu resolve() : bool|string (tu si mimochodem můžete přetěžovat jak libo).
Tato metoda se zkusí zjistit, zda si kontroler sestavuje svůj mikrorouter a ten případně použije. Nebo může implementovat jinou vhodnou logiku – opakuji, můžete to přetížit. Ale teď se koukneme na ten mikrorouter.
Mikrorouter
Mikrorouter kontroleru je již trochu podobný tomu co možná znáte z jiných FW. Vlastně ne … Dělá totéž, ale úplně opačně :-)
U mě známých FW je to tak, že se definují požadované parametry HTTP požadavku, které musí být pro danou routu splněny.
Tohle v Jet není. V mikrorouteru se definuje nejprve akce – název jedné z akcí daného kontroleru. A k této akci se definuje resolver. Což je logika (v praxi v podobě anonymní funkce), která rozhodne o tom, zda je daná akce právě tou relevantní, která se má vykonat.
Proč to tak je? No protože podoba HTTP požadavku je sice fajn, ale zdaleka to není dostačující v reálné praxi. Za URL báze a stránky zpracované hlavním routerem může být ještě kus URL (cesta), která má reprezentovat například detail produktu (viz videa o tvorbě e-shopu).
No jo, ale co když se URL produktu změnila a je třeba přesměrovávat? Nebo je již zcela neplatná? Nebo produkt již není v nabídce, ale má se zobrazit info o této skutečnosti (a nabídnout podobné produkty – další ze stovek funkcí … jen pro dokreslení) ?
Aby kontroler věděl, že má volat opravdu akci reprezentující zobrazení detailu produktu (například), tak musí vědět, že daná URL opravdu představuje konkrétní produkt a že ten je aktivní. Jinak má přijít ke slovu akce zobrazující neaktivní produkt, nebo 404 (což umí vyřešit Jet sám), či přesměrování (také umí Jet sám) a tak dále.
Jde o to, aby akce kontroleru řešila pouze to co spadá do její kompetence a nedocházelo k duplikování či fragmentaci logiky.
Ostatně i GET, POST a DELETE požadavky v REST API také potřebují vyhodnotit zda daný objekt se kterým chce klient operovat vůbec existuje. Tak by se dalo dlouze pokračovat …
Tedy routování je o vyhodnocení více aspektů, nejen podoby HTTP požadavku – to je praxe. A proto to PHP Jet dělá jak to dělám.
Mikrorouter nejen routuje, ale je celkově užitečný
Mimochodem … Akce onoho mikrorouteru jsou samozřejmě reprezentovány instancemi příslušné třídy. Ale to není tak zajímavé samo o sobě.
Zajímavé je to, že si tedy můžete akce z routeru vytáhnout a použít pro generování URL na danou akci, či dokonce k ověření oprávnění aktuálního uživatele k zavolání dané akce a modle toho např. modifikovat UI.
S tímto mikrorouterem a jeho akcemi tedy můžete dál operovat, generovat URL, omezovat prvky UI dle oprávnění přihlášeného uživatele a tak dále. Ale logiku k tomu všemu máte na jednom místě jednoho modulu. Na jednom místě, které můžete kdykoliv upravit aniž by se aplikace “rozbila”. Ovšem to jedno místo se týká jen a pouze jednoho konkrétního modulu, jedné konkrétní dílčí části projektu, jedné mikro aplikace. Nemotá se to dohromady s čímkoliv jiným.
Shrnutí
Ano, mikrorouter kontrolerů v rámci modulů je již podobný jiným FW. Teda až na tu obrácenou logiku resolveru a na ten zásadní rozdíl, že PHP Jet už ze své podstaty vyhodnotí jen a pouze ty routy, které jsou potenciálně relevantní a všechny routy celé aplikace (lépe řečeno celého projektu) nejsou na jednom místě, ale jsou vždy v té části projektu ke které patří.
To má obrovský dopad na výkon. Mějte rout kolik potřebujete. Jasně že to není perpetum-mobile. Ale je to dostatečně rychlé na to, aby vás to v rámci reálných aplikací jakkoliv neomezovalo.
A to ostatní? Přehlednost, organizace práce, jasné rozdělení, znouvupoužitelnost, testovatelnost … Není to více jak zřejmé?
Když má modul pro správu článků (například) své routy u sebe, tak je to jednoznačně lepší než když jsou kdesi na jedné hromadě s úplně cizí logikou.
Prostě: Upravíte modul X, víte kde modul X co má. A nasazujete také modul X. A nepletete se do cesty kolegovi, co řeší modul Y.
Nebo vezmete modul X z projektu A a použijete jej na projektu B.
A taková maličkost jako bonus. Modul X můžete nasadit třeba na 10 různých stránek, pokaždé s jinou URL. A ono to bude dělat co dělat má (pokud jsou dodrženy jednoduché principy).
Spousta lidí tyto problémy má a hledá řešení. Tady to máte. Naservírované na podnose, hotové a připravené.
A ve své podstatě je to velice jednoduché až naprosto primitivní a zcela přirozené.
Důkaz místo slibů
Opakuji a stále budu opakovat: svět techniky není o dojmech a pocitech, ale o faktech, hypotézách a jejich následném měření, ověřování a důkazech a rovněž i o porovnávání. Ostatně věřím, že tohle je základ každého technického vzdělání.
Tedy když vám zde něco vyprávím, tak musím být schopen dokázat, že mám pravdu, nebo alespoň jasně ukázat na základě čeho si myslím že mám pravdu (plést se mohu vždy, ale nesmím argumentovat dojmy …).
Za nás techniky hovoří univerzální jazyk vesmíru: čísla – reprezentující fakta. Ověřitelná a dokazatelná čísla. A diskutovat o číslech (ať reprezentují cokoliv), o tom jak a proč jsme jich dosáhli, nebo jak jsme je ověřili, o tom všem již diskutovat cenu má – ba naopak o tom se diskutovat musí a musíme tak hledat jak věci dělat lépe na základě čísel – i v PHP.
(Poznámka: Pokud se třeba s Honzou bavíme v našem oblíbeném baru o tom jaká byla párty, tak jasně že je to o pocitech a dojmech. Jasně že dojmy jsou důležitý pro každého člověka, jsou podstatou naší duše, ale práce je práce a naše práce je postavena na číslech.)
Tak si pojďme udělat regulérní (i když malý a stručný) technický rozbor, alespoň stručný. Hurá na čísla!
Co bude ověřeno?
Jet MVC řeší následující problémy:
- Přirozenou izolovanost jednotlivých komponent aplikace, tím usnadnění zejména týmové práce a údržby aplikace během provozu a životního cyklu, organizaci práce, deployment a tak dále. Stejně tak jako znovupoužitelnost kódu a podobně.
- Jednoznačnou separaci nastavení (na jaké URL co poběží) od aplikační logiky a skriptů aplikace samotných. Základní URL jsou zcela mimo aplikaci a její logiky. Je to nastavení, navíc značně proměnlivé nastavení (localhost, test, produkce, …), přímo v aplikaci (jejím kódy) to nemá co dělat.
- Správně použití Dependency Injection. Tedy nastavení závislostí dle situace za běhu aplikace. K tomu tento koncept slouží.
- Podporu vícejazyčnosti a mezinárodního prostředí.
- Otázky výkonu.
Body 1 a 2 lze také ještě více rozebrat a udělat případové studie, ale asi by to nebylo tak zajímavé.
Bod 3 už jsem rozebíral mnohokrát …
Bod 4 je prostá jasná věc a velice užitečný aspekt celé koncepce, ale v pro tento text nic technicky zajímavého. Ovšem vrátím se k tomu v budoucnosti.
Pro teď se zaměřme na 5. bod – výkonnost aplikace. To je z čistě technického hlediska nejzajímavější.
Otázka výkonu – kde lze předpokládat úzké hrdlo?
Poznámka: Úplně správné by bylo všechny následné hypotézy ověřit pokusy a měřením. Ale to už by nebyl článek, ale kniha. Tedy v rámci stručnosti se zaměřím jen na to nejzajímavější.
PHP Jet dělí proces routování na tři kroky, čímž přirozeně snižuje počet potřebných vyhodnocení:
- Určení báze a lokalizace
- Určení stránky
- Routování v rámci mikro-aplikací na stránce
K jednotlivým krokům:
Určení báze (1. krok) by v praxi měl být vždy zcela bezproblémové. V reálné praxi se počet bází bude pohybovat v jednotkách. Jedná se tedy pouze o sestavení velice jednoduché mapy z jednotek definičních souborů.
V praxi je sestavování mapy několik I/O operací, v případě použití keše na produkčním prostředí jde o pouhé načtení primitivní mapy z keše (jednoduchá I/O operace dle použitého backendu keše + spotřeba paměti)
Lze předpokládat, že ani hypotetický větší počet bází by neznamenal problém, protože princip je podobný stránkám, kde si provedeme ověření na více jak tisícovce stránek (viz dále).
Určení stránek (2. krok) již problém být může. V praxi jsem se opakovaně setkal s rozsáhlými web majícími stovky stránek. Je tedy nutné ověřit chování systému při počtu o řád výše. Tedy test provedeme s velkým počtem stránek.
Routování v rámci mikro aplikací (3. krok): V praxi jsou na stránce umístěni jednotky aplikačních modulů, maximálně nízké desítky. Navíc v situaci, kdy ne každý modul potřebuje routování. Tedy rout aplikačních modulů bude v reálné praxi existovat maximálně desítky, což v principu nepředstavuje problém žádný – z pohledu FW.
Ovšem rychlost vyhodnocení závisí plně na optimalizaci jednotlivých vyhodnocovacích funkcí / resolverů. Je to tedy plně pod kontrolou a v kompetenci a zodpovědnosti vývojáře aplikace. Framework jako takový má při této operaci fakticky zanedbatelnou režii.
Chování při velkém množství stránek
Cílem testu je porovnat následující chování:
- Aplikace s běžným počtem stránek, se studenou keší
- Totéž se zahřátou keší
- Aplikace s dodatečným vygenerováním tisíce stránek s desetistupňovou úrovní zanoření
- Totéž se zahřátou keší
Očekávané výsledky:
- Běžná struktura webu se studenou keší: čas i spotřebované strojové prostředky na úrovni vhodné i pro běžný provoz
- Běžná struktura webu se zahřátou keší: velice nízký čas běhu i spotřebované prostředky
- Extrémní struktura webu se studenou keší: přijatelný čas i použité prostředky, zcela bez extrémních hodnot. Bezpečně nasaditelné i na provoz (zahřátí keše nezpůsobí komplikace), zcela dostatečné pro vývoj (s vypnutou keší).
- Extrémní struktura webu se zahřátou keší: hodnoty velice podobné hodnotám webu s běžnou strukturou, pouze mírně horší. Zcela bezpečné pro provoz.
Podmínky pro test:
- PHP 8.2.4, Apache 2.4.54, databáze pro test: žádná (Jet se ani nepřipojí pokud opravdu nemusí), CPU i7–8550U, 16GB RAM, SSD
- Čistá instalace PHP Jet
- Přepnutí z vývojářského režimu do režimu produkčního ve kterém jsou již aktivní keše.
- Zapnutí Jet profileru (to má negativní vliv na výkon, ale pro všechny testy +/- stejný a malý), nutné pro ověření chování.
Na průběh tohoto jednoduchého testu se koukněte v tomto videu. Mimochodem uvidíte praktické použití Jet Profileru:
Výsledek: Teorie je pravdivá. Systém se chová tak že je dostatečně rychlý i při extrémní struktuře webu a v běžném provozu za podmínek zahřáté keše je oproti standardní struktuře pouze nepatrně náročnější.
A to je pro dnešek vše.
No a já se ozvu zase za týden či dva. Námětů mám plno :-)
Mějte se krásně!
-

Přesně :-D Tenhle framework je na můj vkus opravdu dost zvláštní, i když samozřejmě smekám před autorem, že něco takového sestavil. Ale nepřesvědčil mě. K ukázce routování: pokud bych se dostal do bodu, kdy budu potřebovat namapovat víc než přehledné množství URI, pak je v mém konceptu něco přece špatně a měl bych to celé předělat. Používat 100 nebo 1000 rout? To přece nedává smysl, to se takhle nemůže dělat. Pokud potřebuju obsluhovat 100 různých uživatelských requestů, tak si napíšu nějaký controller.php a budu to dělat celé jinak a efektivněji skrze POST requesty a nějakou mapu. Nebo to celé chápu špatně?
-

Jen jsem si to přečetl, abych se podíval, jak se to dělá jinde. Já mám v C++ napsaný server, kde zaregistruju cestu-prefix a handler. Když se objeví v URL cesta, která prefixu handleru, zavolá se handler, ten dostane zbytek cesty. Pokud ji nechce (prozkoumá request a zjistí, že ho nechce), pak to ukončí a server najde nějaký kratší prefix, který na cestu sedí, pokud k němu má handler. A pokud nic nenajde, vrátí 404. Pokud najde prefix, ale nesedí metoda, tak postupuje stejně a pokud neuspěje, vrátí 405 a v Allow seznam metod, které cestou minul.
Celé je to docela rychlé, protože se tam používá hash tabulka prefixů. Ta má lookup O(1) - proto mne zarazilo, že v jiných systémech záleží na počtu cest.
Routování lze zapojit i kaskádně, tedy samotný handler může nechat request dál routovat podle jiné tabulky, ale málokdy to je potřeba.
Kdybych měl fungovat jako třeba PHP, kdy každý script jede od nuly, tak si snad nechám někde vygenerovat statickou tabulku rout, která se prostě jen načte a použije. Ale jeden z důvodů (řekl bych ten nejzásadnější), proč nepoužívám PHP je právě tahle vlastnost.
-
V zásadě zajímavé téma o problémech, které PHP přináší. A znovu s otazníkem, zda je PHP pro větší weby dobrá varianta. Ano, izolace komponent není v zásadě špatný nápad, kromě výkonu v PHP je to spíš rozdělení na sub services (stále tedy běžící v rámci jednoho serveru).
Výkon bude záležet na tom, jak hierarchická ta struktura bude, což od jisté úrovně nejspíš přestane fungovat (typicky REST API bude na stejné struktuře a těch controllerů tam bude pro velkou aplikaci hodně).
Ohledně čísel - kdysi jsem řešil podobný problém, ani ne tak z důvodu výkonu, ale hlavně znovupoužitelnosti web komponent a jejich vnořování. Ten výkon nebyl nijak špatný. Přidal jsem ze zvědavosti ještě 1000 routes a load trvá asi 3 ms (Core i7-1185G7), včetně sestavení vyhledávacího stromu. Nicméně je to XML - dřívější testy jinde mi ukazují, že JSON je asi 5-krát rychlejší, takže se dá očekávat asi 600-800 ms na load 1000 routes. Samotný resolve nad vyhledávacím stromem zabral 171 ns / request.
Byla to tedy Java, u PHP bude logicky pomalejší. Ale to je zpět k otázce, zda vůbec volit PHP pro větší weby. Routování bude jen jedna z věcí, další problém bude třeba lokalizace, která typicky nahraje stovky záznamů a použije pár z nich (kdysi jsem ještě v PHP optimalizovat a používal BerkleyDb a podobné a nakonec se ukázalo nejrychlejší načtení všeho z CSV).
-
Nette fakt neznám, routování v Symfony vypadá docela promyšleně - prefixy, spojení do jednoho regexpu.. vážně to jde dělat výrazně lépe a je to až tolik potřeba? :)
https://blog.frankdejonge.nl/symfony-routing-performance-considerations/, https://symfony.com/blog/new-in-symfony-4-1-fastest-php-router
