Jak na databáze : 4. NF - nesouvisející relace
Datové sklady (DWH – Datawarehouse) často porušují 4. normální formu. V tabulce faktů jsou spolu uvedeny v relaci i dimenze, které spolu nesouvisí. Cílem DWH je poskytnout data v co nekratším možném čase. Jejich charakteristikou je, že data se do nich dostávají v dávkáchn do databáze.
Trochu odlišné jsou, ale relace v OLTP systémech (On Line Transaction Processing) teda v běžných databázích. Zde se snažíme obecně vyvarovat reduntacím (nadbytečným datům).
Důvodů je nekolik :
- Rýchlost zpracování
Vytvořit takovou datovou strukturu, která rychle reaguje na transakce (insert, update, delete).
- Jednoduchost změny
Vytvořit takovou datovou struktúru, která jednoduše provede změnu
- Udržení datové a refereční integrity
Vytvořit takovou datovou strukturu ve které se dá jednoduše a spolehlivě udržet integrita dat. Datové sklady, do kterých se většinou hrnou data v dávkách, nemusí se tak moc dbát na referenční integritu, protože už samotný proces přípravy dat vylučuje desintegritu dat. Proto se často nepoužívají cizí klíče, ale pouze indexy, protože to urychluje práci s daty.
Někteří vývojáři dávají přednost jednoduchosti vytvoření dotazu (select). Něco jako malý datový sklad. Pak zde vzniká kompromis, kde se běžně používají složené primarní klíče (Klíč vytvořený s více sloupců).
Abstrakce : 4. normální forma
Tabulka je v 4. NF když :
- 1. Je v 3.NF
- Tabulka neobsahuje sloupce, které mezi sebou nemají žádnou relaci.
Příklad : Datový sklad (OLAP)
Máme DWH, který zaznamenává události, které se stali na nějakém územním celku například v obci. Ale nás budou zajímat i statistiky událostí nad vyššími územními celky jako je obec s rozšířenou působností, bývalý okres a kraj. Pak nás zajímají taky zdroje informací a importní dávky ve kterých se data dostávají do databáze.
Na základě tohoto popisu, může zhotovit tuto myšlenkovou mapu.

Pokud specifikace dat územních celků je statická. Tak dynamické měnící jsou územní celek1, událost a importní dávka vázaná na zdroj informací.
Hlášení od zdroje informací by mohlo vypadat asi takto :
{"zdroj":"ZdrojA","importni_davka":"54766", [{"uzemni_celek1":"UzemniCelekDE","udalost":"UdalostCE"},{"uzemni_celek1":"UzemniCelekFE","udalost":"UdalostAE"},]}{"uzemni_celek1":"UzemniCelekGE","udalost":"UdalostCE"}
Kdybychom tvořili datový sklad, tak bychom navrhli tuto datovou strukturu :
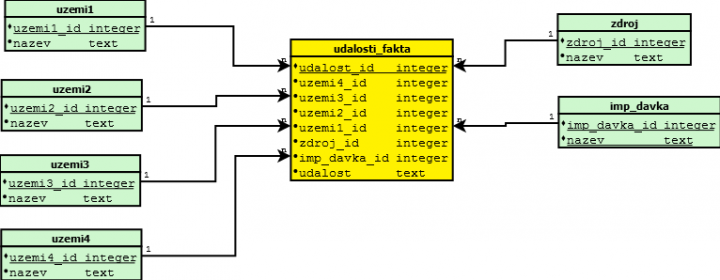
Nad tabulkou faktu jsou jednotlivé dimenze, které nemají mezi sebou žádnou relaci, protože ta je zabespečena přes tabulku faktů. Tohle je relatívně rychlá struktura, dokud potřebujeme vybírat na základě povolených kombinací mezi územím a importní dávkou a zdrojem dat. V případě, že bychom ale potřebovali vybírat povolené kombinace, tak by nám chyběli relace v rámci dimenzí. Lze toho docílit pomocí kontingenčních tabulek, ale o tom někdy příště.
Nevýhodou tohoto uspořádaní je logicky aktualizace. Z času na čas v nějakém referendu obce změní svoji příslušnost k vyššímu územnímu celku. Kdybychom zde prováděli nějaký update, tak by trval dlouho. Navíc zde neexistuje relace mezi územními celky a tak můžeme pouze ukládat data o tom, kde se vyskytla nějaká údálost. Navíc protože hlášení příchází pouze na úroveň územního_celek1, musíme mít strukturu územních celků někde jinde. Jinak řečeno skvělá datová struktura pro OLAP (On Line Analytic Processing), ale ne pro OLTP (On Line Transaction Processing).
Východiskem z nedostatků klasického Datového skladu je vytvoření vazeb mezi dimenzemi a to jak mezi územními celky, tak i mezi zdrojem dat a importní dávkou.
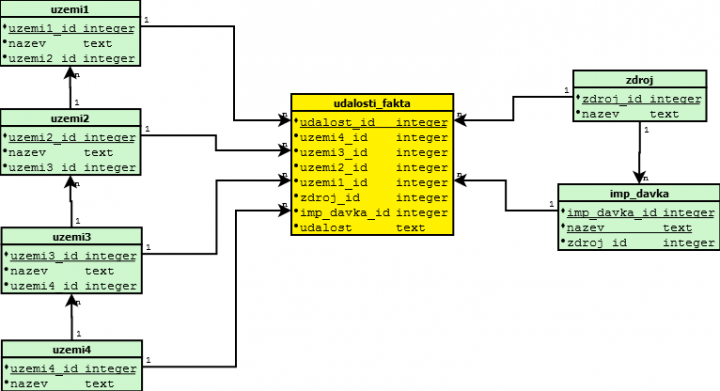
Tato struktura má celkam složitý update. Když se něco změní na straně relací mezi územními celky, musí se to změnit i mezi nimi v tabulce udalosti_fakta.
Navíc to odporuje 4. NF, protože vazba mezi územním celkem a zdrojem dat není přímá, ale přes událost. Jestli si položíme otázku na jakých uzemních celcích sleduje zdroj dat události ? Tak pomocí tohoto datového modelu dotaneme pararelace (neexistující). Ve skutečnosti máme pouze informace z jakých území přišlo hlášení událostí daného datového zdroje! Abychom dali pravdivou odpověď na tuto otázku, musíme vytvořit přímou relaci tedy tabulku mezi územními celky a zdrojem informací. Když to uděláme, tak náhodný čitatel datového modelu dostane dvě relace mezi uzemím a zdrojem dat. Samozřejmě se to dá zachránit názvem tabulky jako například sledovani_zdroj_uzemi4.
Alternativou je vytvořit datový model dle 4. NF. Ten je :
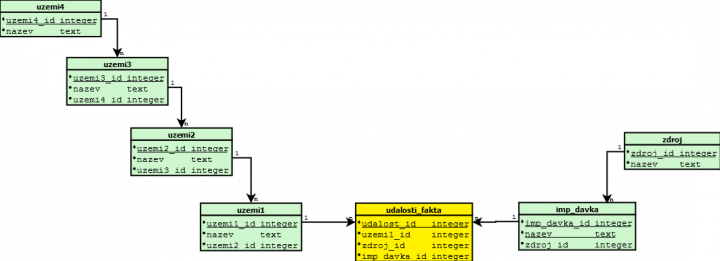
V tomto datovém modely jsou zachyceny veškeré relace tak, jaké existují. Ale lze dle nich seskládat dotazy. Navíc, jestli se některé relace změní, tak se pouze na jednom místě. Taky zde není přímá relace mezi zdrojem dat a územím.
Sémantický omyl
Můžeme být vážně spokojeny s relacemi mezi zdrojem dat – importní dávkou a importní dávkou a údálostí ? Ano, ale jen z části. Importní dávka je v kategorii provozování databáze. Takže obecně importní dávku budeme mít zahrnuta v každé databázi, kde budeme importovat dat. Ale událost a zdroj_dat tvoří jádro databáze, které je sice v této databáze závisle na této konkrétní importní dávce, ale v jiné může být závislé na jiném mechanizmu, jak dostávat data do databáze. Proto musí existovat vazba i mezi událostí a zdrojem dat. O tom ale příště v 5. NF.
Žádné názory
