Jak na databáze 5.NF - cross join relací
V příspěvku o 4.NF jsem se dostali k datovému modelu, kde jsem sémanticky (na základě znalostí dat ) přišli k závěru, že je nezbytné mít vazbu mezí zdrojem dat a registovanými událostmi nad územím. 5. normální forma nám dává návod jak zabespečit relace v tomto případě.
P.S. Všimli jste si že poslední 2 normální formy nejsou pouze o syntaxi, ale hlavně o sématice – znalostech dat ?
Abstrakce : 5. normální forma
Tabulka je v 5. NF když :
- Je v 4.NF
- Tabulka neobsahuje sloupce, které mezi sebou nemají vícenásobné relace
Příklad:
Cílem 4. a 5. normální formy je o tom, jak redukovat nadbytečná (reduntatní) data, které mohou vzniknoutat tehdy, když ukládame relační data do jedné tabulky.
Asi nejlepší příklad bude, když to vysvětlím abstraktně.
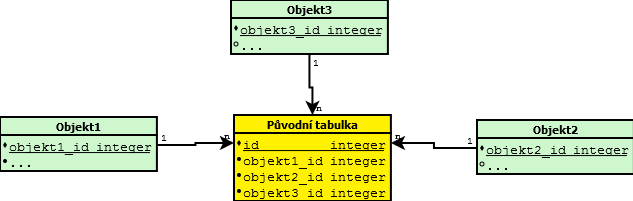
Původní tabulka v sobě obsahuje identifikátory 3 objektů. Ze sémantiky (charakteru dat) víme, že nejen relace objekt1-objekt2-objekt3 dává smysl, ale že každé dva objekjty mezi sebou tvoří relaci nezávisle na třetím objektu. A tedy, že Původní tabulka obsahuje redundatní (nadbytečná – duplicitní data) data. Počet záznamů můžeme redukovat a tím zvýšit efektívnot zpracování tak, že namísto jedné spojovací tabulky, vytvoříme 3, tedy cross join.
Pozór: Coss join jsi můžeme dovolit pouze tehdy, jestli skutečně platí, že „Každý s každým“. Jestli ne, tak dostaneme falešná data !
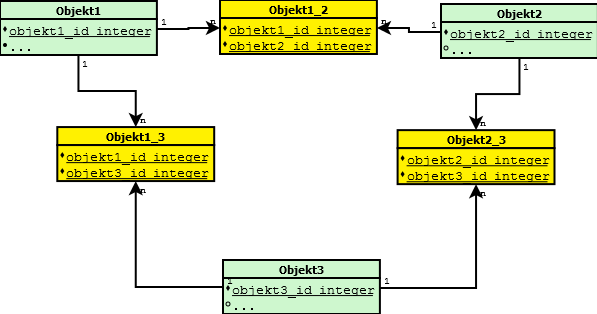
Složitější příklad :
Začneme tam, kde jsme skončili u 4.NF.
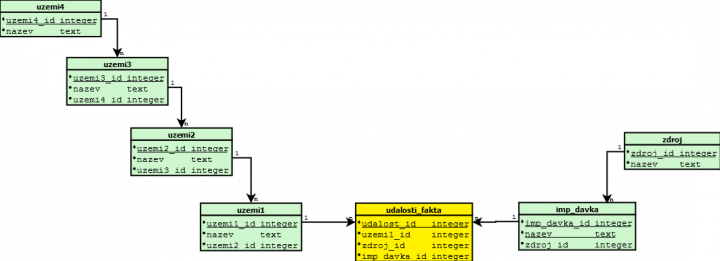
Z našich znalosti, vyplývá, že musíme zabespečit relace mezi uzemím – událostí, událostí – importní dávkou, impotní dávkou – zdrojem dat a zdrojem_dat-událostí.Nejjednoduchší je sestavit datový model asi takto: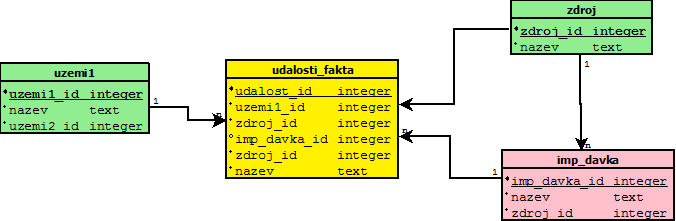
Zdroj dat přidáme k tabulce udalosti_fakta. Tato tabulka ale není v 4.NF, protože obsahuje ve svích sloupcích multihodnotové relace. Základní informační jednotkou je zde relace uzemi1_id a udalost_id. K ní přistupuje importní dávka a skupinu tvoří imp_davka_id, uzemi1_id,udalost_id. Skupina je Importní skupina. Druhou skupinu tvoří zdroj_id, uzemi1_id,udalost_id. Skupina je Obsahová skupina.
To nás vede k tomu, že „události-fakta“ rozbijeme do tabulek „udalosti-uzemi“ a „udalosti-zdroj“ a „Tabulka“.
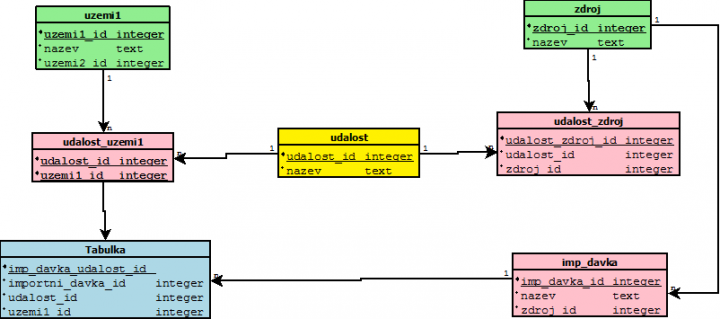
Referenční integritu pak dokážeme zabespečit tím, že například, jestli v tabulce udalost-zdroj potřebujeme, aby jedna událost byla registrovaná pouze jedným zdrojem. Tak nad udalost_id dáme jedinenčný klíč. Obdobně i nad tabulkou udalost_uzemi1.
Závěrem :
Tak snad jsem dostatečně vysvětlil, jaký já chápu 5. normální formu. Když rekapituji dosavadní probrané normální formy db, Tak
- 1. je o atomičnosti
- 2. o referenční integritě
- 3. o redukci nadbytečných popisných dat
- 4. o redukci nadbytečných nerelačních referenčních dat a
- 5. o redukci nadbytečných relačních referenčních dat.
Zůstavá nám jedna oficiální 6.NF a 7.NF (neoficální). Na rozdíl od předchozích forem tyhle se zabývají případy jak předcházet anomalitám vhodným návrhem datových struktur.
6. NF forma mluví o insert a delete anomalitě a 7.NF (můj příspěvěk do normalizace) o update anomalitě. Ale teď se na měsíc odmlčím to víte prázdniny. :)
Žádné názory





















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU