Jak na databáze: 2.NF - Číselníky
Klíčovým prvkem snad každého informačního systénu jsou číselníky. Číselníky jsou tabulky, které obvykle na základě svého primárního klíče identifikují určité skutečnosti (typy objektů, popisní ,nebo řídící data…).
Pamatuji na dobu, kdy číselníky byly skutečně číselníky. Jednak odkazovali na určité atributy, které se dále používali a jednak šetřili místo, protože namísto popisných údajů používali číslo.
Doba se změnila a identifikace číselníku výhradně podle čísla je již za námi. V angličtině se potkáte s názvem lookup table. Jenomže to čemu říkame číselníky má i hlubší rozsah a zasahuje do jádra relačních systémů - Referenční integrity.
Abstrakce: 2. normální forma
Tabulka je v 2.NF když :
- 1. Je v 1. NF.
- Tabulka neobsahuje významové sloupce u kterých hodnoty se opakují ve více řádcích.
Poznámka :
Mohl jsem si hrát na odborníka a zformalizovat to tak, aby to hned nebylo jasné. Ale myšlení v relačním světě není tak složité abychom na to potřebovali složité definice pomocí superklíčů, kandidatních klíčů … Možná to znáte připravíte si dokonalou teorií a začnete ji vysvětlovat. Během přednášky je ticho, když se zeptáte na otázky je ticho. A když to vysvětlíte jednoduše, tak se ozve „Ach tak, to si měl říci hned …“
Příklad Dodržíme syntax
Máme klasický kartoteční lístek v knihovni, kde ještě nedorazila výpočetní technika. Nebo raději převedeno na dnešní dobu, máme účet od nákupu. Jsme pragmatický a zapisujeme si nákup do databáze asi takto :
| Den | Obchod | Položka | Množství | mj | Jednotková_cena | Cena celkem |
| 1.6.2016 | Lidl | rohlík | 3 | množ | 1.50 | 4.50 |
| 1.6.2016 | Lidl | jogurt | 1 | množ | 8.00 | 8.00 |
| 1.6.2016 | Lidl | ředvičky | 1 | svazek | 4.50 | 4.50 |
| 2.6.2016 | Billa | rohlík | 3 | množ | 2.00 | 6.00 |
| 2.6.2016 | Billa | jogurt | 1 | množ | 6.50 | 6.50 |
| 2.6.2016 | Billa | jablka | 0.5 | kg | 25 | 12,50 |
| 3.6.2016 | Lidl | rohlík | 3 | množ | 1.50 | 4.50 |
| 3.6.2016 | Lidl | jogurt | 1 | množ | 7.00 | 7.00 |
| 3.6.2016 | Lidl | hrozny | 0.25 | kg | 45 | 11.22 |
Tak, vytvořili jsem tabulku a naplnili daty. Víme, že je v 1.NF. Ale taky vidíme, že určité významové sloupce obsahují hodnoty, které se opakují. A to pro obchod, položku a měrnou jednotku. Ale abychom mohli srovnávat a dělat různé statistiky musíme zabespečit, aby tyto hodnoty byly stejné tak např: obchod může být Lidl, ale taky lidl, nebo Lidl Slatina. Množství může být množ, ale taky množství, mn. atd.
Proto namísto jednoduché jedné tabulky, vytvoříme hned 4. nakup, obchod, zbozi a merna_jednotka. Obchod, zbozi, merna_jednoka jsou tzv. číselníky. Ty hlídají aby hodnoty nabývali v tabulce nakup pouze určité hodnoty. V RDBMS (relational database management system) se to zabespečuje pomocí cizích klíčů (foreign key) a povolení hodnoty null, nebo její zakázaní u hlídaného sloupce.
Proto namísto jednoduché jedné tabulky, vytvoříme hned 4: nakup, obchod, zbozi a merna_jednotka. Obchod, zbozi, merna_jednoka jsou tzv. číselníky. Ty hlídají aby hodnoty nabývali v tabulce nakup pouze určité hodnoty. V RDBMS (relational database management system) se to zabespečuje pomocí cizích klíčů (foreign key) a povolení hodnoty null, nebo její zakázaní u hlídaného sloupce.
Magická hodnota null.
Hodnotou null (prázdná hodnota) stanovujeme, jestli se hodnota u daného sloupce musí zadat nebo ne. A v našem případě jestli hodnota je null nebo odpovídá hodnotě z číselnku.
Klasickým příkladem může být, když se vyplňuje nejaký formulář a ukládá se do databáze jako nevyplněný.
Jestli pracujete s číselníky, doporučují nezařazovat klíčové slovo nevyplněno, nebo nezadáno do číselníků. Odporuje to 1. NF, kde v sloupci by mněl být pouze jeden typ dat. Kdyby jsme to použili například u obchodů, tak v seznamu obchodů by nám figuroval jeden obchod Nevyplněno. Na to máme hodnotu null.
Pro ty, kteří nemají zkušenosti z příkazem select, tak pro výběr hodnot s null hodnotou použijte left join vazbu tabulek.
Poznámka:
A aby nebylo vše tak jednoduché, používá se v číselnících slovo nezadáno v dimenzích pro datový sklad, kde má určitý klíčový význam pro výběr dat. Často potřebujeme vybrat i data, která nemají zařazenou žádnou hodnotu dimenze. A abych pak nedělali zvláštní dotaz typu … is null, vytvoříme zvláštní hodnotu, kterou pak použijeme v číselníku – dimenzi.
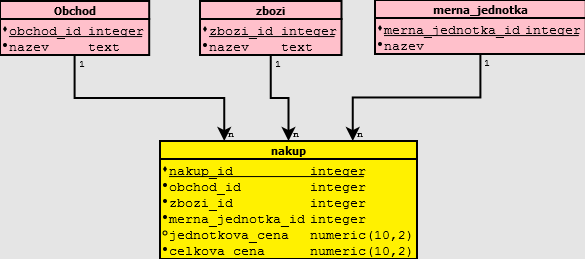
Zde je zdrojový kód, který si můžete vyzkoušet v PostgreSQL.
CREATE TABLE obchod(
obchod_id SERIAL PRIMARY KEY,
nazev TEXT NOT NULL
);
CREATE TABLE polozka(
polozka_id SERIAL PRIMARY KEY,
nazev TEXT NOT NULL
);
CREATE TABLE merna_jednotka(
merna_jednotka_id SERIAL PRIMARY KEY,
nazev TEXT NOT NULL
);
CREATE TABLE nakup (
nakup_id SERIAL PRIMARY KEY,
den DATE NOT NULL,
obchod_id INTEGER NOT NULL REFERENCES obchod,
polozka_id INTEGER NOT NULL REFERENCES polozka,
mnozstvi NUMERIC(6,2) NOT NULL,
merna_jednotka_id INTEGER NOT NULL REFERENCES merna_jednotka,
cena_jednotka NUMERIC(12,2) NOT NULL,
cena_celkem NUMERIC(12,2) NOT NULL,
CONSTRAINT uk_nakup UNIQUE (den,obchod_id,polozka_id)
);
-- Priklad vyberu dat
select
a.nakup_id,a.den,b.nazev as obchod,d.nazev as polozka,a.mnozstvi,c.nazev as merna_jednotka,cena_jednotka,cena_celkem
from nakup a
left join obchod b on a.obchod_id = b.obchod_id
left join merna_jednotka c on a.merna_jednotka_id = c.merna_jednotka_id
left join polozka d on a.polozka_id = d.polozka_id; A co sémantika ?
Sémanticky nemáme tak docela pravdu z předchozím příkladem.
K jogurtu můžeme přiřadit svazek, k rohlíkům kg. Aby tomu tak nebylo musíme zabespečit 2.NF pomocí refrenční integrity takto :
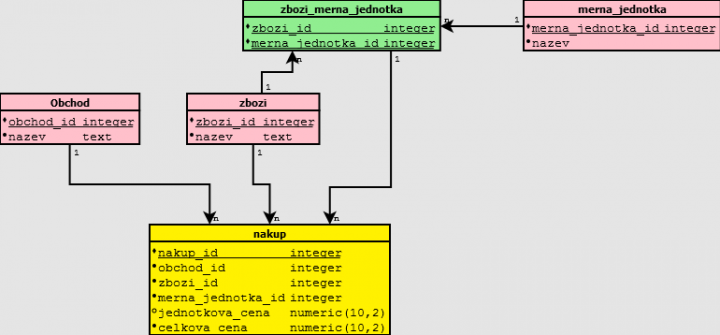
Vytvoříme vazební tabulku mezi měrnou jednotkou a zbožím. Tedy k zboží přidáme ty měrné jednotky které k ní jsou povoleny. A navíc zabespečíme, aby kombinace zboží a měrná jednotka byly validní pomocí refereční integrity.
Zde je změnový script:
-- Zruseni puvodniho ciziho klice (Neni nezbytne nutne)
ALTER TABLE public.nakup DROP CONSTRAINT nakup_merna_jednotka_id_fkey;
drop table polozka_merna_jednotka cascade;
-- Vytvoreni vazebni tabulky
CREATE TABLE polozka_merna_jednotka
(polozka_id integer not null references polozka,
merna_jednotka_id integer not null references merna_jednotka,
constraint pk_polozka_merna_jednotka primary key (polozka_id,merna_jednotka_id));
-- Zmena v tabulce nakup
ALTER TABLE nakup ADD CONSTRAINT fk_nakup_zbozi_merna_jednotka foreign key (polozka_id,merna_jednotka_id)
references polozka_merna_jednotka(polozka_id,merna_jednotka_id); Sémantické pravidlo pro použití 2. NF :
Tabulka je v 2. NF právě když je zabespečena datová integrita kombinací hodnot všech cizích klíčů.
Jedna zvláštnost Kaskádní číselníky – paralelně
Zvláštní kategorii jsou kaskádní číselníky. To jsou číselníky, kdy hodnota v jednom číselníku závisí od hodnot v druhém číselníku. Takovými číselníky jsou například územní celky, nebo řády povodí.
Problém ale nastává když chcete v tabulce zahrout data z různých úrovni kaskády tzv. paralelní použítí kaskádního číselníku. Například hlášení vyjmečných události se může vztahovat ke kraji, nebo okresu, nebo katastrálnímu území. Tak do tabulky umístnite sloupce pro veškeré klíče kaskády. To je OK. Ale jak mezi nimi zabespečit datovou integritu ? Např: Aby jsme mezi Středočeský kraj neumístnili Brno ? A současně potřebujeme mít hlášení i pro celý kraj.
Jednoduše.

Každý číselník 2. a vyšší úrovně obsahuje kromě primárního klíče taky jedinečný klíč, který se skládá z jedinečného klíče předchozí úrovně a primárního klíče dané úrovně. Pak pomocí těchto jedinečných klíčů je zabespečena i refereční integrita na základní tabulku. Zde je kod pro PostgreSQL :
create table kc1
(kc1_id serial primary key,
txt text not null);
create table kc2
(kc2_id serial primary key,
kc1_id integer references kc1,
txt text not null,
constraint uk_kc2 unique(kc1_id,kc2_id));
create table kc3
(kc3_id serial primary key,
kc1_id integer not null,
kc2_id integer not null,
txt text not null,
constraint uk_kc3 unique (kc1_id,kc2_id,kc3_id),
constraint fk_ukc3 foreign key (kc1_id,kc2_id) references kc2(kc1_id,kc2_id)
);
create table base_table(
base_table_id serial primary key,
txt text not null,
kc1_id integer not null,
kc2_id integer,
kc3_id integer,
constraint uk_base_table_kc1 foreign key (kc1_id) references kc1(kc1_id),
constraint uk_base_table_kc2 foreign key (kc1_id,kc2_id) references kc2(kc1_id, kc2_id),
constraint uk_base_table_kc3 foreign key (kc1_id,kc2_id,kc3_id) references kc3(kc1_id,kc2_id,kc3_id)
); Na závěr k diskusi :
Moc se omlouvám vše těm, kdo chtějí diskutovat. Mylně jsem se domníval, že se povede věcná diskuse k problematice, ale osobní injektívy, které nemají nic spoločné s inženýringem mě vedli k tomu, že jsem diskusi zakázal. Čas redikovat diskusi bohužel nemám. Děkuji za pochopení






















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU